# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现在,随便丢给机械手一个陌生物体,它都可以像人类一样轻松拿捏了——
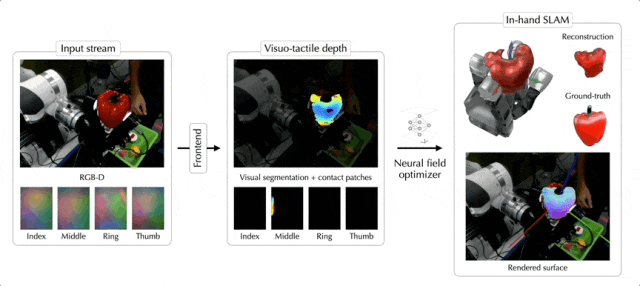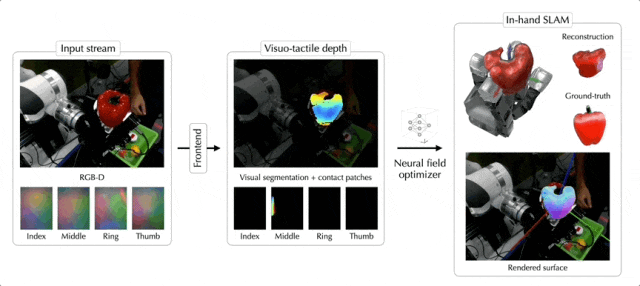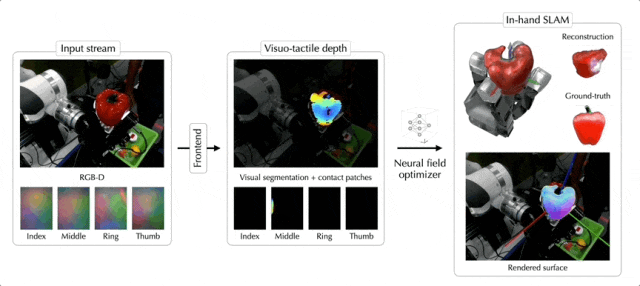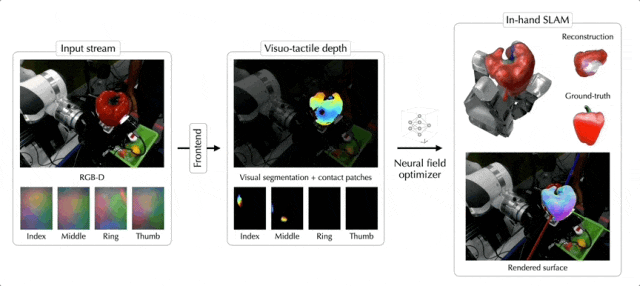
除了苹果,罐头、乐高积木、大象玩偶、骰子,都不在话下:
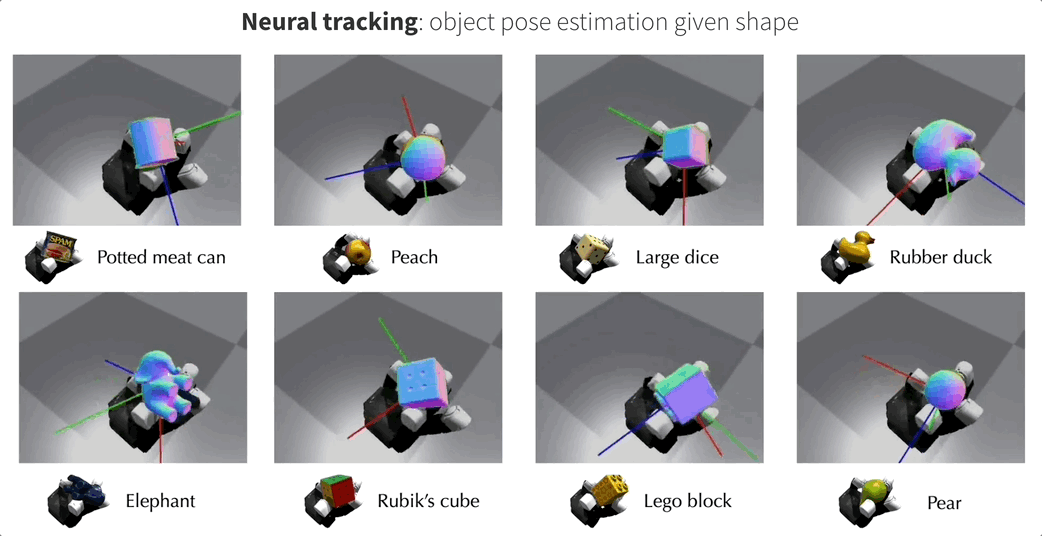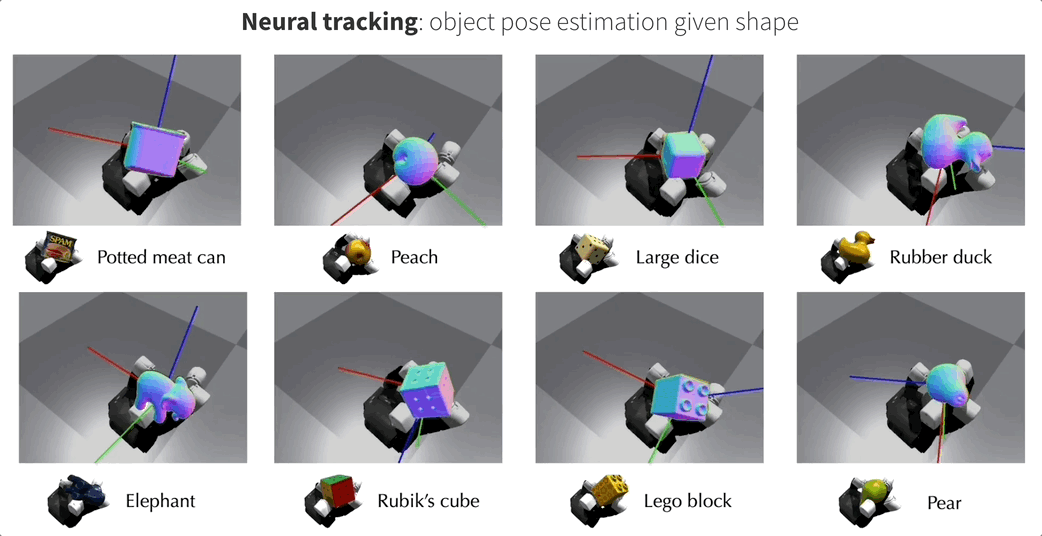