# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近,YouTube和Reddit上出现了一个引起广泛讨论的图像生成模型,来自日本、韩国、美国、印度、中东和英国的网友们纷纷参与讨论。
Youtube热烈讨论
那么,这到底是怎么回事呢?让我们一起来看看吧。
近年来,大语言模型在自然语言处理领域取得了巨大的突破,以LLaMA和Qwen等为代表的模型展现了强大的语言理解和生成能力。
但是,图像生成技术的突破主要得益于扩散模型,如Stable Diffusion XL在图像质量、细节和概念一致性方面设立了事实标准。
然而,这些扩散模型与自回归语言模型的工作原理和架构显著不同,导致在视觉和语言任务上实现统一生成方法面临挑战。这种差异不仅使这些模态的整合变得复杂,还凸显了需要创新的方法来弥合它们之间的差距。
自回归文本到图像模型(如LlamaGen)通过预测下一个token生成图像,但由于生成的图像token数量庞大,自回归模型在效率和分辨率上也面临瓶颈,难以应用到实际场景。于是,一些Masked Image Modeling(MIM)技术,例如MaskGIT和MUSE被提出。这些方法展现了高效图像生成的潜力。
尽管MIM方法具有一定的前景,它们仍面临两个关键限制:
当前的MIM方法只能生成最大分辨率为512×512像素的图像。这一限制阻碍了它们的广泛应用和进一步发展,尤其是在文本生成图像的社区中,1024×1024分辨率逐渐成为标准。
现有的MIM技术尚未达到领先扩散模型如SDXL所表现的性能水平,特别是在图像质量、复杂细节和概念表达等关键领域表现不佳,而这些对实际应用至关重要。
这些挑战需要探索新的创新方法,Meissonic的目标是使MIM能够高效生成高分辨率图像(如1024×1024),同时缩小与顶级扩散模型的差距,并确保其计算效率适合消费级硬件。
Meissonic模型提出了全新的解决方案,基于非自回归的掩码图像建模(MIM),为高效、高分辨率的T2I生成设定了新标准。

论文链接: https://arxiv.org/abs/2410.08261
GitHub Code: https://github.com/viiika/Meissonic
Huggingface Model: https://huggingface.co/MeissonFlow/Meissonic
通过架构创新、先进的位置编码策略和优化的采样方法,Meissonic不仅在生成质量和效率上与领先的扩散模型(如SDXL)相媲美,甚至在某些场景中超越了它们。
此外,Meissonic利用高质量的数据集,并通过基于人类偏好评分的微观条件进行训练,同时引入特征压缩层,显著提升了图像的保真度与分辨率。

