
- 论文标题:Recent Advances of Multimodal Continual Learning: A Comprehensive Survey
- 论文链接:https://arxiv.org/abs/2410.05352
- GitHub地址:https://github.com/LucyDYu/Awesome-Multimodal-Continual-Learning
多模态连续学习的最新进展
连续学习(CL)旨在增强机器学习模型的能力,使其能够不断从新数据中学习,而无需进行所有旧数据的重新训练。连续学习的主要挑战是灾难性遗忘:当任务按顺序训练时,新的任务训练会严重干扰之前学习的任务的性能,因为不受约束的微调会使参数远离旧任务的最优状态。尽管连续学习取得了重大进展,但大多数工作都集中在单一数据模态上,如视觉,语言,图,或音频等。这种单模态的关注忽略了现实世界环境的多模态本质,因为现实世界环境本身就很复杂,由不同的数据模态而不是单一模态组成。
随着多模态数据的快速增长,发展能够从多模态来源中连续学习的 AI 系统势在必行,因此出现了多模态连续学习(MMCL)。这些 MMCL 系统需要有效地集成和处理各种多模态数据流,同时还要在连续学习中设法保留以前获得的知识。
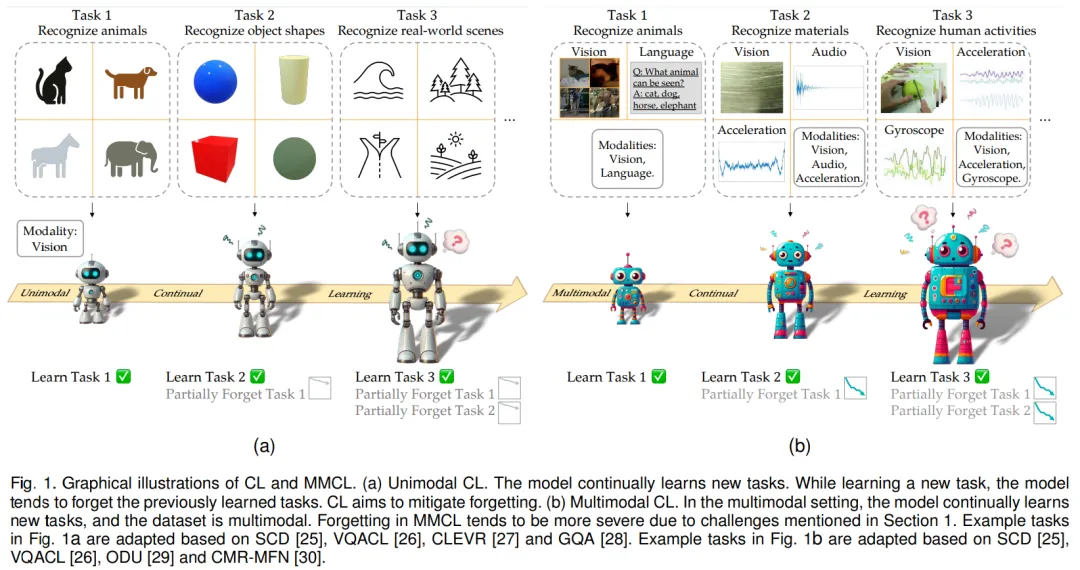
尽管传统的单模态 CL 与多模态 CL 之间存在联系,但多模态 CL 所面临的挑战并不仅仅是简单地将 CL 方法用于多模态数据。这种直接的尝试已被证明会产生次优性能。具体而言,如图所示,除了现有的 CL 灾难性遗忘这一挑战外,MMCL 的多模态性质还带来了以下四个挑战。
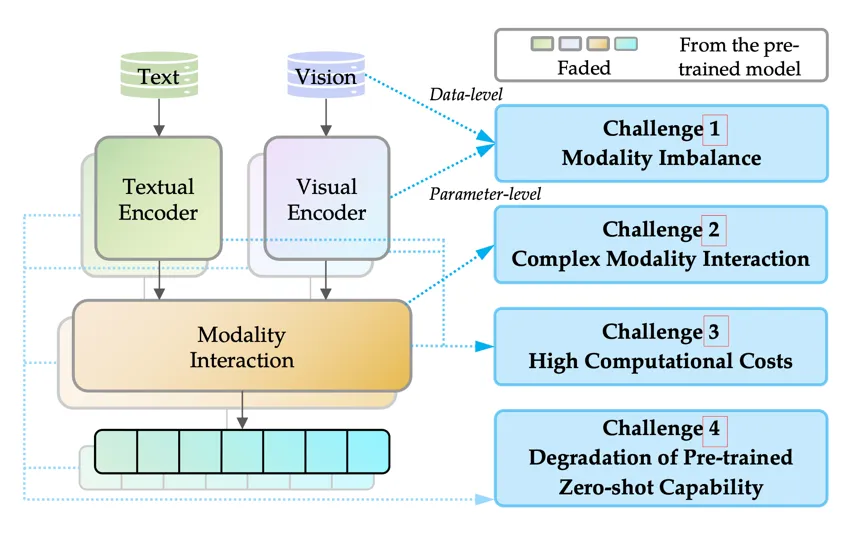