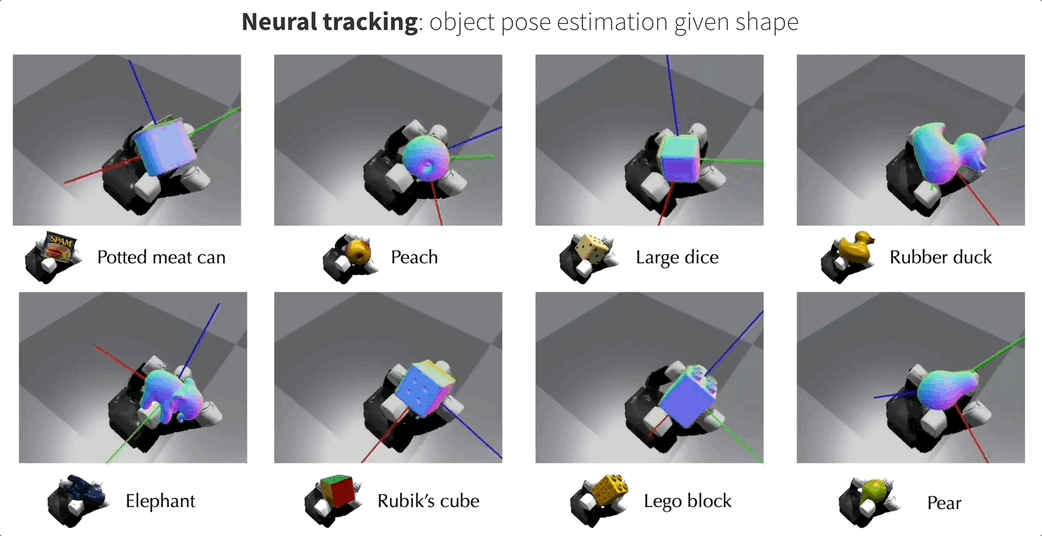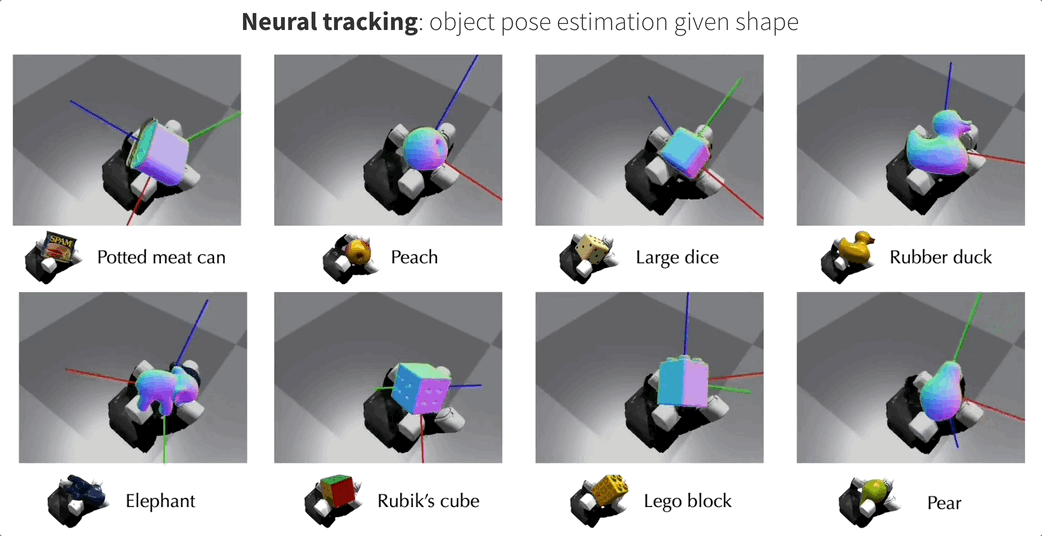
这就是来自Meta FAIR团队最新的NeuralFeels技术,通过融合触觉和视觉,机械手可以更精确地操作未知物体,精度最高提升了94%!
这项研究还登上了Science Robotics的封面,团队同时也公开了包含70个实验的新测试基准FeelSight。

让机械手拿取常见的魔方、水果等早已是基操,但如何让机器人更好地操作未知物体一直是一个研究难题。
一个重要原因是目前的机械手训练都太过于依靠视觉,并且仅限于操作已知的先验物体,而现实中很多时候物体都会受到视觉遮挡,导致训练往往进步缓慢。
对此,团队研发出一种名为NeuralFeels的创新技术,为机器人在复杂环境中的物体感知与操作带来了新的突破。
