# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
第8届CoRL于2024年11月6日至9日在德国慕尼黑举行,展示了机器人学习领域的前沿研究和发展,尤其是在自主系统、机器人控制和多模态人工智能领域。
CoRL的全称为Conference on Robot Learning(机器人学习大会),旨在分享和探讨机器人技术与机器学习交叉领域的最新进展,已经成为了机器人学与机器学习交叉领域的全球顶级学术会议之一。在本届机器人学习会议的行业专题讨论中,汇聚了各大科技公司重量级嘉宾,包括Pi公司的Suraj Nair、谷歌DeepMind的Nicolas Heess、丰田研究院(TRI)的Russ Tedrake以及英伟达(NVIDIA)的Yashraj Narang。
据官方数据,今年CoRL吸引了超过1000名参会者,总共收到671篇投稿,其中265篇论文入选。热门研究主题包括机器人如何适应真实世界环境、基于感知的导航以及人机交互等领域。值得一提的是,在今年的CoRL2024上,无论是入选论文还是口头报告环节(Oral Session)都有大量华人学者的身影。其中,清华交叉信息研究院助理教授、星海图联合创始人许华哲、赵行共有7篇论文成果被录用。在CoRL最佳论文奖和最佳论文提名奖的6篇论文中,华人作者同样占比很高。
在众多优秀研究成果中,最受瞩目的当属最佳论文奖的得主,评选结果已经揭晓,让我们一起来看看这些突破性的研究工作:

作者:Kuo-Hao Zeng, Kiana Ehsani, Rose Hendrix, Jordi Salvador, Zichen Zhang, Alvaro Herrasti, Ross Girshick, Aniruddha Kembhavi, Luca Weihs
机构:艾伦人工智能研究所PRIOR团队
论文地址:https://openreview.net/forum?id=KdVLK0Wo5z
论文摘要:我们提出POLIFORMER(Policy Transformer),这是一个仅基于RGB输入的室内导航智能体,通过大规模端到端强化学习训练,尽管完全在模拟环境中训练,仍能直接推广至真实世界,无需适应性调整。POLIFORMER采用基础视觉transformer编码器和因果transformer解码器,实现长期记忆和推理能力。它在多样化环境中经过数亿次交互训练,利用并行化的多机器交互采样实现高通量的高效训练。POLIFORMER是一个卓越的导航器,在两种不同的机器人平台(LoCoBot和Stretch RE-1)以及四个导航基准测试中均达到了最优性能。它突破了先前研究的瓶颈,在CHORES-S基准的目标物导航任务中取得了85.5%的前所未有的成功率,相较之前提升了28.5个百分点。此外,POLIFORMER无需微调即可轻松扩展到各种下游应用,如目标跟踪、多目标导航和开放词汇导航等。

论文简介:POLIFORMER解决了一个长期存在的技术难题。此前的强化学习方法在简单的点对点导航(PointNav)任务上表现出色,但在更具挑战性的目标物导航(ObjectNav)任务上始终难以突破。虽然最近基于模仿学习的方法(如SPOC)取得了一定进展,但其性能在57%的成功率处遇到了瓶颈。
该论文旨在解决室内导航问题,通过强化学习在模拟环境下进行大规模训练,实现在真实环境下的泛化。该模型的突破性表现归功于三大设计决策:(1) 规模化架构:完全基于transformer的策略模型,包含DINOv2视觉基础模型、状态编码器和因果解码器,以优化状态总结和时间记忆;(2) 规模化回放:并行进行数百次回放与大批量环境交互,提升训练效率;(3) 规模化环境互动:在150,000个程序生成的房屋环境中进行RL训练,以提升泛化能力。此外,POLIFORMER-BOXNAV扩展模型通过外部目标框进行目标导航,适用于多种下游导航任务,如多目标导航、人类跟随和物体跟踪。
