# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
o1不是通向大模型推理的唯一路径!
MIT的新研究发现,在测试时对大模型进行训练,可以让推理水平大幅提升。
在挑战超难的ARC任务时,准确率最高可提升至原来的5.83倍。
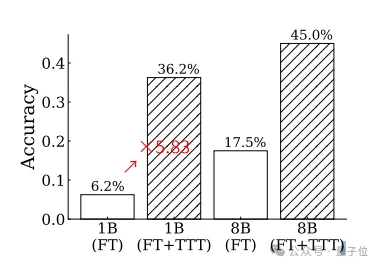
这样的表现不仅优于GPT-4和Claude,如果与其他推理方法相结合,还能超越人类的平均水准。
OpenAI o1团队成员Noam Brown表示,o1的大规模计算可能不是最好的方法,很高兴看到有学者在提高推理能力上探索新的方法。

不同于传统的先训练后测试模式,测试时训练(Test-Time Training,TTT)在部署阶段面对新的测试样本时,不直接用训练好的模型去推理。
在推理之前,测试样本自身携带的信息,会通过快速的训练过程被用于调整模型参数。
总体来说,TTT过程中一共有三个关键阶段——训练数据生成、模型适应范式设计以及推理阶段的策略。
数据生成的核心是将测试任务中蕴含的输入输出对关系,通过数据增强的方式最大限度地利用,可具体分为两个步骤。
首先是基于leave-one-out构造新的任务。
对于包含K个输入输出对的测试任务,依次将每个样本留出作为测试样本,其余K-1个作为训练样本,由此构造出K个新的TTT训练任务。
这样就可以从一个测试任务出发,构造出K个结构一致但内容互补的新任务,从而扩充了TTT训练数据。
在此基础上,作者还进行了数据增强,主要包括对输入输出施加各类几何变换,以及打乱训练样本对的顺序。
经过这一步,TTT训练集的规模可以得到显著扩大。
整个TTT数据构造过程可高度自动化,不依赖人工标注。
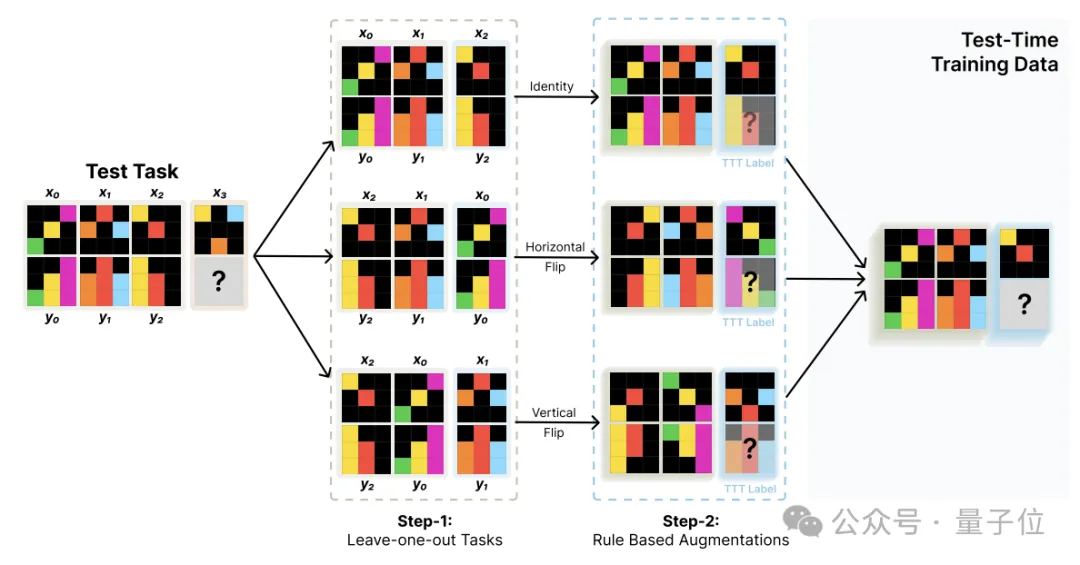