这究竟是怎么做到的呢?让我们来一起看一下技术细节——
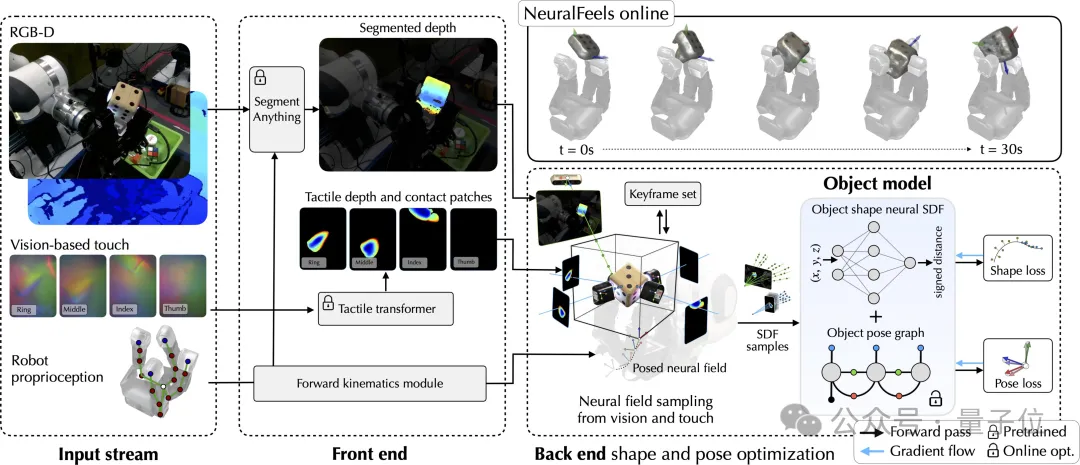
NeuralFeels技术的创新之处在于结合了视觉和触觉,通过多模态融合的方式,让机器手能够对未知物体持续进行3D建模,更精确地估计手持操作中物体的姿态和形状。
具体的处理流程如下图所示,前端实现了视觉和触觉的鲁棒分割和深度预测,而后端将此信息结合成一个神经场,同时通过体积采样进一步优化姿态。
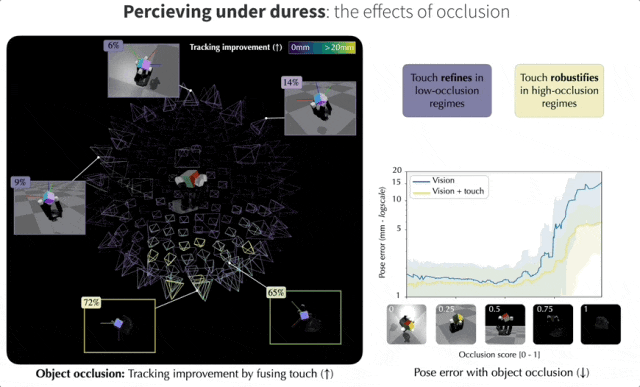
而在遮挡视角下,视觉与触觉融合有助于提高跟踪性能,还可以从无遮挡的局部视角进行跟踪。团队在摄像机视角的球面上量化了这些收益。