总体而言,POLIFORMER提供了一个有效的强化学习训练流程,显著提升了机器人导航的成功率,标志着导航领域的重要进步。
获奖论文:One Model to Drift Them All
作者:Franck Djeumou, Thomas Jonathan Lew, Nan Ding, Michael Thompson, Makoto Suminaka, Marcus Greiff, John Subosits
机构:丰田研究院,伦斯勒理工学院
论文地址:https://openreview.net/forum?id=0gDbaEtVrd
论文摘要:在极限操作下实现车辆自主控制,即当轮胎力饱和的情况下安全操作车辆,可提高其在紧急避障或恶劣天气等场景下的安全性。然而,受路面、车辆及其动态交互的多模态特性的高度不确定性影响,开发此能力具有极大挑战。针对这一问题,我们提出了一种框架,使用未标记的多模态轨迹数据集学习条件扩散模型,用于高性能的车辆控制。我们设计的扩散模型可捕捉物理驱动的动态模型参数分布,通过对在线测量的条件生成过程,将扩散模型集成到实时的模型预测控制框架中,用于极限驾驶,能够在操作中动态适应特定的车辆和环境。
在丰田Supra和雷克萨斯LC 500上的大量实验显示,单一扩散模型可实现两种车辆在不同轮胎和多变路况下的可靠的自主漂移。该模型不仅与任务特定的专家模型表现相当,还在适应未见条件方面表现出色,为实现通用、可靠的极限操控自动驾驶方法铺平了道路。

论文简介:该研究介绍了一种创新的条件扩散模型,用于在高度不确定条件下,实现自动驾驶车辆在操控极限下的控制。现有的自动驾驶技术大多在较为安全的范围内运行,但若能可靠地控制车辆突破这一界限(例如在冰雪路面或遇到突发障碍物时),将显著提升车辆在关键安全情境下的反应能力。作者通过利用扩散模型来应对动态车体行为、模型不匹配及环境因素不可预测性的问题,使其能够表示复杂的高维不确定分布。
该模型的核心贡献包括:1. 将物理知识作为先验信息,提高模型的解释性和泛化能力;2. 捕捉车辆动力学中的多模态不确定性;3. 通过条件输入实现车辆和路况的实时适应;4. 预测物理参数而非状态轨迹,从而提升模型推理效率,实现高频预测控制。
在Toyota Supra和Lexus LC500上的广泛测试表明,该扩散模型在多种复杂环境中都能有效处理漂移任务,表现出稳健的控制能力,无需特定的任务调优。
最佳论文提名奖("Outstanding Paper Award" Finalists)

获奖论文:ReMix: Optimizing Data Mixtures for Large Scale Imitation Learning
作者:Joey Hejna, Chethan Anand Bhateja, Yichen Jiang, Karl Pertsch, Dorsa Sadigh
机构:斯坦福大学,加州大学伯克利分校
论文地址:https://openreview.net/forum?id=fIj88Tn3fc
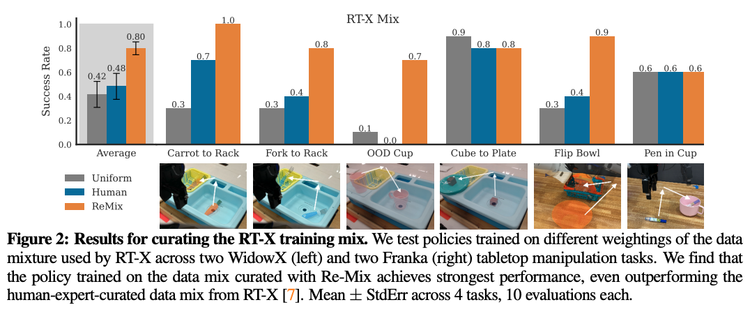
论文摘要:随着机器人基础模型的发展,研究人员正在收集越来越多的模仿学习数据集。然而,与视觉和自然语言处理领域高度重视数据选择不同,机器人领域却很少有研究关注这些模型应该使用什么样的训练数据。本研究探讨了如何在机器人基础模型预训练中合理分配不同子数据集(或称"领域")的权重。我们采用分布鲁棒优化(DRO)方法,旨在最大化所有可能下游领域中的最低性能表现。我们提出的Re-Mix方法成功应对了将DRO应用于机器人数据集时面临的诸多挑战,特别是数据集之间在动作空间和动力学特性方面的差异。为了克服这些问题,Re-Mix整合了早停策略、动作归一化和离散化等技术手段。我们在目前最大的开源机器人操作数据集Open X-Embodiment上进行了大量实验,结果表明数据筛选对下游任务的性能有着显著影响。具体来说,Re-Mix学习得到的领域权重方案比均匀权重方案平均提升了38%的性能,在现有通用机器人策略(尤其是RT-X模型)的训练数据集上比人工选择的权重方案提升了32%的性能。
