# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
新一代通用灵活的网络结构 TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters 来啦!
TokenFormer 不仅像原始 Transformer 一样 Token 化了 input data,并且 Token 化了网络参数,将 attention 机制拓展到 Token 和 parameters 的交互中,最大化了 Transformer 的灵活性,真正得到了一个 Fully attention-based 的网络结构。
这种方式打破了原有人们区别看待 data 和 model 的观念,即所有的计算都归纳为不同类型的 Token(e.g., data, param token)通过灵活的 attention 来交互。得益于这一灵活的性质,TokenFormer 允许 incremental scaling model size,基于训好的模型上增量的拓展新的更大的模型,大大节省了计算的开销:
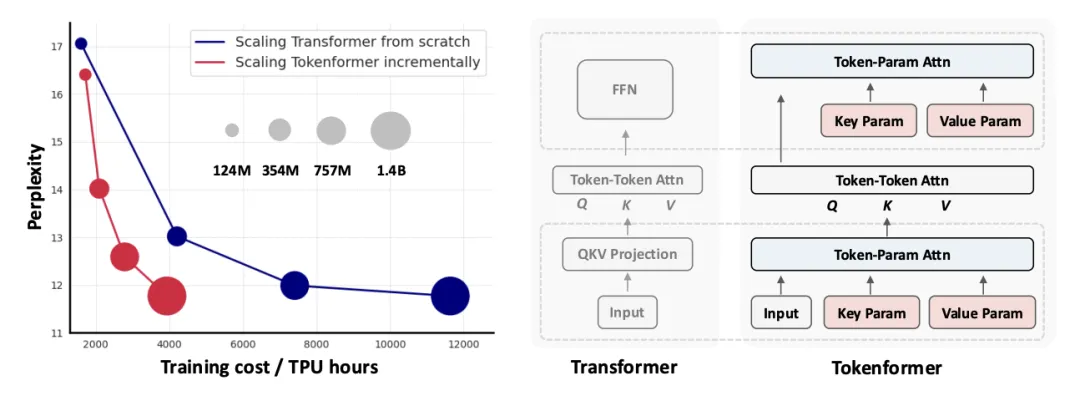
这项名为 TokenFormer 的新工作,由谷歌,马普计算所和北大的研究者提出,在 Twitter,HackerNews, Reddit 上得到广泛的讨论和关注 (Twitter 上有 150K + 的浏览量)。

目前代码、模型和项目主页均已放出:
得益于其处理各种数据的灵活性,Transformer 网络结构在各个 AI 领域都取得了巨大的成功。
Transformer 模型通常将处理单个 Token 所需的计算分为两个部分:与其他 Token 的交互(Token-Token Interaction)和涉及模型参数的计算(Token-Parameter Interaction)。
Attention 促进了 Token-Token 之间的交互,使现代通用基础模型能够将多模态数据编码成统一的 Token 序列,并有效捕捉它们之间的复杂依赖关系。
相反,Token-Parameter 计算主要依赖于固定的 linear projection,大大限制 model size 的 scaling。Scaling model 是通常改变模型结构,往往需要从头训练整个模型,带来了过多的资源消耗,使其越来越不切实际。
在本文中,研究团队使用 token 这一概念建模所有的计算,即将 model parameters 也视为一种 token,网络的计算统一为各种不同的 token ( e.g., data tokens and parameter tokens) 之间通过 attention 来进行交互,大大增强了 Token-Parameter 交互的灵活性,从而能够增量式的扩展模型参数,有效地重用先前训练的模型,从而显著降低了训练负担。
