# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
空间智能版ImageNet来了,来自斯坦福李飞飞吴佳俊团队!
HourVideo,一个用于评估多模态模型对长达一小时视频理解能力的基准数据集,包含多种任务。
通过与现有模型对比,揭示当前模型在长视频理解上与人类水平的差距。

2009年,李飞飞团队在CVPR上首次对外展示了图像识别数据集ImageNet,它的出现极大推动计算机视觉算法的发展——懂CV的都是知道这里面的门道有多深。
现在,随着多模态迅猛发展,团队认为“现有的视频基准测试,大多集中在特定领域或短视频上”,并且“这些数据集的平均视频长度较短,限制了对长视频理解能力的全面评估”。
于是,空间智能版ImageNet应运而生。
HourVideo包含500个来自Ego4D数据集的第一人称视角视频,时长在20到120分钟之间,涉及77种日常活动。
评测结果表示,人类专家水平显著优于目前长上下文多模态模型中最厉害的Gemini Pro 1.5(85.0%对37.3%)。
在多模态能力上,大模型们还任重而道远。
之所以提出HourVideo,是因为研究人员发现目前长视频理解越来越重要,而现有评估benchmark存在不足。
多模态越来越卷,人们期待AI被赋予autonomous agents的类似能力;而从人类角度来看,由于人类具备处理长时间视觉处理的能力,因此能在现实视觉中感知、计划和行动。
因此,长视频理解对实现这一目标至关重要。
而当前的多模态评估benchmark,主要还是集中在评测单张图像或短视频片段(几秒到三分钟),对长视频理解的探索还有待开发。
不可否认的是,AI评估长视频理解面临诸多挑战,譬如要设计任务、避免通过先验知识或简短片断回答等。
因此,团队提出HourVideo。
这是一个为长视频理解而设计的基准数据集。
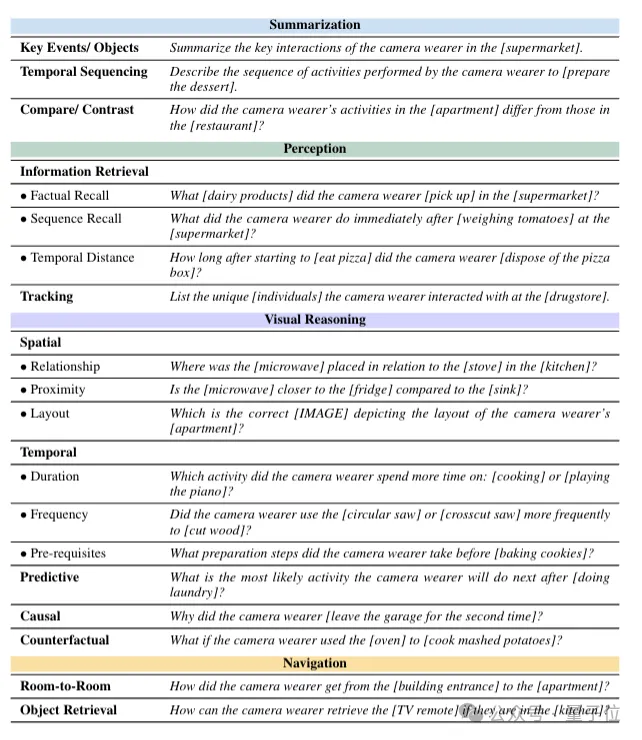
为了设计出需要长期理解的任务,团队首先提出了一个新的任务对应套件,包含总结、感知(回忆、跟踪)、视觉推理(空间、时间、预测、因果、反事实)和导航(房间到房间、对象检索)任务,共18个子任务。
其中,总结任务要求模型对视频中的关键事件、主要交互等进行概括性描述,例如总结出脖子上挂了个相机的人在超市中有什么关键交互行为。

感知任务由两部分构成,
一个是回忆任务,包括事实回忆(比如脖子上挂了个相机的人,在超市拿起的乳制品)和序列回忆(比如那个人在超市称完西红柿过后做了什么),以及对时间距离的判断(比如吃了多久的披萨才扔掉盒子)。