获奖论文:Equivariant Diffusion Policy
作者:Dian Wang, Stephen Hart, David Surovik, Tarik Kelestemur, Haojie Huang, Haibo Zhao, Mark Yeatman, Jiuguang Wang, Robin Walters, Robert Platt
机构:美国东北大学,波士顿动力人工智能研究所
论文地址:https://openreview.net/forumid=wD2kUVLT1g¬eId=wD2kUVLT1g
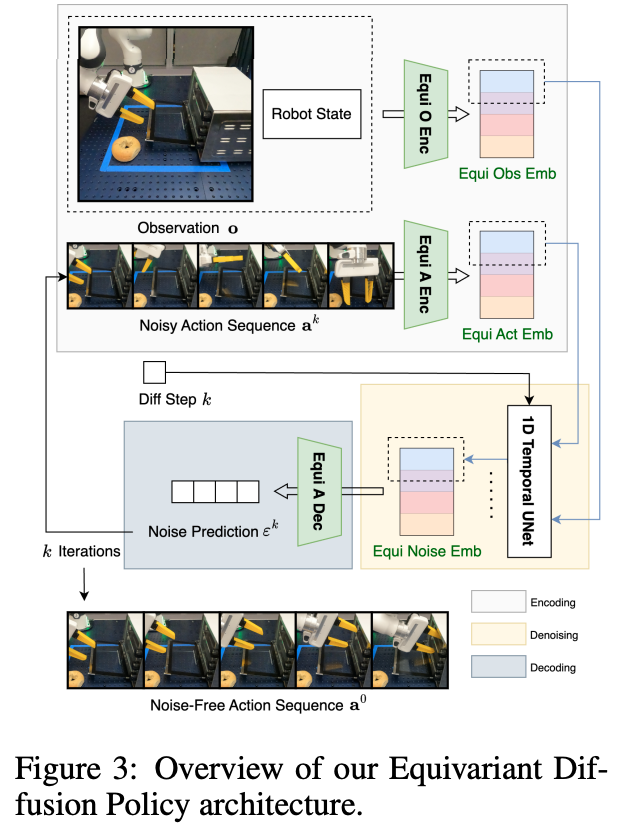
论文摘要:近期研究表明,扩散模型在学习行为克隆中的示范数据多模态分布方面表现出色。然而,这种方法存在一个明显的不足:相比直接学习显式策略,它需要学习更为复杂的去噪函数。为了解决这个问题,本研究提出了一种新型的扩散策略学习方法——等变扩散策略(Equivariant Diffusion Policy)。该方法通过利用领域对称性,显著提高了去噪函数的样本利用效率和泛化性能。在理论方面,我们深入分析了完整6自由度控制中的SO(2)对称性,并明确了扩散模型实现SO(2)等变性的条件。在实践方面,我们在MimicGen平台的12个仿真任务上进行了全面评估,结果显示该方法的平均成功率比基准扩散策略提升了21.9%。更为重要的是,我们在真实系统上的测试表明,该方法能够通过较少的训练样本学习得到有效的控制策略,而基准扩散策略在相同条件下则无法实现这一目标。这一发现对于实际应用具有重要意义。
获奖论文:HumanPlus: Humanoid Shadowing and Imitation from Humans
作者:Zipeng Fu, Qingqing Zhao, Qi Wu, Gordon Wetzstein, Chelsea Finn
机构:斯坦福大学
论文地址:https://openreview.net/forum?id=WnSl42M9Z4
论文摘要:采用类人形态设计机器人的一个关键理论依据是可以充分利用海量的人类数据进行训练。然而,这一设想在实践中仍面临诸多挑战:人形机器人的感知与控制极其复杂,机器人与人类在形态结构和驱动机制上仍存在显著差距,同时也缺乏一套完整的数据管道来支持人形机器人通过第一人称视觉学习自主技能。针对这些问题,本文提出了一个全栈系统,实现人形机器人从人类数据中学习运动技能和自主能力。我们首先利用现有的40小时人类运动数据集,在模拟环境中通过强化学习训练底层策略。这一策略成功迁移到现实环境后,使人形机器人能够仅依靠RGB相机实时模仿人类的身体和手部动作,我们称之为"影随"技术。通过这种影随机制,操作人员可以远程控制人形机器人,在真实环境中采集完成不同任务所需的全身动作数据。基于采集到的数据,我们进一步通过监督式行为克隆方法,训练基于第一人称视觉的技能策略,使人形机器人能够自主模仿并完成各类人类技能。我们在自主研发的33自由度、身高180厘米的人形机器人上验证了该系统的有效性。实验表明,仅需不超过40次示范,机器人就能以60%-100%的成功率自主完成多项复杂任务,包括穿鞋后站立行走、折叠卫衣、物品重排、打字,以及与其他机器人互动打招呼等。

获奖论文:OpenVLA: An Open-Source Vision-Language-Action Model