利用构造好的TTT数据集,就可以对预训练好的语言模型进行测试时训练。
考虑到测试时的资源限制,作者采用了参数高效的LoRA,为每个测试任务学习一组独立的adapter参数,附加在预训练模型的每一层之上,通过一个低秩矩阵与原始权重相乘起到调节作用。
过程中还额外加入了对所有前缀序列的预测,目的是通过在各种长度的演示样本上都计算损失,鼓励模型尽早地从少量信息中总结出抽象规律,从而提高鲁棒性。

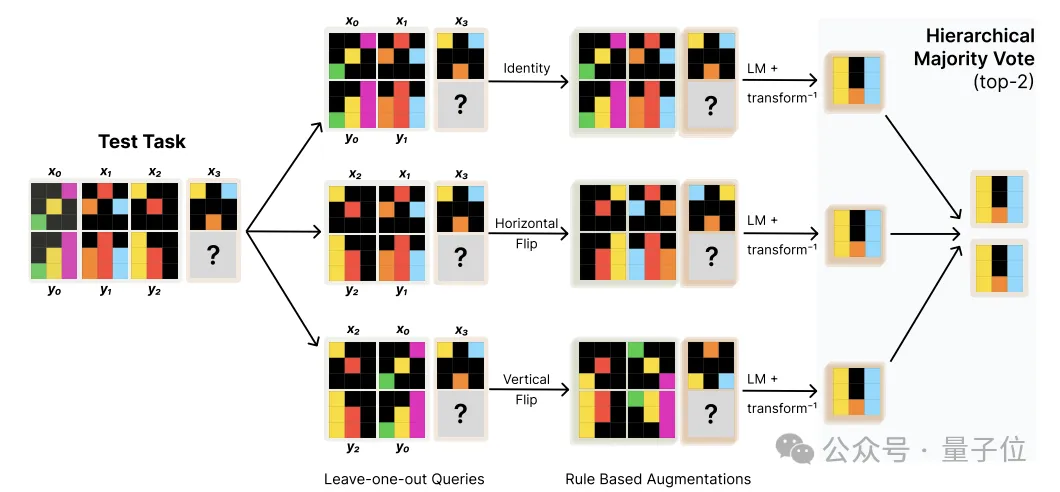
最后,为了实现TTT效果的最大化,作者在推理阶段应用了数据增强和集成学习策略。
推理过程中,先利用一系列预定义的几何变换算子(如旋转、翻转等)扩充原始输入,生成若干等价视角下的输入变体。
之后将每个变体输入并行地送入LoRA-tuned模型,独立完成预测,然后再对齐和还原到原始输入空间,由此得到一组成对的预测。
在成对预测的基础上,通过分两层投票的方式完成集成融合:
这一推理策略,既通过数据增强引入了输入的多样性,又用分层投票的方式对不同来源的预测进行了结构化的组合,进一步提升了TTT方法的效果。
为了评估TTT方法的效果,研究团队以8B参数的GPT-3作为基础模型进行了测试。
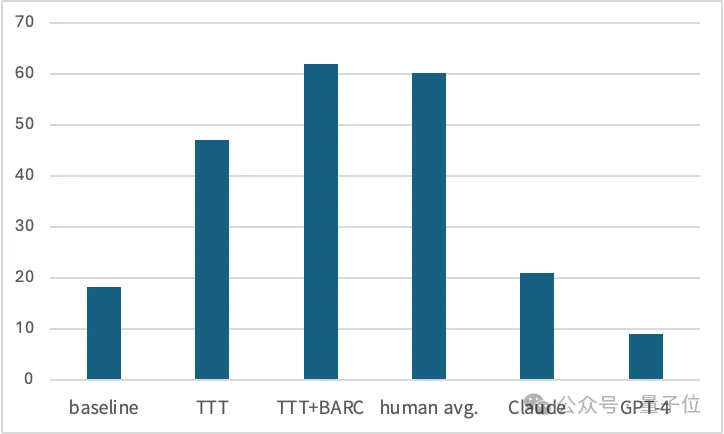
如果不使用TTT仅进行微调,模型在ARC数据集上的准确率只有18.3%,加入TTT后提升到47.1%,增长率达到了157%。

另外,作者还从ARC数据集中随机选择了80个任务作为子集进行了测试。
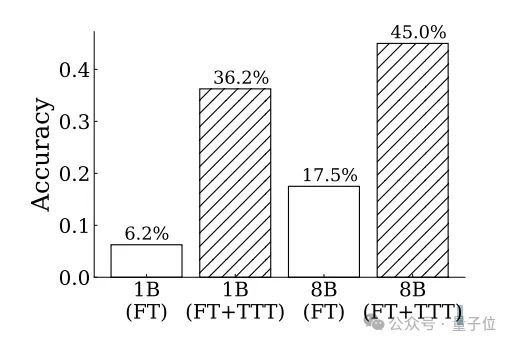
测试发现,TTT方法对于1B模型的提升效果更加明显,调整后模型的准确率接近调整前的6倍。