还有一个是跟踪任务,主要用来识别脖子上挂了个相机的人在特定场景(比如超市、药店)中互动的独特个体。
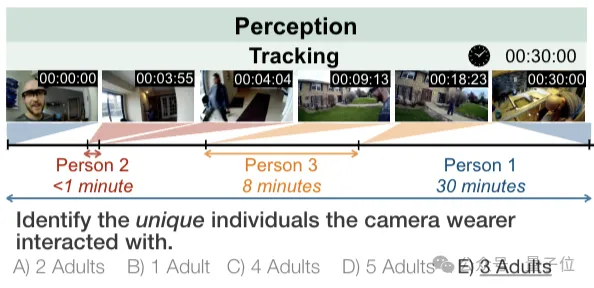
接下来是视觉推理任务,分为空间推理和时间推理。
空间推理负责判断物体之间的空间关系、空间接近度(如微波炉与冰箱或水槽相比是否更近)以及空间布局(如选择正确描绘脖子上挂相机的人的公寓的布局图)。
时间推理则包括对活动持续时间的比较、事件发生频率的判断、活动的先决条件、预测(如洗完衣服后最可能做的活动)、因果关系(如第二次离开车库的原因)以及反事实推理(如用烤箱做土豆泥会怎样)。
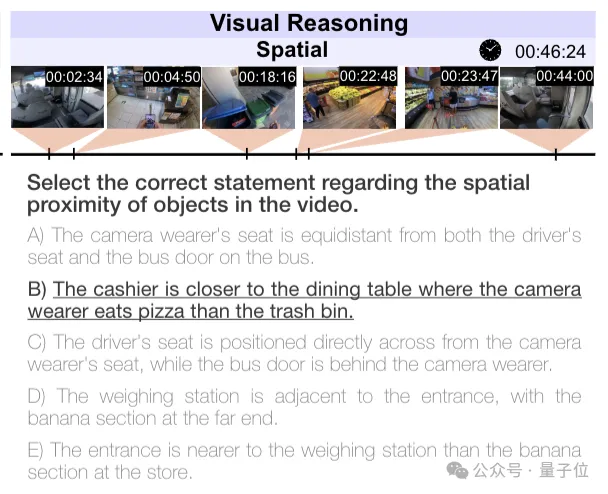
导航任务包含了房间到房间的导航、对象检索导航。
以上每个任务有精心设计的问题原型,以确保正确回答问题需要对长视频中的多个时间片段进行信息识别和综合,从而有效测试模型的长期理解能力。
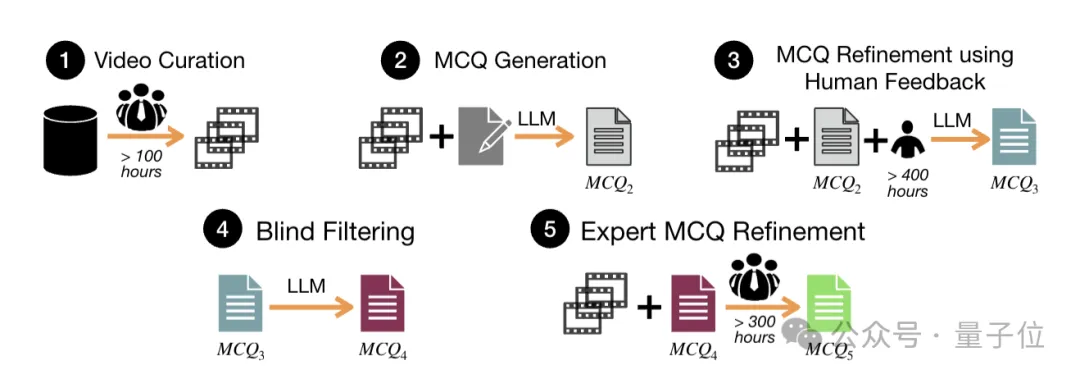
与此同时,研究人员通过pipeline来生成了HourVideo数据集。
第一步,视频筛选。
团队从Ego4D数据集中手动审核1470个20到120分钟的视频,让5位人类专家选择了其中500个视频,
至于为啥要从Ego4D中选呢,一来是其以自我为中心的视角与autonomous agents和助手的典型视觉输入非常一致;二来是它具有广泛的视觉叙述,有助于创建多样化的题;三来Ego4D的访问许可非常友好。
第二步,候选MCQ生成。
这需要在长视频中跨多个时间片段,进行信息分析和合成。
具体来说,研究人员以20分钟为间隔分割了视频,提取信息转化为结构化格式供大模型处理。最终一共开发了25个特定任务的prompts。
第三步,LLM优化与人工反馈。
在这个阶段,团队实现了一个人工反馈系统,7名经验丰富的人员人工评估每个问题的有效性、答案准确性、错误选项合理性。最终收集了400多个小时的人工反馈,然后设计prompt,自动优化 MCQ₂得到 MCQ₃。
第四步,盲选。
这一阶段的目标是消除可以通过大模型先验知识的问题,或者消除那些可以在不用视频中任何信息就可以回答的问题。
团队用两个独立的大模型——GPT-4-turbo和GPT-4,对MCQ₃进行盲筛,确保剩余 MCQ₄高质量且专门测试长视频语言理解。
第五步也是最后一步,专家优化。
这一步是用来提升MCQ₄质量,将宽泛问题精确化,经此阶段得到高质量 MCQ₅。
4个专家干的事be like,把 “挂着相机的人把钥匙放在哪里了?” 精确成“挂着相机的人购物回家后,把自行车钥匙放在哪里了?”