从下图中可以观察到,当视觉严重遮挡时,触觉的作用更大,而在几乎没有遮挡时,触觉会发挥微调作用。
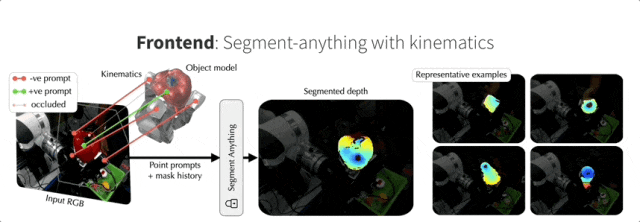
首先来看看NeuralFeels技术的前端(Front end),它采用了基于深度学习的分割策略和触觉Transformer,可以精确提取目标对象深度。
神经优化非常依赖分割对象的输入深度,所以团队将前端设计成能够从视觉中鲁棒地提取对象深度的形式。深度在RGB-D相机中是现成的,但为了应对严重遮挡的问题,团队还引入了一种基于强大视觉基础模型的动力学感知分割策略。
最近有研究表明,在自然图像中使用ViT进行密集深度预测更有效,于是团队提出了一种触觉Transformer,用于通过视觉触觉预测接触深度,这个Transformer完全在模拟中训练,可在多个真实世界的DIGIT传感器上通用。机械手可以用嵌入式摄像头直接感知发光的胶垫,通过监督学习获得接触深度。