以下是Meissonic在方法上的几项重要技术改进:
Meissonic结合了多模态与单模态的Transformer层,旨在捕捉语言与视觉之间的互动信息。从未池化的文本表示中提取有用信号,构建两者之间的桥梁;单模态Transformer层则进一步细化视觉表示,提升生成图像的质量与稳定性。研究表明,这种结构按1:2比例能够实现最佳性能。
为保持高分辨率图像中的细节,Meissonic引入了旋转位置编码(RoPE),为queries和keys编码位置信息。RoPE有效解决了随着token数量增加,传统位置编码方法导致的上下文关联丢失问题,尤其在生成512×512及更高分辨率图像时。
此外,Meissonic通过引入掩码率作为动态采样条件,使模型自适应不同阶段的采样过程,进一步提升图像细节和整体质量。
Meissonic的训练依赖于经过精心筛选的高质量数据集。为提升图像生成效果,Meissonic在训练中加入了图像分辨率、裁剪坐标及人类偏好评分等微观条件,显著增强了模型在高分辨率生成时的稳定性。
为了在保持高分辨率的同时提升生成效率,Meissonic引入了特征压缩层,使其在生成1024×1024分辨率图像时可以有效降低计算成本。
那么,Meissonic到底有多强大呢?让我们来看看它的表现:
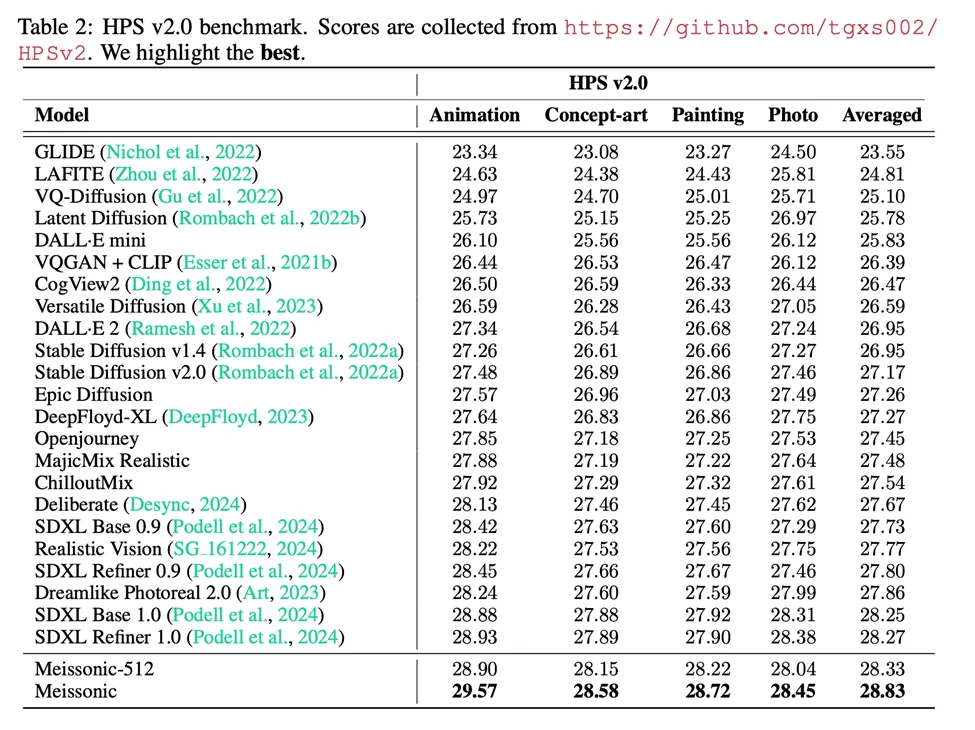
在HPS V2.0基准测试中,Meissonic以平均0.56分的优势超越了SDXL。
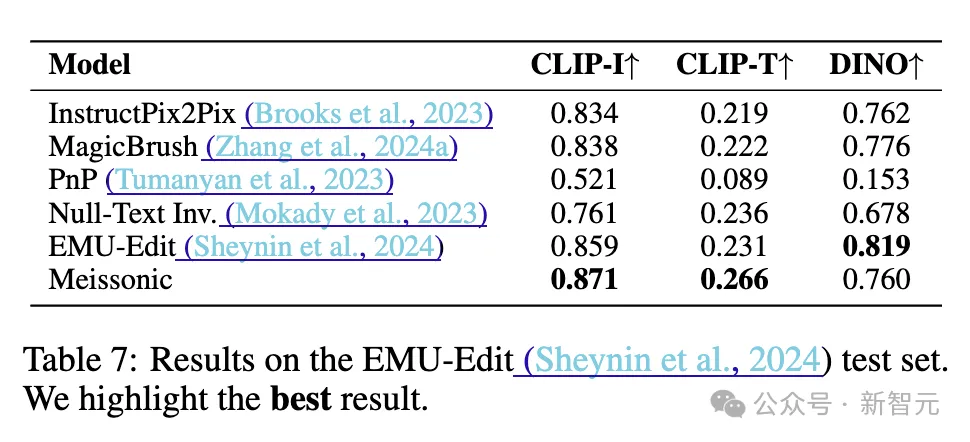
在图像编辑能力评测数据集Emu-Edit上,Meissonic的Zero-shot图像编辑性能甚至超越了经过图像编辑指令微调后的模型

在风格多样性生成方面,Meissonic展现出超越SDXL的表现。
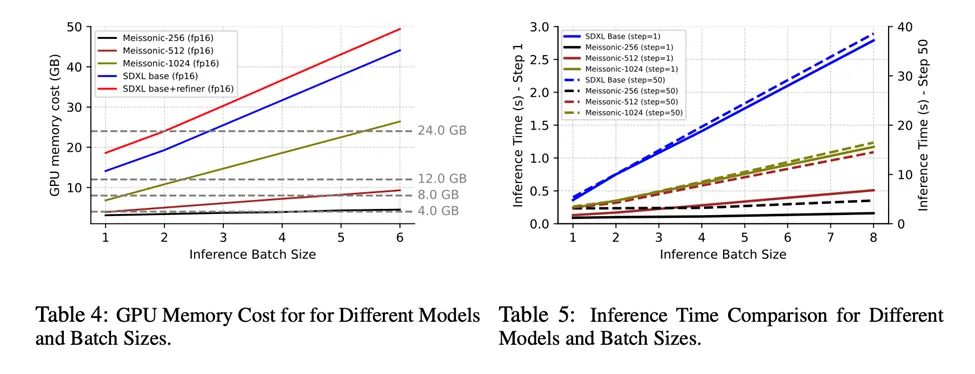
而这一切,都只需SDXL 1/3的推理时间和1/2的显存占用。值得注意的是,Meissonic可以在8GB显存下运行,让中低端显卡的用户也能受益。
此外,Meissonic还展现了超强的zero-shot图像编辑能力,无需微调即可灵活编辑有mask和无mask的场景,提供了更多创作可能性。


高效推理与训练的结合
在文本到图像合成领域,Meissonic模型凭借卓越的效率脱颖而出。该模型不仅在推理过程中实现了高效性,同时在训练阶段也显著提升了效率。Meissonic采用了一套精心设计的四阶段训练流程,逐步提升生成效果。
研究表明,原始LAION数据集的文本描述无法充分满足文本到图像模型的训练需求,通常需要多模态大型语言模型(MLLM)进行优化,但这消耗大量计算资源。
