# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如何更好地设计提示词(Prompt)一直是大家关注的焦点。最近,一个独特的研究视角引起了广泛关注:将LLMs视为“演员”,将提示词视为“剧本”,将模型输出视为“表演”。


这种新颖的思维方式不仅在概念上令人耳目一新,更重要的是,它在实践中展现出了显著的效果提升,在玩《纽约时报》的单词谜题游戏“Connections”中的表现任务中,采用“方法演员”提示架构可以提高 o1-preview 完美解决谜题的百分比,从 76%提高到 87%。这种方法为我们理解和使用LLMs提供了一个全新的工具,通过将模型的输出过程视作舞台上的表演,大家能够更好地引导模型的行为,从而实现精确和连贯的回应。
目前主流的提示工程方法主要包括:
这些方法虽然各有特色,但都存在一个共同的假设:将LLM的输出视为“思维”的产物。这种假设导致了两个问题:
1.概念模糊:什么是LLM的“思维”?这个概念本身就难以定义和把握,使得我们在面对复杂任务时难以判断和理解模型的推理逻辑。
2.方法局限:这些方法过分关注“思维”过程,而忽略了LLM本质上是在模仿人类的语言表达。因此,当面对需要深刻理解或复杂背景的任务时,模型往往会表现出不一致或缺乏深度的现象。
将LLM比作演员有几个显著优势:
1.概念清晰:
2.期望对齐:
2.方法指导:
1.提示工程即编剧与导演
2.表演需要准备
3.复杂任务分解原则
4.补充机制
“方法演员”模型的核心在于将LLMs视为“演员”,而不再只是单纯的工具。这意味着模型需要更好地理解场景,解析提示,然后在“表演”中提供响应。提示工程师可以通过精细化提示——即剧本——来指导模型如何“演出”不同的角色和场景。
例如,在面对一个关于政策问题的任务时,传统的LLMs可能会仅仅依赖训练数据给出一般性的回答,而“方法演员”模型则会通过理解更深层次的提示,考虑具体的场景和关系,从而给出更为契合的回答。这样的改进不仅仅是简单的输出变化,而是涉及模型如何通过不同的提示“进入角色”。
通过这种方式,提示工程师可以更精准地设计提示,使得LLMs在不同场景中有更好的适应能力。这种方法使得LLMs像真正的演员一样,根据不同的剧本深入理解并演绎不同的角色。
Connections是《纽约时报》推出的一个文字谜题游戏,规则如下:
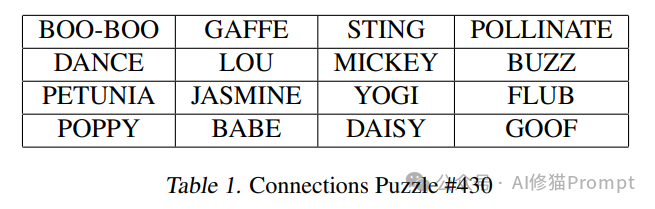

研究者设计了多组对照实验,以评估不同提示工程方法的效果:
1.基准方法:
2.Method Actor方法:
3.模型对比:
1.GPT-4测试结果:
方法解决率完美解决率Vanilla27%12%CoT41%20%CoT-Scripted56%24%Actor78%41%Actor-286%50%
2.o1-preview测试结果:
方法解决率完美解决率Oneshot-o179%72%Vanilla-o1100%76%Actor-o199%87%
3.方法效果:
4.模型表现:
5.难度适应:
1.场景设置
scene_template = """
背景:[具体情境]
角色:[专业身份]
动机:[紧迫性/重要性]
任务:[具体目标]
"""
2.角色定义
character_template = """
专业背景:[相关领域专长]
经验水平:[专业成就]
特殊能力:[独特优势]
"""
3.动作指示
direction_template = """
步骤1:[具体动作]
步骤2:[具体动作]
注意事项:[关键提醒]
"""
1.任务分解
2.状态管理
3.结果验证
1.性能优化
2.质量控制
3.成本控制
1.现有任务优化
2.新场景探索
3.产品集成
“方法演员”模型为提示工程和大型语言模型的使用带来了新的视角和方法。通过将LLMs视为演员,通过精心设计的提示——剧本——来指导其行为,提示工程师能够更加有效地控制模型的输出质量和上下文契合度。这种方法显著提高了模型的推理能力,特别是在零样本推理场景中的表现。



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