为实现这一目标,研究团队引入了 TokenFormer。统一 Token-Token 和 Token-Parameters Interaction 的计算。其 Token-Parameter attention 具有灵活性,并能够处理可变数量的参数,从而本质上最大化了 Transformer 的灵活性,增强了模型的可扩展性。
TokenFormer 提供一种新的看待模型的视角,即网络的计算就是一些 Tokens 相互任意交互。基于这些 Tokens (e.g., data token, parameter token, memory token)和 attention 机制可以灵活地构造任意的网络结构。
该团队希望 TokenFormer 作为一种通用的网络结构,不仅在 incremental model scaling 上有贡献,还在 Sparse Inference, Parameter-Efficient Tuning, Vision and Language Models, Device-Cloud Collaboration 和 Model Interpretability 等领域有更多的贡献。
Tokenformer 的核心创新是 Token-Parameter Attention(Pattention) Layer,它结合了一组 Trainable Tokens 作为 model parameters,并通过 cross-attention 来管理 Input Token 与这些 Parameter Tokens 之间的交互。
通过这种方式,Pattention 层引入了一个额外的维度 —Parameter Token 的数量,这一维度独立于输入和输出维度。此解耦方式使得输入数据可以与 variable number of parameters 进行交互,提供了增量模型扩展所需的灵活性。


研究团队使用 Pattention Layer 替换掉标准 Transformer 中的所有的 linear projection,最大化 Transformer 的灵活性。
有了 TokenFormer 这一灵活的性质,可以延伸出很多应用。这里以增量式 model scaling 为例。
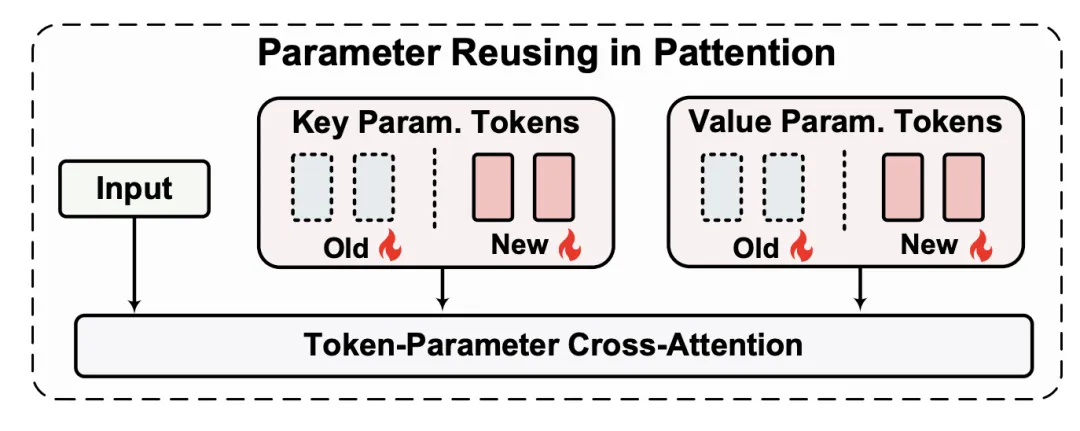

这里直观的理解就是每个 Key-Value 代表一种学好的 pattern,其组成一个巨大的知识库。文中的 incremental scaling 就是在原有的知识库上进一步拓展训练。
增量式 model scaling:如下右图所示,模型在已经训好的 124M 的模型的基础上,采用增量式训练,只用十分之一的数据就可以达到从头训练策略相近的性能,让模型可以不断迭代,真正地活起来了。
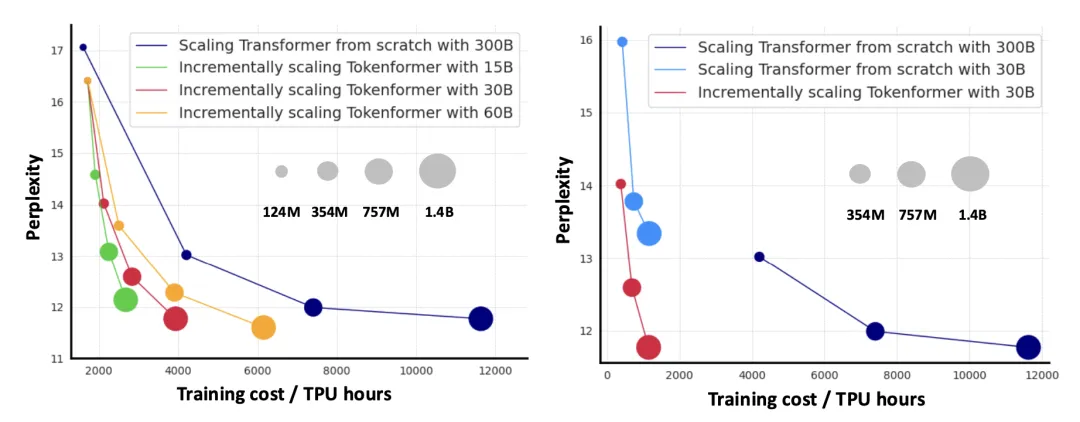