- 挑战 1 模态失衡:模态失衡是指多模态系统中不同模态的处理或表示不均衡,表现在数据和参数两个层面。在数据层面,不同模态的数据可用性可能会在 CL 过程中发生显著变化,出现极度不平衡的情况,如缺乏某些模态。在参数层面,不同模态组件的学习可能会以不同的速度收敛,从而导致所有模态的学习过程整体失衡。
- 挑战 2 复杂模态交互:模态交互发生在模型组件中,在这些组件中,多模态输入信息的表征明确地相互作用。这种交互给 MMCL 带来了独特的挑战,主要体现在两个交互过程中:模态对齐和模态融合。在模态对齐过程中,单个数据样本的不同模态特征往往会在连续学习过程中出现分散,这种现象被称为 MMCL 中的空间紊乱。这种发散可能会导致更严重的性能下降。在模态融合方面,在非 CL 环境中使用的经典多模态融合方法在 MMCL 环境中可能会表现较差,因为不同的融合技术对解决遗忘问题有不同的效果。
- 挑战 3 高计算成本:在 MMCL 中加入多种模态会大大增加计算成本,无论是在模型层面还是在任务层面都是如此。在模型层面,增加模态不可避免地会增加可训练参数的数量。许多 MMCL 方法利用预训练的多模态模型作为基础。然而,不断对这些大规模模型进行整体微调会带来沉重的计算开销。同样,在特定任务层面,MMCL 方法可能会导致特定任务可训练参数的持续积累,这些参数可能会超过预训练模型中的参数数量,从而抵消了采用连续学习训练模式的效率优势。
- 挑战 4 预训练零样本能力的退化:随着预训练模型的进步,MMCL 方法可以用这些强大的模型。这些预先训练好的多模态模型经常会表现出零样本能力。然而,在训练过程中,该能力可能会减弱。这种退化风险可能导致未来任务上的严重性能下降,这被称为 MMCL 中的负前向知识转移。
