# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
端到端变奏,后发者的机会更少了。
像海鲜市场一样,智能驾驶行业技术浪潮正在快速更迭。“端到端”刚成为新的技术范式,甚至大量公司还没来得及完成研发模式切换,端到端就进入了技术换代时期。
“端到端”的最新进化方向是,深度融入多模态大模型。过去两年,大模型已经展现出了读文、识图、拍电影的能力,但大模型开车恐怕还是头一遭。
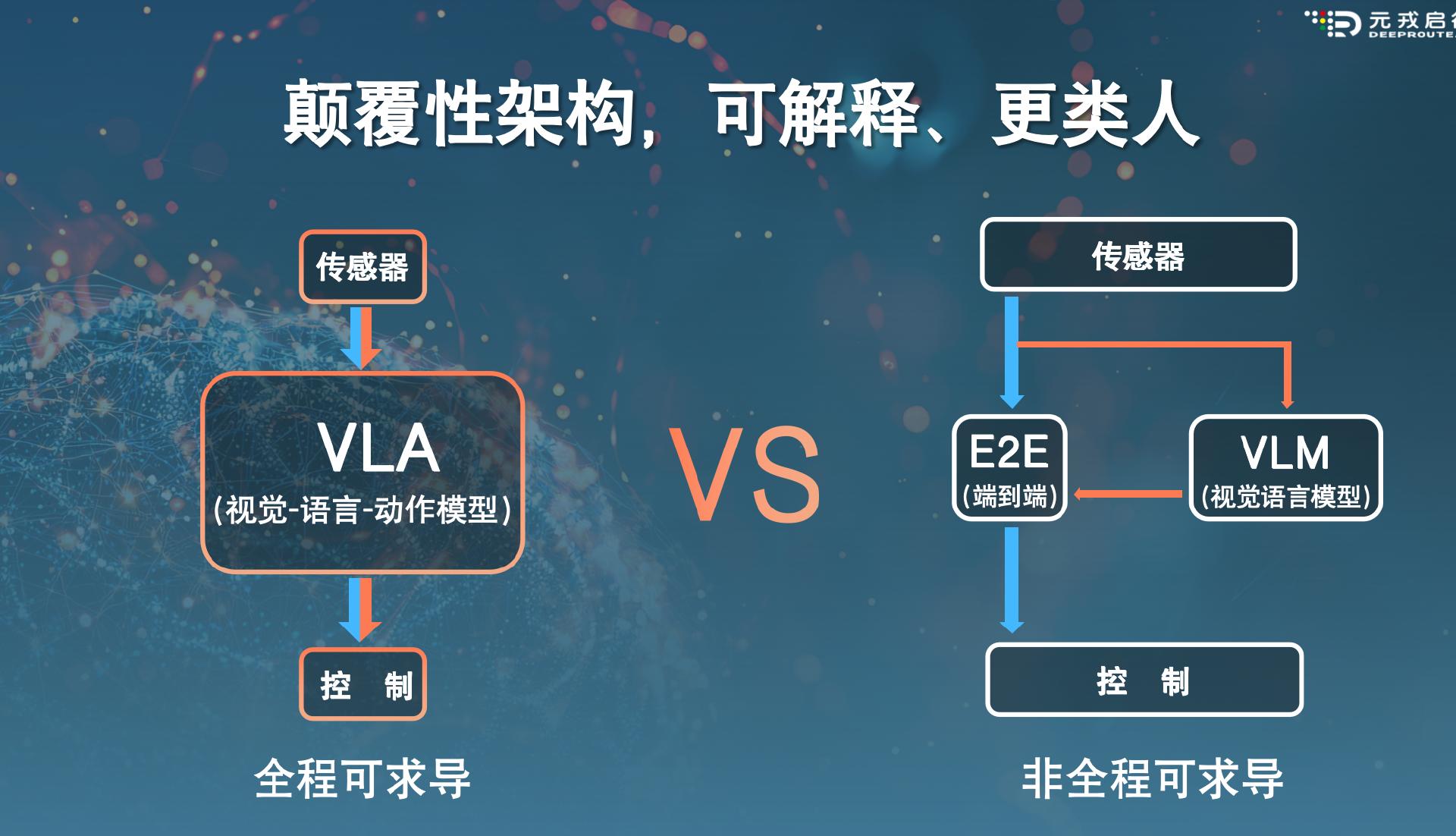
近期,智驾行业出现了一个融合了视觉、语言和动作的多模态大模型范式——VLA(Vision-Language-Action Model,即视觉-语言-动作模型),拥有更高的场景推理能力与泛化能力。不少智驾人士都将VLA视为当下“端到端”方案的2.0版本。
事实上,VLA模型最早见于机器人行业。2023年7月28日,谷歌 DeepMind推出了全球首个控制机器人的视觉语言动作(VLA)模型。
不过这个模型概念正快速扩散到智驾领域。今年10月底,谷歌旗下自动驾驶公司Waymo推出了一个基于端到端的自动驾驶多模态模型EMMA。有行业人士表示,这就是一个VLA模型架构,既有端到端智驾能力,还融合了多模态大模型。
过去,智能驾驶行业基于规则算法,进行了十数年探索。近两年,特斯拉引领的“端到端”智能驾驶,成为新的技术方向,不仅让智驾具备更拟人的表现,也能应对城市中海量的复杂交通场景。
配合“端到端”技术,行业玩家还会增加大语言模型等来提升智驾能力上限。端到端+VLM(视觉语言模型),就被理想等公司推崇。
但不同于VLM相对独立、低频地为端到端提供驾驶建议的模式,VLA架构下,端到端与多模态大模型的结合会更彻底。就连理想人士也向36氪汽车坦承,“可以把VLA看成是端到端+VLM的合体。”
VLA模型,很可能是“端到端+VLM”技术框架的“终结者”。
有行业人士表示,VLA模型对智驾的演进意义重大,让端到端理解世界的能力更强后,“长远来看,在L2辅助驾驶到L4自动驾驶的飞跃中,VLA可能会成为关键跳板”。
一些车企智驾玩家已经在暗自发力。此前,理想汽车曾在三季度财报电话会议上表示,内部已经启动了L4级别自动驾驶的预研,在当前的技术路线基础上,研发能力更强的车端VLA模型与云端世界模型相结合的强化学习体系。
智驾公司元戎启行在获得长城汽车的7亿元注资之后,也表示将进一步布局VLA模型。元戎启行称,公司将基于英伟达最新智驾芯片Thor进行VLA模型研发,模型预计于2025年推出。
但也存有共识,VLA模型的上车难度不小,对技术和车端的芯片算力都有高强度要求,“能够支持VLA模型上车交付的芯片,可能在2026年才会出现。”
自2023年以来智驾行业掀起的BEV、端到端技术浪潮后,智驾正逐步将AI神经网络融入感知、规划、控制等环节。比起传统基于规则的方案,基于AI、数据驱动的“端到端”拥有更高能力天花板。
图源:元戎启行
但在“端到端”模型之外,车企们还辅以了大语言模、视觉语言模型等外挂,来提供更强大的环境理解能力。年中,理想就推出了端到端模型+VLM(视觉语言模型)的方案。VLM模型对复杂交通环境具有更强的理解能力,可以给端到端提供相关驾驶建议。