Language Modeling:如下表所示,研究团队比较了 Transformer-based 的模型和 TokenFormer 在语言建模上的能力。
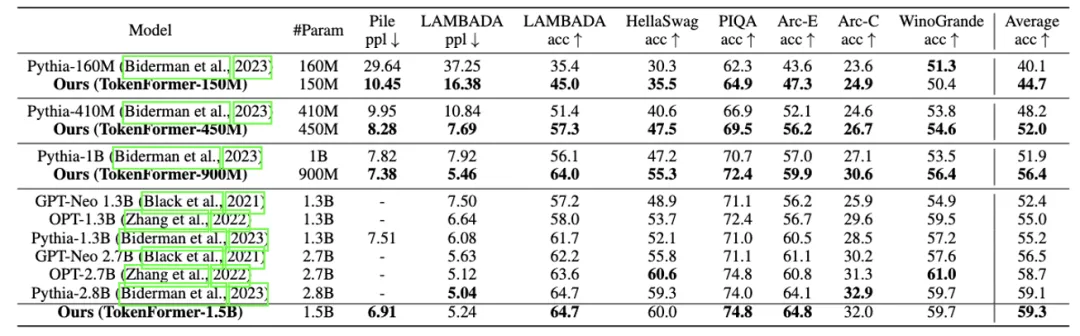
在相同规模、相同模型尺寸下, TokenFormer 在大大增加灵活性的前提下达到了比 Transformer 更好的 zero-shot 性能。这里研究团队 follow 了 pythia 标准的训练代码以及数据集:Pile (300B)。上述结果展现了 TokenFormer 在语言模型建模上的能力。
Visual Modeling: 为了进一步验证 TokenFormer 的表达能力,研究团队还和标准的 vision transformer 进行了对比。
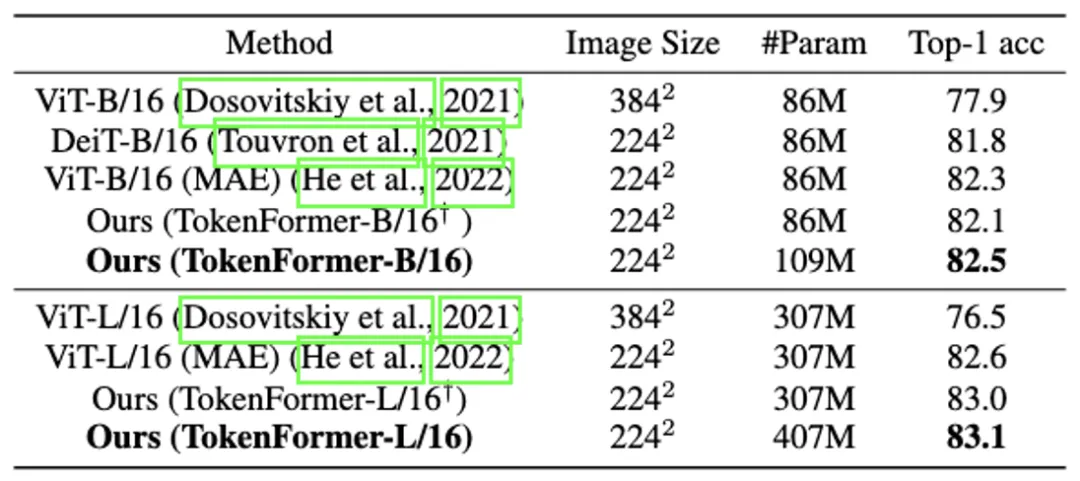
在 ImageNet-1K 的监督训练的 setting 上,使用相同的训练策略, TokenFormer 的性能超过了 vision-transformer,验证了其在 visual modeling 上的能力。
研究团队认为 Tokenformer 是专家混合(MoE)框架的极致实例化,其中每一组键 - 值参数对都充当一个独立的专家。这种创新的类 MoE 架构有可能显著减少与 Token-Parameter 交互相关的计算成本。
Tokenformer 的扩展方法通过集成额外的 key-value parameter pairs,展现了一种参数高效的微调策略。当面对新任务或数据集时,该模型可以通过加入新的 Token Parameters 来扩展其预训练参数,从而快速适应特定任务需求。
利用 Tokenformer 的参数高效微调能力,可以实现视觉和语言模态的无缝集成。具体方法是将预训练的 Visual Tokenformer 和 Language Tokenformer 的 key-value parameter Tokens 统一为一个参数集,然后引入新的 Trainable Tokens 来执行视觉 - 语言对齐和指令微调。
Tokenformer 可以在设备 - 云协作中充当云端知识库,为设备端的大语言模型(LLM)提供支持,其中每组 key-value parameter tokens 代表一个可学习模式,通过设备进行实时处理,并利用云端执行密集任务。
由于 Tokenformer 完全基于注意力机制,它自然受益于在 Token-Parameter 交互中与注意力相关的可解释性特性。这一特点增强了模型的可解释性,为 AI 社区开发更透明、易理解的模型贡献力量。
文章来自于“机器之心”,作者“汪海洋”。



【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