为此,Meissonic在初始阶段采用了更加平衡的策略,利用经过筛选的高质量LAION数据学习基础概念,通过降分辨率的方法提高效率,最终保留约2亿张高质量图像,并将初始训练分辨率设定为256×256。
第二阶段的重点在于提升模型对长文本描述的理解能力。团队筛选了审美分数高于8的图像,构建了120万对优化后的合成图文对及600万对内部高质量图文对。此阶段,训练分辨率提升至512×512,配对数据总量达到约1000万对,从而显著提升了Meissonic在处理复杂提示(如多样风格和虚拟角色)以及抽象概念方面的能力。
在Masked Image Modeling(MIM)领域,生成高分辨率图像仍然是一个挑战。Meissonic通过特征压缩技术高效实现了1024×1024分辨率的图像生成。引入特征压缩层后,模型能够在较低计算成本下实现从512×512到1024×1024的平滑过渡,此阶段的数据集经过进一步筛选,仅保留约600万对高分辨率、高质量的图文配对,以1024分辨率进行训练。
在最后阶段,Meissonic通过低学习率微调模型和文本编码器,并引入人类偏好评分作为训练条件,进一步提升了生成图像的质量和多样性。这一阶段的训练数据与第三阶段保持一致,但更加注重对高分辨率图像生成的美学细节的打磨。
通过上述四个阶段的训练,Meissonic在训练数据和计算成本上实现了显著降低。具体而言,在训练过程中,Meissonic仅使用210万张图像,相较于其他主流模型(如SD-1.5和Dall-E 2),训练数据的使用量显著减少。
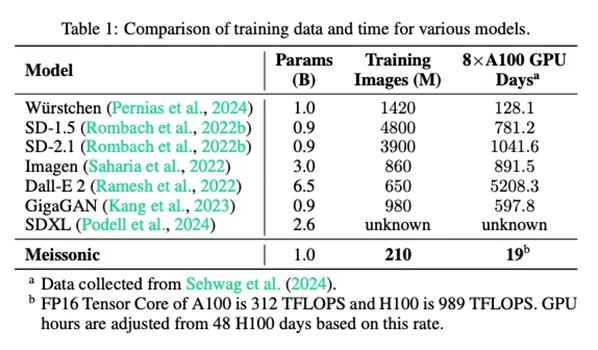
在使用8个A100 GPU进行训练的情况下,Meissonic的训练时间仅需19天,显著低于Würstchen、SD-2.1等模型的训练时间。
最近,移动设备上的端侧文本到图像应用如谷歌Pixel 9的Pixel Studio和苹果iPhone 16的Image Playground相继推出,反映出提升用户体验和保护隐私的日益趋势。作为一种资源高效的文本到图像基座模型,Meissonic在这一领域代表了重要的进展。
此外,来自斯坦福大学的创业团队Collov Labs在一周内就成功复现出同样架构的Monetico,生成效果可以与Meissonic相媲美,推理效率更加高效,并荣登huggingface趋势榜第一名。这也显示出Meissonic架构在资源高效上的巨大潜力和应用价值。
参考资料:
https://arxiv.org/abs/2410.08261
文章来自微信公众号 “ 新智元 ”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