不过据36氪汽车了解,理想的端到端模型+VLM模型,是相对独立的两个模型。“理想VLM占用了一颗Ori芯片算力,目前主要对限速提醒等场景做出驾驶建议。”
而VLA模型,是将端到端、VLM两个模型合二为一。也就是说,多模态大模型不再作为端到端的外挂,而是成为端到端自生的一种能力。
谷歌Waymo近期发表的论文中,端到端自动驾驶多模态模型,不仅将摄像头的视频和图像作为感知输入,同时还能以谷歌地图“请在前方第二个匝道右转出匝道”这种指令作为输入,以及结合车辆历史状态,输出车辆未来轨迹。
有行业人士向36氪汽车表示,目前对于一些特殊的复杂场景,智驾仍然缺少学习数据样本。如果融入模态大模型,就能将大模型学习到的知识迁移给智驾系统,可以有效应对corner case(长尾场景)。
智驾公司元戎启行CEO周光也认为,VLA模型是端到端的2.0版本。他表示,遇到一些复杂的交通规则、潮汐车道、长时序推理等特殊场景时,智驾会比过往理解、应对得更好。
比如在推理时长上,传统rule-base(基于规则)方案下,智驾只能推理1秒钟路况信息然后做出决策控制;端到端1.0阶段系统能够推理出未来7秒路况,而VLA能对几十秒路况进行推理。
“目前基本上大家沿着这条线已经预研1年多了,不过明年想要量产还是有很大难度。”有行业人士表示。
在进入规模推广之前,下一代端到端方案还面临很现实的挑战。
一方面,现阶段车端芯片硬件不足以支撑多模态大模型的部署落地。有行业人士向36氪汽车表示,将端到端与VLM模型二合一后,车端模型参数变得更大,既要有高效实时推理能力,同时还要有大模型认识复杂世界并给出建议的能力,对车端芯片硬件有相当高要求。
当下,高阶智驾的算力硬件基本为2颗英伟达OrinX芯片,算力在508Tops。有行业人士表示,现在车端的算力很难支撑VLA模型的部署。
而英伟达的最新一代车载AI芯片Thor有望改变这种局面,Thor的单片AI算力达1000Tops,并对AI、大模型等算力都有不错支持。
不过跟英伟达接触的人士向36氪汽车表示,明年英伟达Thor芯片大概会延期发布,上半年最先有望先推出的是700Tops算力版本。但一颗700Tops算力的芯片也可能支撑不了VLA模型,两片Thor的成本又高出不少。
英伟达的芯片量产时间与成本挑战,横亘在车企前面。为此,一些自研芯片的新势力也在紧追芯片进度。据36氪汽车了解,一家头部新势力的VLA模型预计2026年正式上车。“届时结合自研的大算力芯片,VLA的效果会更惊艳。”上述行业人士表示。
好在,VLA模型架构下,数据方面的挑战没有骤然提升。
有行业人士告诉36氪,在端到端基础上,VLA模型融入了视觉语言模型、动作模型。但多模态大模型的数据并不难获得,包括已经开源的大模型、互联网上已有的通用语言,都可能成为智驾多模态大模型的养料。
更具挑战的是,如何将端到端与多模态大模型的数据与信息作深度交融。这考验着头部智驾团队的模型框架定义能力、模型快速迭代能力。
这些都决定了VLA模型不会太快进入智驾的量产环节。
然而,技术路线的骤然升级与竞赛变奏,为还没发力端到端的玩家设置了更高门槛,后发制人的机会更加稀少。
文章来自于“36氪”,作者“李安琪”