作者:Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan
Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, Chelsea Finn
机构:Stanford,UC Berkeley,TRI,Deepmind,MIT
论文地址:https://arxiv.org/pdf/2406.09246
论文摘要:预训练大型策略模型时,如果结合互联网规模的视觉语言数据和丰富的机器人示范数据,将有望革新我们教授机器人新技能的方式。这种方法让我们无需从零开始训练新的行为模式,而是通过微调视觉-语言-动作(VLA)模型,就能获得稳健且具有良好泛化能力的视觉运动控制策略。然而,VLA技术在机器人领域的推广面临两大挑战:一方面,现有的VLA模型大多采用封闭架构,普通用户难以访问;另一方面,学术界尚未深入研究如何高效地微调VLA模型以适应新任务,而这恰恰是推广应用的关键所在。针对这些挑战,我们开发了OpenVLA系统。这是一个开源的VLA模型,拥有70亿参数,经过97万个真实机器人示范数据的训练。该系统以Llama 2语言模型为基础,配备了一个创新的视觉编码器,该编码器融合了来自DINOv2和SigLIP的预训练特征。通过增强数据多样性和改进模型架构,
OpenVLA在通用操作任务中取得了显著成效:在29个测试任务和多种机器人平台上,其绝对任务成功率比拥有550亿参数的RT-2-X模型高出16.5%,而所需参数量仅为后者的七分之一。我们的研究还表明,OpenVLA具有出色的微调适应性。它在多物体多任务环境中展现了强大的泛化能力和语言理解能力,其性能比传统的从零起步的模仿学习方法(如扩散策略)提升了20.4%。在计算效率方面,我们也取得了重要突破:通过采用现代低秩适应方法,OpenVLA可以在普通消费级GPU上完成微调;通过量化技术,能够实现高效部署,同时保持下游任务的成功率不受影响。为推动该领域的发展,我们已开源了模型检查点、微调教程笔记本和基于PyTorch的代码库,这些工具可直接支持在Open X-Embodiment数据集上进行大规模VLA模型训练。

机器人继续Scaling?
近年来,CV和NLP领域通过大规模数据训练取得的成功,引发了机器人界的思考:这种方法是否也能解决机器人领域的问题?这成为了去年CoRL的核心议题之一,从整体趋势来看,今年的Corl也呼应了这一发展方向。
虽然机器人领域面临数据严重不足、难以大规模收集等挑战,但从今年的论文和讨论可以看出,学界正在积极探索多种scaling途径:强化学习与大模型结合、跨模态学习与视觉语言模型、通过大规模数据训练、优化数据混合策略、结合预训练大模型等方式来提升机器人性能,同时也在努力解决数据收集效率和实际部署可靠性等问题。
在今年CoRL的WCBM研讨会上,Physical Intelligence(Pi)公司的两位创始人Chelsea Finn和Sergey Levine分别进行了演讲。核心内容是Pi公司正试图在机器人领域复制语言基础模型的成功经验。从大语言模型(LLMs)的发展来看:OpenAI、Meta等公司通过对经过精心策划的互联网规模数据集进行训练,已经取得了巨大成功。这些训练完成的基础模型能够以零样本方式(即模型被正确使用时)或在合适的提示下,成为回答特定领域问题的专家。
Pi公司的目标是在机器人领域实现类似的突破。他们的理念是:通过互联网的通用数据(结合一些机器人数据集和开源机器人数据档案)训练视觉-语言-行动(VLA)模型,然后针对特定用途的机器人收集约20小时的数据进行微调,使模型能在特定机器人上实现出色表现。
文章来自微信公众号 “硅星人Pro” , 作者“周一笑”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