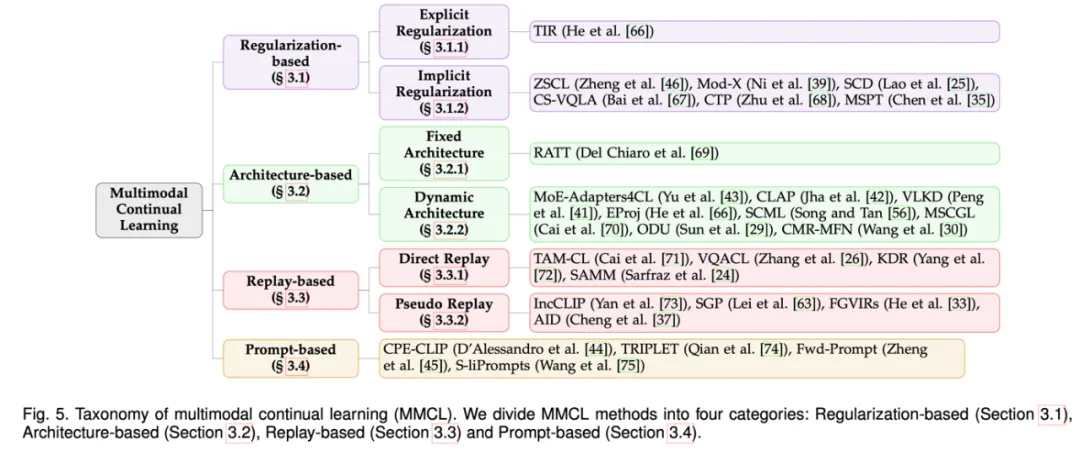
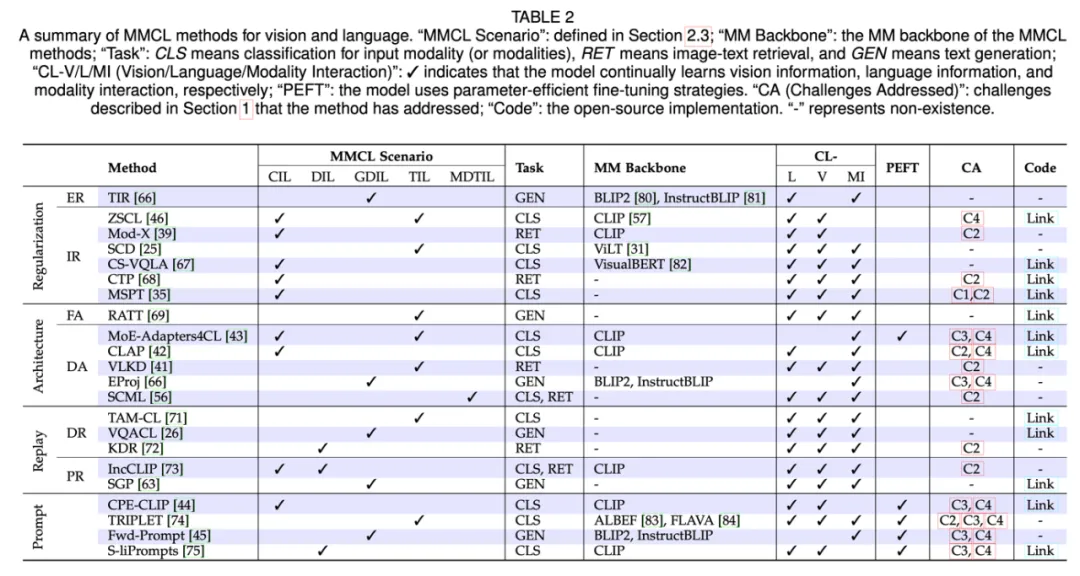
为了应对上述挑战,研究人员越来越关注 MMCL 方法。作者将 MMCL 方法分为四类主要方法,即基于正则化、基于架构、基于重放和基于提示的方法。
- 基于正则化的方法:由于训练中参数的自由移动导致灾难性遗忘,基于正则化的方法旨在对参数施加约束来减少遗忘。
- 基于架构的方法:该类方法使用不同的模型参数处理不同的任务。基于正则化的方法共享所有参数来学习任务,这使得它们容易受到任务间干扰:即记住旧任务会严重干扰新任务的学习,导致性能下降,尤其是在前向知识转移为负时。相比之下,基于架构的方法通过引入特定于任务的组件来减少任务间干扰。
- 基于重放的方法:该类方法利用一个情节记忆缓冲区来重放来自先前任务的历史实例,例如数据样本,从而帮助在学习新任务时保持早期知识。这种重放实例的方法避免了基于正则化的方法的严格约束,并规避了在架构基于的方法中动态修改网络架构的复杂性。
- 基于提示的方法:随着大型模型的快速发展及其在连续学习环境中的应用,基于提示的方法最近应运而生,以更好地利用预训练过程中获得的丰富知识。这些方法的优势在于只需最小的模型调整,减少了广泛微调的需求,而与之前通常需要显著微调或架构修改的方法不同。基于提示的方法的范式通过在连续空间中应用少量提示参数来修改输入,使得模型在学习额外的特定任务信息时能够保留其原有知识。
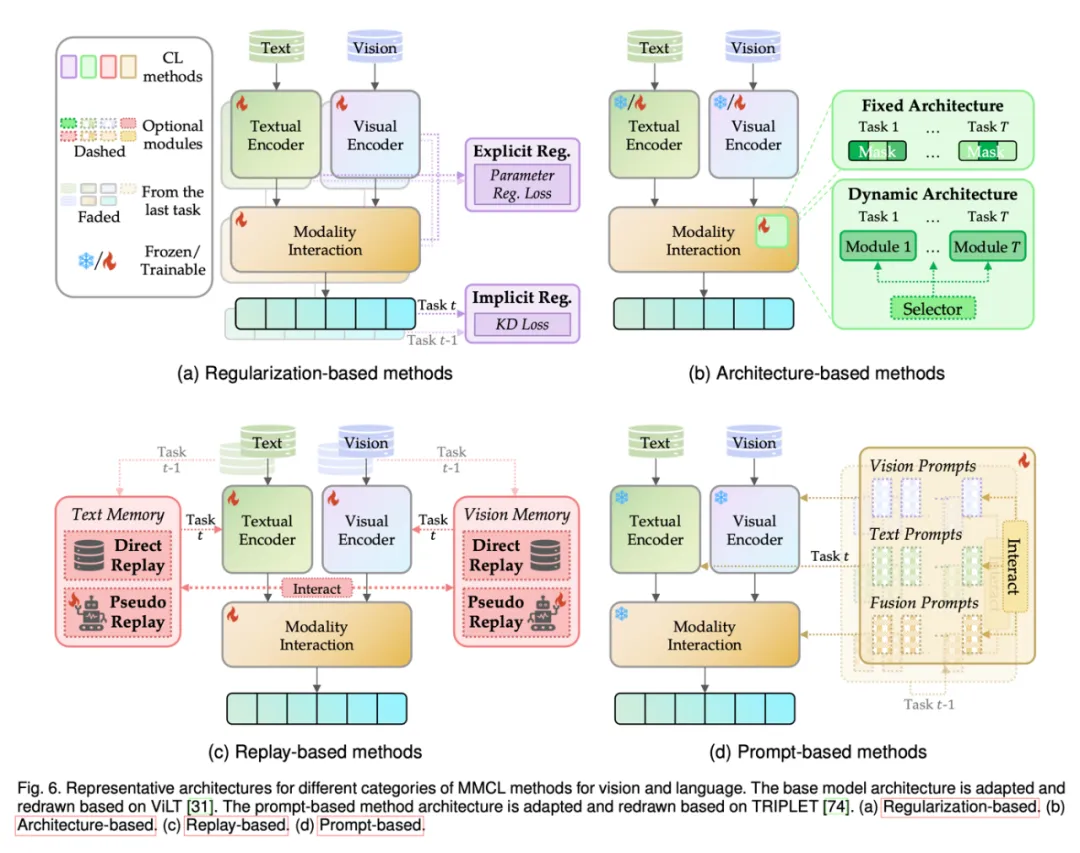
这些方法主要集中用于视觉和语言模态,同时也有其他方法关注图、音频等其他模态。下图中展示了 MMCL 方法的代表性架构。
以下两张表总结了 MMCL 方法的详细属性。