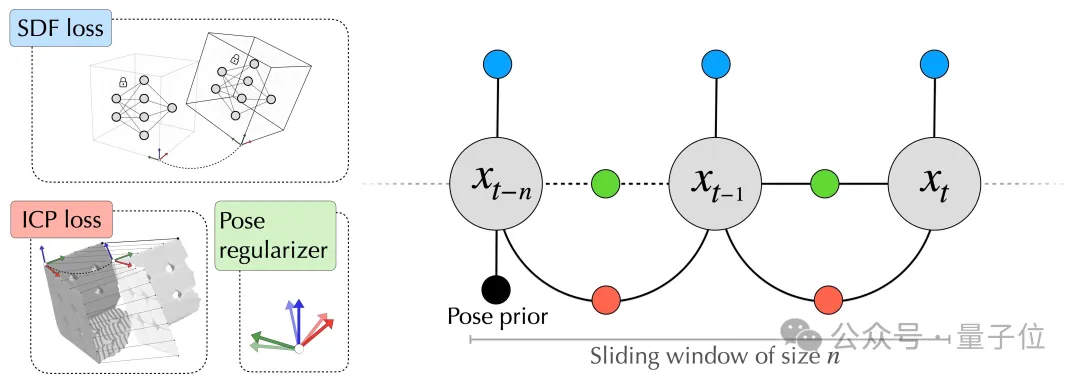
NeuralFeels的后端(Back end)部分通过使用Theseus中的自定义测量因子,将前端的中间输出转化为非线性最小二乘问题进行优化。
后端模块从前端模块得到中间输出,并在线构对象模型。这个过程将交替使用来自视觉-触觉深度流的样本进行地图和姿态优化步骤。在本研究的地图优化器中,即时NGP模型的权重可以完全描述物体的3D几何结构。
在现实世界和模拟中,团队构建了一个不断演进的神经SDF,它整合了视觉和触觉,并可以同时跟踪物体。下图展示了对应的RGB-D和触觉图像的输入流,以及相应的姿态重建。