并且在调整前后,1B和8B两个规模的模型之间的相对差距也在缩小。
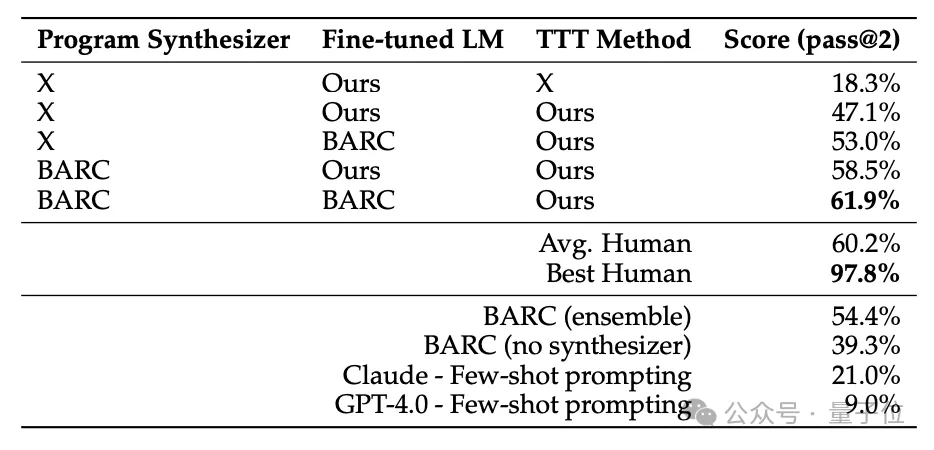
进一步地,作者还将TTT方法与之前在ARC任务上取得优异成绩的BARC(Bootstrapping Approach for Reward model Construction)方法进行了比较和结合。
具体来说,作者首先独立运行这两个系统,得到它们在每个测试任务上的输出。
如果两者输出完全一致,则直接认为推理结果是正确的;
如果输出不一致,则看BARC是否能够生成确定的、唯一覆盖所有测试样本的解题程序,若是则认为BARC的输出更可靠;
反之,如果BARC生成了多个候选程序但无法确定最优解,或者干脆无法生成任何满足约束的程序,则认为TTT的输出更可靠。
两种方式配合使用后,取得了61.9%的SOTA成绩,已经超过了人类的平均水平。
根据作者在推文中的介绍,在这篇论文发布前,一个叫做MindsAI的团队已经发现使用了相同的技术。
利用TTT技术,该团队已经用58%的正确率取得了ARC挑战的第一名。
作者的论文发布之后,MindsAI团队领导者Jack Cole也发文进行了祝贺:
很高兴,我们掀起了这场对TTT的兴趣风暴。
同时,Jack还推荐了另一名研究TTT的学者——斯坦福大学华人博士后Yu Sun,表示他的研究值得被关注。
Sun的个人主页显示,他针对测试时训练进行了大量研究,相关成果入选过ICML、NeurIPS、ICLR等多个顶级会议。

论文地址:
https://ekinakyurek.github.io/papers/ttt.pdf
文章来自于微信公众号“量子位”,作者“ 克雷西”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