数据集和基准
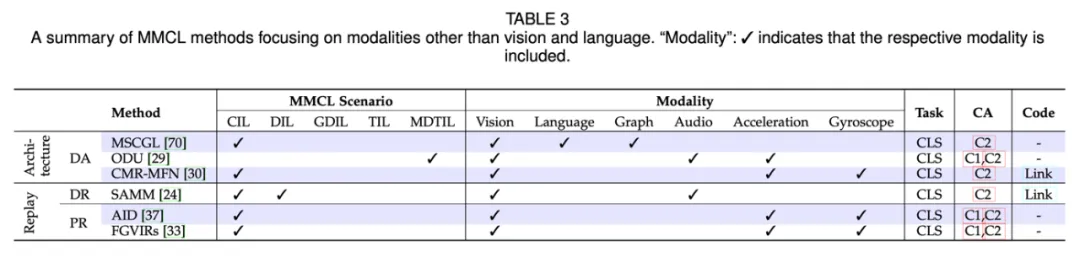
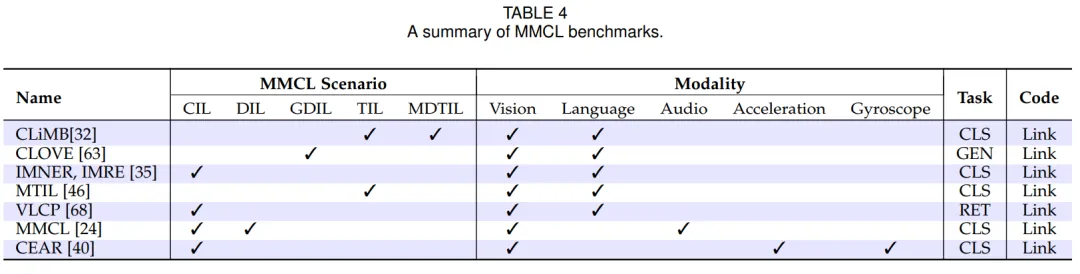
大多数 MMCL 数据集是从最初为非连续学习任务设计的知名数据集中改编而来的,研究人员通常会利用多个数据集或将单个数据集划分为多个子集,以模拟 MMCL 环境中的任务。此外,也存在一些专门用于 MMCL 的数据集,例如 P9D 和 UESTC-MMEA-CL。下表总结了涵盖各种连续学习场景、模态和任务类型的 MMCL 基准。
未来方向
多模态连续学习已成为一个活跃且前景广阔的研究主题。以下是几个未来进一步探索和研究的方向。
- 提高模态的数量与质量:表 3 中显示,只有少数 MMCL 方法关注视觉和语言以外的模态。因此,在整合更多模态方面还有巨大的研究空间。此外,模态并不限于表 3 中列出的内容,还可能包括生物传感器、基因组学等,从而增强对新兴挑战的支持,尤其是在科学研究中的人工智能应用(AI for science)。
- 更好的模态交互策略:许多现有的 MMCL 方法仅仅在网络架构中融合模态,而没有深入理解或分析它们在训练中的相互影响。因此,测量这种跨模态影响将是一个有趣且有前景的研究方向,以实现更细粒度的多模态交互。
- 参数高效微调的 MMCL 方法:参数高效微调(PEFT)方法提供了一种有效的解决方案,以优化训练成本。虽然基于提示的方法是参数高效的,但在表 2 中可以看到,其他类别中仅有 MoE-Adapters4CL 利用了 PEFT 方法。因此,考虑到近年来涌现出众多 PEFT 方法,将它们应用于减少 MMCL 方法的训练成本是一个值得探索的方向。此外,除了简单地应用现有 PEFT 方法,一个有前景的方向是为 MMCL 设置提出新的 PEFT 方法,并将其与其他 MMCL 技术良好集成。