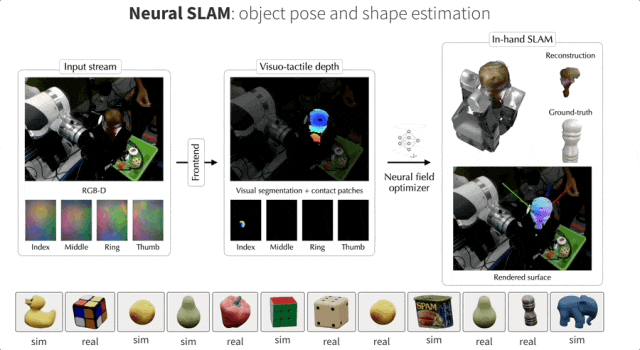
当目标对象存在对应的CAD模型时,NeuralFeels可以实现优秀的多模态姿态跟踪能力。此时目标对象的SDF模型是预先计算的,NeuralFeels会冻结神经场的权重,仅使用前端估计进行视觉-触觉跟踪。
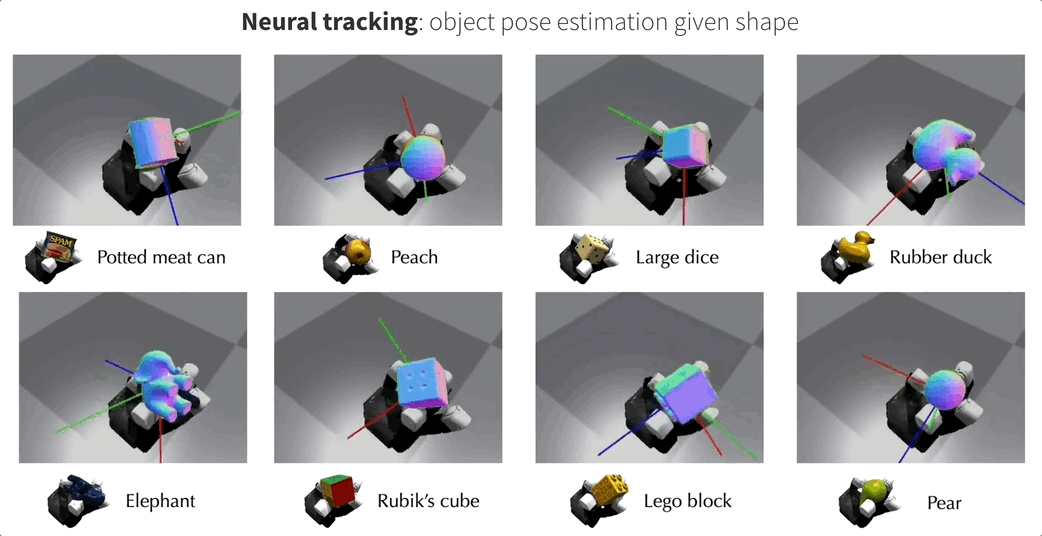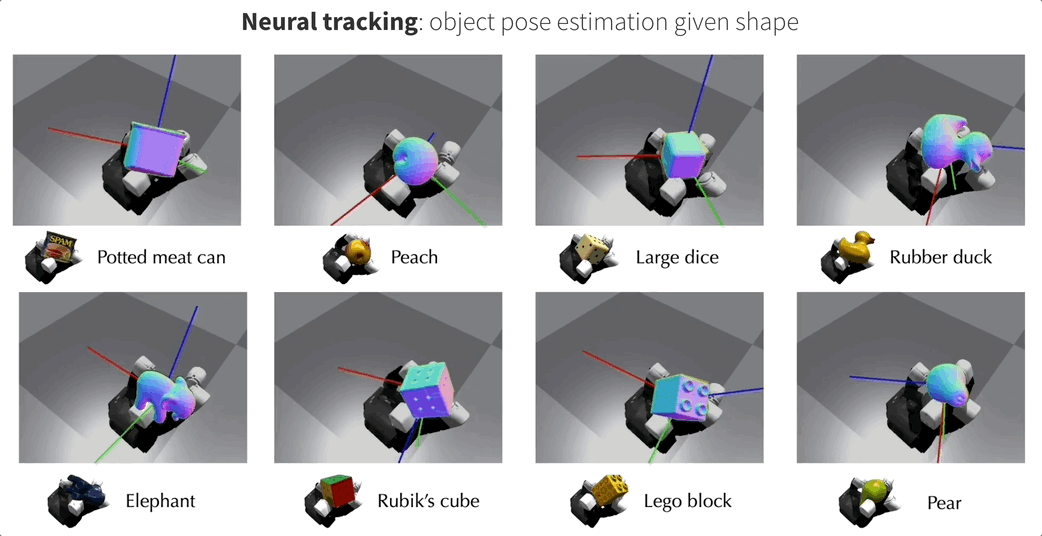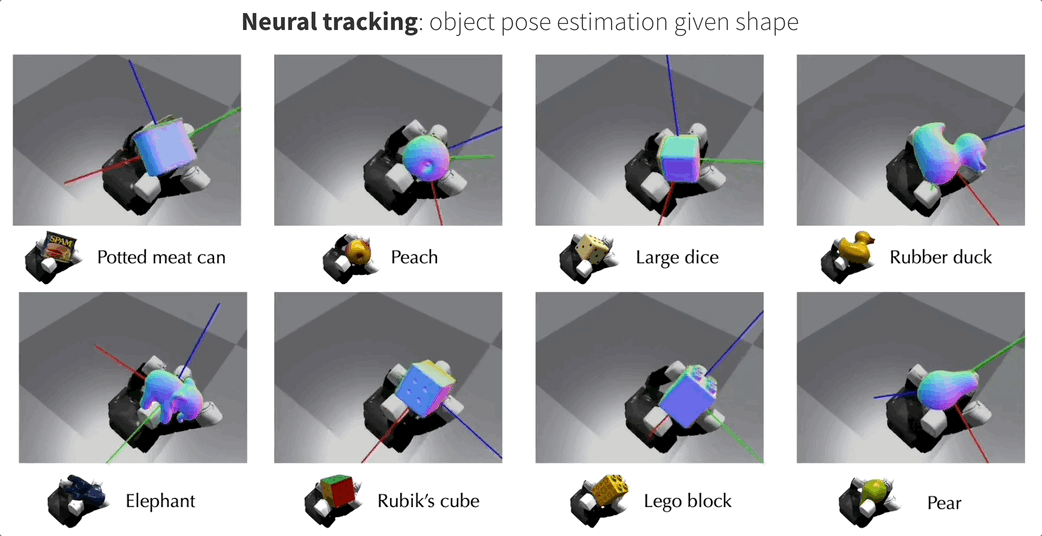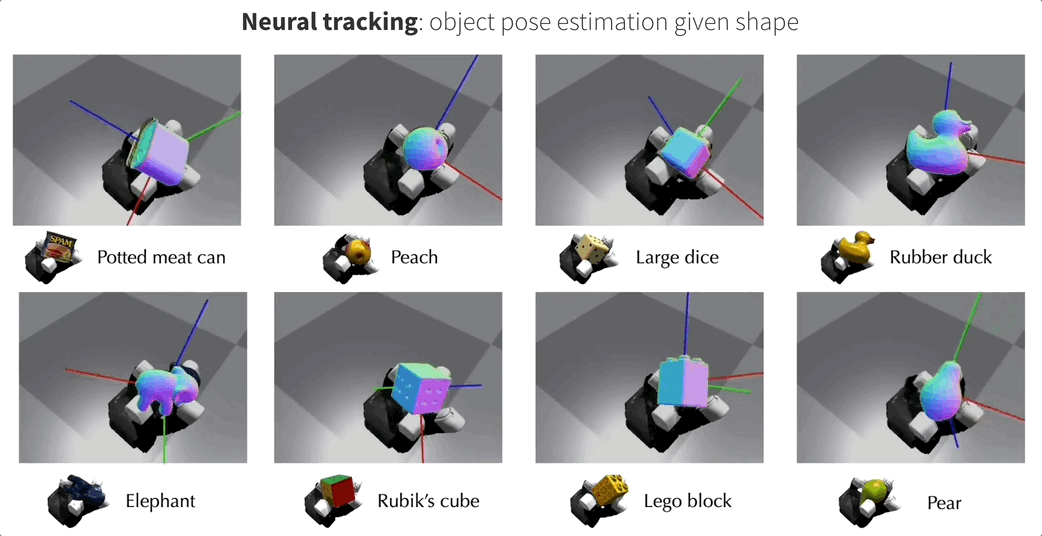
为了评估NeuralFeels技术的性能,研究团队在模拟和真实世界环境中进行了多次实验,涉及14种不同物体,相关测试集FeelSight也已发布!