如上pipeline中,研究图纳队使用了GPT-4来遵循复杂的多步骤指令,同时还使用了CoT提示策略。
此外,pipeline中涉及大模型的所有阶段的问题被设为0.1。
据统计,HourVideo涵盖77种日常生活场景,包含500个Ego4D视频,视频时长共381个小时、平均时长45.7分钟,其中113个视频时长超过1小时。
每个视频有约26个高质量五选一题,共计12976个问题。
除因果、反事实和导航任务外,问题在任务套件中均匀分布。
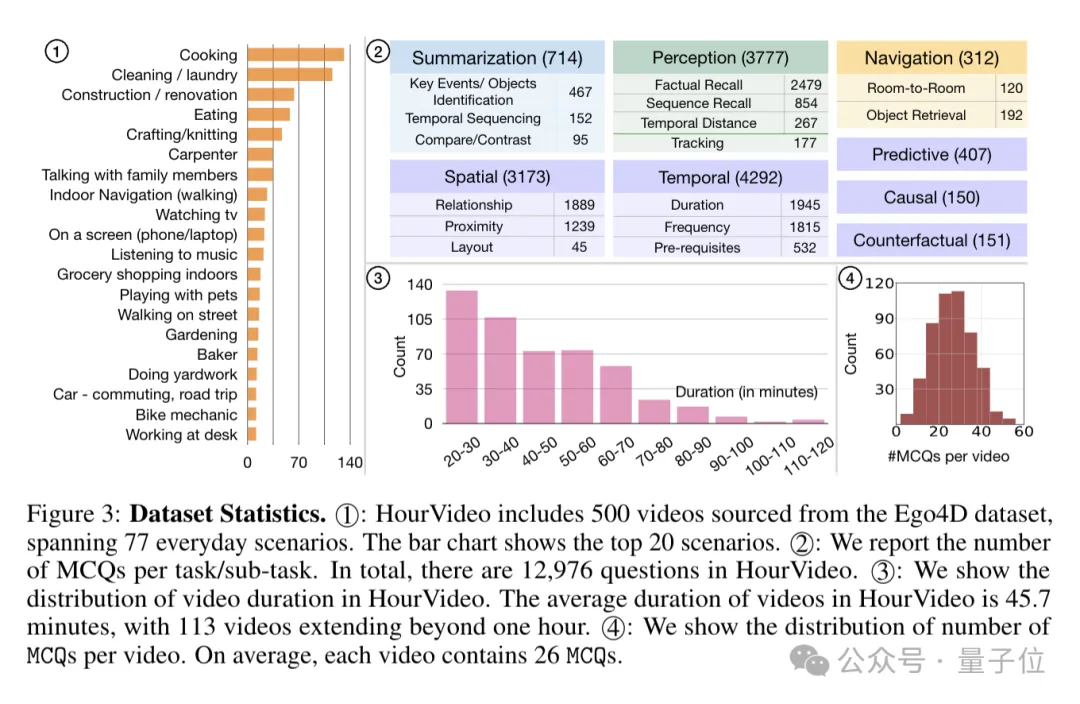
在实验评估方面,HourVideo采用五选多任务问答(MCQ) 任务,以准确率作为评估指标,分别报告每个任务以及整个数据集的准确率。
由于防止信息泄露是评估长视频中的MCQ时的一个重要挑战——理想情况下,每个MCQ应独立评估,但这种方法计算成本巨高,且十分耗时。
因此,实际评估中按任务或子任务对问题进行分批评估,对于预测任务,提供精确的时间戳以便对视频进行有针对性的剪辑,从而平衡计算成本和评估准确性。
研究团队比较了不同的多模态模型在零镜头设置下理解长视频的性能。
主要评估了三类模型,所有这些模型都在一个通用函数下运行:
盲LLM:
指是指在评估过程中,不考虑视频内容,仅依靠自身预先训练的知识来回答问题的大型语言模型。
实验中以GPT-4为代表。它的存在可以揭示模型在多大程度上依赖于其预训练知识,而不是对视频中实际视觉信息的理解。
苏格拉底模型:
对于大多数当前的多模态模型,直接处理非常长的视频存在困难。
因此,采用Socratic模型方法,将视频(总时长为t分钟)分割成1分钟的间隔,每个间隔独立加字幕,然后将这些字幕聚合形成一个全面的基于语言的视频表示,并与通用任务无关的提示一起作为输入进行长视频问答。
实验中分别使用GPT-4和LLaVA- NEXT-34-DPO 为视频字幕生成器,并最终使用GPT-4进行实际问题回答。