- 更好的预训练知识维护:由于许多 MMCL 方法使用了强大的多模态预训练模型,因此在训练过程中自然希望能够记住其预训练知识。遗忘预训练知识可能会显著影响未来任务性能。
- 基于提示的 MMCL 方法:基于提示的 MMCL 方法能有效应对挑战 3:高计算成本,以及挑战 4:预训练零样本能力退化。然而,如表 2 所示,基于提示的 MMCL 方法目前是最少的一类。鉴于基于提示的方法仍处于起步阶段,因此进一步研究和发展的潜力巨大。
- 可信赖的多模态连续学习:随着人们越来越关注隐私以及政府实施更多相关法规,对可信赖模型的需求正在上升。诸如联邦学习(FL)等技术可以被用于使服务器模型在不共享原始数据的情况下学习所有客户端的数据知识。随着众多联邦连续学习(FCL)方法的发展,将 FCL 方法扩展到 MMCL 将是一个有前景的发展方向,从而增强 MMCL 模型的可信赖性。
总结
本文呈现了一份最新的多模态连续学习(MMCL)综述,提供了 MMCL 方法的结构化分类、基本背景知识、数据集和基准的总结。作者将现有的 MMCL 工作分为四类,即基于正则化、基于架构、基于重放和基于提示的方法,还为所有类别提供了代表性的架构示意图。此外,本文讨论了在这一快速发展的领域中有前景的未来研究方向。希望 MMCL 的发展进一步增强模型使其展现出更多人类的能力。这种增强包括在输入层面处理多模态的能力以及在任务层面获取多样化技能,从而使人们更接近于在这个多模态和动态世界中实现通用智能的目标。
文章来自于“机器之心”,作者“余甸之、张欣妮、陈焱凯、刘瑷玮、张逸飞、Philip S. Yu、Irwin King”。