实验中使用了多种评估指标,包括用于评估姿势跟踪误差的对称平均欧几里得距离(ADD-S),以及用于衡量形状重建精度和完整性的F分数等。
结果非常令人惊喜,NeuralFeels技术在以下3个方面都有非常出色的表现:
在物体重建方面,研究发现结合触觉信息后,表面重建精度在模拟环境中平均提高了15.3%,在真实世界中提高了 14.6%。
最终重建结果在模拟环境中的中位误差为2.1毫米,真实世界中为3.9毫米。这表明NeuralFeels技术能够有效地利用触觉信息补充视觉信息,更准确地重建物体形状。

在物体姿态跟踪方面,NeuralFeels技术相比仅使用视觉信息的基线方法有显著改进。
在模拟环境中,姿态跟踪精度提高了21.3%,真实世界中提高了26.6%。
在已知物体形状的姿态跟踪实验中,即使存在不精确的视觉分割和稀疏的触摸信号,该技术也能实现低误差的姿态跟踪,平均姿态误差可降至2毫米左右。
并且,触觉信息在降低平均姿态误差方面发挥了重要作用,在模拟环境中可使误差降低22.29%,在真实世界中降低 3.9%。
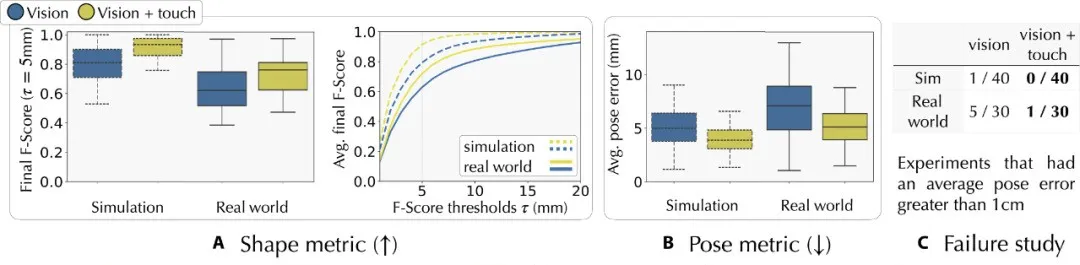
在面对严重遮挡和视觉深度噪声等具有挑战性的场景时,NeuralFeels技术同样表现非常出色。
在模拟的200个不同相机视角的遮挡实验中,平均跟踪性能提升 21.2%,在严重遮挡情况下提升幅度可达94.1%!
在视觉深度噪声模拟实验中,随着噪声增加,融合触觉信息能有效降低误差分布,使机器人在视觉信息不理想的情况下仍能准确跟踪物体姿态。
NeuralFeels技术的创新之处在于它融合了多模态数据、并结合了在线神经场,这些技术让机器人能够在操作未知物体时实现更准确的姿态跟踪和形状重建。
而且,与复杂的传感器相比,团队使用空间感知组合所需的硬件更少,也比端到端感知方法更容易解释。
尽管目前在一些方面仍存在改进空间,如在长期跟踪中由于缺乏闭环检测可能导致小误差累积,但对于提升机械手操作精度的效果非常显著,
未来,研究人员计划进一步优化技术,例如通过基于特征的前端获取更粗略的初始化,加入长期闭环检测以减少姿态误差的累积,通过控制神经SLAM的输出进行通用灵巧性研究等。
这样一来,家庭、仓库和制造业等复杂环境中作业的机器人的性能都有可能得到极大的提升了!
参考资料:
[1]https://www.science.org/doi/10.1126/scirobotics.adl0628
[2]https://suddhu.github.io/neural-feels/
文章来自于“量子位”,作者“奇月”。



【开源免费】LGM是一个AI建模的项目,它可以将你上传的平面图片,变成一个3D的模型。
项目地址:https://github.com/3DTopia/LGM?tab=readme-ov-file
在线使用:https://replicate.com/camenduru/lgm
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