原生多模态模型:
像Gemini 1.5 Pro这样的原生多模态模型,在多模态数据(包括音频、视频、图像和文本)上联合训练,能够处理非常长的上下文长度*((2M +),适合直接对HourVideo进行端到端评估。
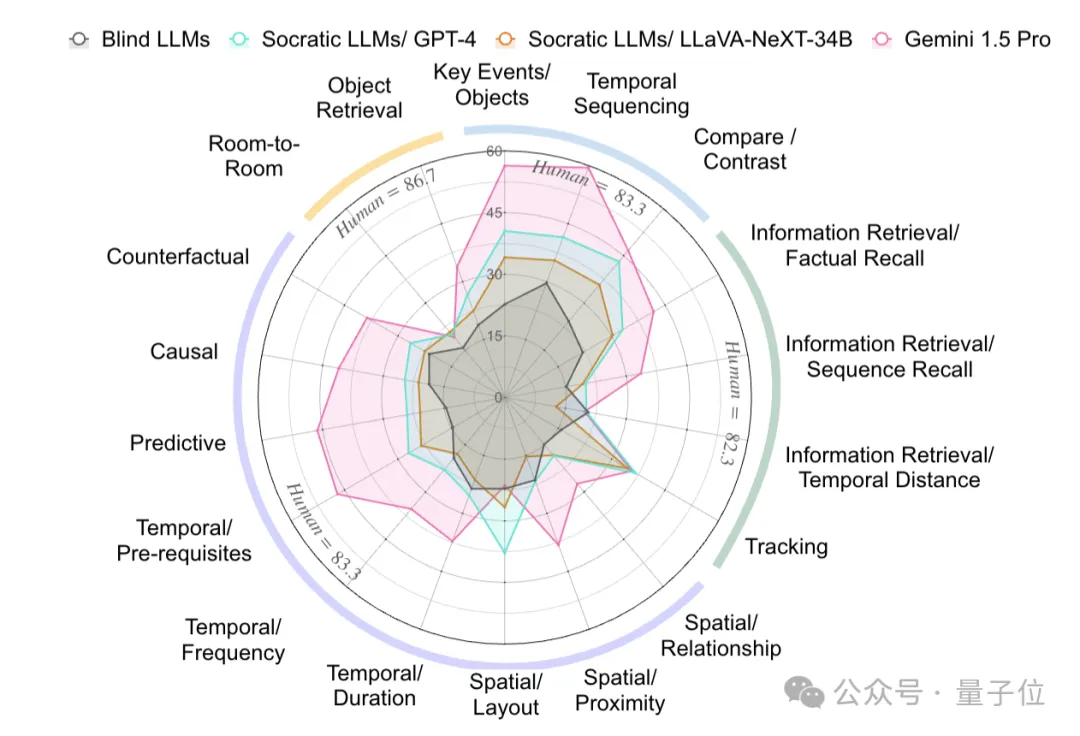
为了与模型性能进行对比,实验人员从基准数据集中选取了14个视频,涵盖>18种场景,包括手工制作/绘画、烹饪、建筑/装修、园艺、清洁/洗衣和庭院工作等。
然后邀请了3位人类专家,对上述总时长11.2小时的视频内容进行进行评估,共涉及213个MCQ。
为确保评估的公正性,参与评估的人类专家未参与过这些视频的早期注释工作。
最终,人类专家在评估中的准确率达到了85.0% 。
而盲LLM的准确率为19.6%,Socratic模型准确率略高,原生多模态模型准确率最高,达到了37.3%,仍然远低于人类专家水平。
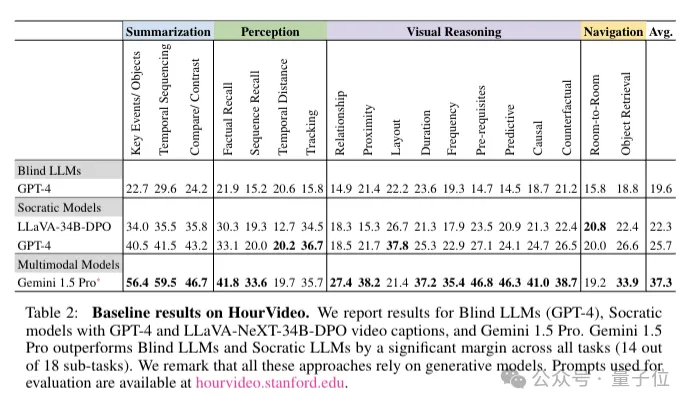
此外,独立评估每个MCQ与按任务级别评估相比,性能下降2.1%,但成本增加3倍以上,证明了任务级评估方法的效率和有效性。
最后,团队表示未来计划扩展基准测试,包括更多样化的视频来源(如体育和YouTube视频),纳入音频模态支持,并探索其他感官模态。
同时强调在开发模型时需考虑隐私、伦理等问题。
HourVideo项目来自斯坦福李飞飞和吴佳俊团队。
论文共同一作是Keshigeyan Chandrasegaran和Agrim Gupta。
Keshigeyan Chandrasegaran是斯坦福大学计算机科学博士二年级学生,从事计算机视觉和机器学习研究,导师是李飞飞和斯坦福视觉与学习实验室(SVL)联合主任胡安·卡洛斯·尼贝莱斯。

共同一作Agrim Gupta是斯坦福大学计算机科学专业的博士生,2019年秋季入学,同样是李飞飞的学生。
此前,他曾在微软、DeepMind,有Meta的全职经历,也在Google做过兼职。2018年时,他就跟随李飞飞一同在CVPR上发表了论文。
目前,Agrim的Google Scholar论文被引用量接近6400次。
李飞飞是大家熟悉的AI教母,AI领域内最具影响力的女性和华人之一。
她33岁成为斯坦福计算机系终身教授,44岁成为美国国家工程院院士,现任斯坦福以人为本人工智能研究院(HAI)院长。
计算机视觉领域标杆成果ImageNet亦是由她一手推动。
此前,李飞飞也曾短暂进入工业界,出任谷歌副总裁即谷歌云AI首席科学家。她一手推动了谷歌AI中国中心正式成立,这是Google在亚洲设立的第一个AI研究中心。并带领谷歌云推出了一系列有影响力的产品,包括AutoML、Contact Center AI、Dialogflow Enterprise等。
今年,李飞飞宣布创办空间智能公司World Labs,公司成立不到4个月时间,估值突破10亿美元。
所谓空间智能,即“视觉化为洞察;看见成为理解;理解导致行动”。

吴佳俊,现任斯坦福大学助理教授,隶属于斯坦福视觉与学习实验室(SVL)和斯坦福人工智能实验室(SAIL)。
他在麻省理工学院完成博士学位,本科毕业于清华大学姚班,曾被誉为“清华十大学神”之一。
同时,他也是李飞飞创业公司World Labs的顾问。

参考链接:
[1]https://arxiv.org/abs/2411.04998v1
[2]https://www.worldlabs.ai/team
[3]https://keshik6.github.io/
文章来自于微信公众号“量子位”,作者“衡宇”




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
