# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大规模语言模型(LLMs)已经在自然语言处理任务中展现了卓越的能力,但它们在复杂推理任务上依旧面临挑战。推理任务通常需要模型具有跨越多个步骤的推理能力,这超出了LLMs在传统训练阶段的表现。
图片由修猫制作
为了解决这一问题,Salesforce研究团队提出了一个全新的推理优化框架——LaTent Reasoning Optimization(LaTRO),通过引入自我奖励机制来激发LLM潜在的推理能力。在多个基准数据集上,LaTRO实现了高达12.5%的准确率提升。本文将从方法原理、实验过程、实验结果、以及潜在应用等多个方面对这项研究进行详细介绍。

当前的大规模语言模型(如GPT-3、LLaMA等)在文本生成和语言理解任务中已经取得显著的成功。然而,尽管这些模型在特定任务上表现良好,它们在多步骤推理(如数学推理、逻辑推理)中却表现不尽如人意。主要原因在于其基于下一个词预测的机制,这使得它们很难有效地完成复杂的推理任务,尤其是那些需要逐步积累知识并得出结论的问题。
例如,传统的提示工程方法(如链式思维提示法,即Chain-of-Thought, CoT)在推理任务中能够一定程度地提高模型的推理能力,但这种改进主要体现在推理过程的表面结构上,并没有深入优化模型的推理“内核”。
虽然像CoT和其扩展(如CoT自我一致性,CoT-SC)等推理方法在推理过程中产生了一些改进,但这些方法大多集中于推理的推断时间优化,而对训练阶段的推理能力提升研究相对较少。同时,这些方法往往需要额外的数据标注或外部反馈模型,这不仅增加了训练的复杂性,也增加了数据需求。尤其是在缺乏标注数据的情况下,模型的泛化能力也受到限制。
因此,为了克服这些问题,Salesforce团队提出了一种新的优化推理能力的方法,LaTRO框架,它将推理过程视作一个隐变量分布的采样和优化问题,并通过变分优化和自我奖励机制来实现模型推理能力的提升。
LaTRO(LaTent Reasoning Optimization)框架的核心在于将语言模型的推理过程视为一个隐含推理路径的优化问题,并利用自我奖励机制提升模型的推理能力。LaTRO的关键理念是:大规模语言模型具有潜在的推理能力,这种能力可以通过合理的优化策略来进一步激发和利用。
LaTRO将推理视为从一个隐变量分布中采样的过程,并利用变分优化的技术来进行训练。在传统的LLM训练中,模型通常通过最大化目标数据的似然来进行优化,这种方式对于直接回答问题效果较好,但在多步骤推理上并不足够。而LaTRO框架通过引入一个“推理者”(reasoner),即隐变量分布,来生成潜在的推理路径,并对这些路径进行优化。
具体来说,LaTRO引入了一个推理过程的变分下界,通过优化该下界来使模型逐步逼近正确的推理路径。推理者在这个过程中不仅生成推理路径,还通过计算路径的似然性来评估路径的质量。为了简化过程,研究者提出使用模型本身作为推理者,并同时优化生成推理路径和答案的能力。
LaTRO的另一个核心部分是自我奖励机制。不同于传统的通过外部反馈(如人类标注)来奖励模型的方式,LaTRO的自我奖励机制利用模型自身的概率估计来对推理路径进行评分。简而言之,模型在生成推理步骤后,会根据每个推理步骤的有效性给予正向或负向的奖励。这种自我奖励机制能够激励模型生成更优质的推理路径,从而提高整体推理能力。
1.推理路径提升正确率:研究发现,语言模型在生成良好的推理路径后,生成正确答案的概率显著提高。这表明,通过优化推理路径,模型可以更好地理解和解决问题。
2.自我评估能力:语言模型不仅能够生成推理过程,还能评估其质量。这意味着我们不再需要依赖外部奖励模型,模型自身可以承担评估者的角色,提高了推理的独立性和灵活性。
3.显著的性能提升:在GSM8K数据集上,LaTRO方法使得零样本推理的准确率平均提升了12.5%,这证明了通过训练阶段的优化可以显著提升模型的推理能力。
为了验证LaTRO的有效性,研究者们在多个经典推理数据集上进行了实验,包括数学推理数据集GSM8K和逻辑推理数据集ARC-Challenge。这些数据集涵盖了不同类型的推理任务,旨在全面评估模型在多种复杂推理任务中的表现。
实验采用了三种基础模型进行微调,包括Phi-3.5-mini、Mistral-7B和Llama-3.1-8B,并对比了基线模型(未优化)和监督微调模型(SFT)在推理任务上的表现。研究者们特别测试了零样本推理情况下LaTRO模型的性能,以评估其在缺乏额外标注的情况下对推理能力的提升效果。
实验分为以下几个步骤:
实验结果显示,在引入LaTRO框架后,模型在多个推理任务中均取得了显著提升,特别是在需要多步骤推理的任务中,模型的零样本推理准确率平均提高了12.5%。对于GSM8K数据集,LaTRO微调模型的表现超过了基线模型19.5%,在一些情况下甚至比监督微调模型表现更佳。
在GSM8K数据集上的详细性能对比如下:

此外,错误类型分析显示,通过引入LaTRO框架,计算错误减少了63%,推理路径不完整的情况减少了71%,逻辑跳跃导致的错误减少了58%。这表明LaTRO在纠正模型推理中的常见错误方面也有显著作用。
对于ARC-Challenge数据集,LaTRO框架虽然提升幅度相对较小,但依然表现出了对基线模型和SFT模型的超越。特别是在自我一致性推理(即通过生成多条推理路径并进行投票)中,LaTRO框架显示了进一步提升推理准确率的潜力。
实验还分析了推理路径的长度对结果的影响,发现500 tokens的推理长度是最优的平衡点,能够在性能和计算开销之间取得较好的权衡。此外,实验还表明,多样本采样(如8个采样)可以进一步提高推理准确率,但在增加到16个样本后,边际收益显著下降。
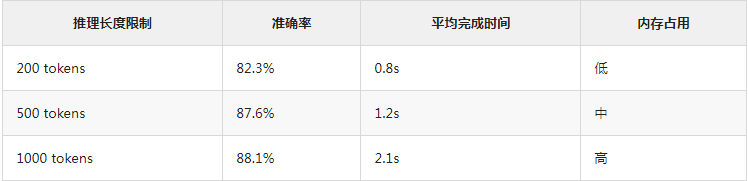
实验结果还显示,多样本采样策略能够显著提升模型推理的一致性和准确率:

主要发现是8个样本提供了最佳的性能与开销比,而增加到16个样本时,边际收益变得非常有限。
对于Prompt工程师来说,LaTRO框架提供了一种全新的思路来激发LLM的推理能力。传统上,Prompt工程师往往通过精细设计的提示来引导模型生成更合理的推理过程,而LaTRO的自我奖励机制则进一步赋予了模型“自我修正”的能力,使其能够在推理过程中逐步优化和改进自身。
在实践中,您可以结合LaTRO框架,设计更加灵活的提示和反馈机制,使模型能够自我完善推理路径,从而更高效地解决复杂推理问题。

尽管LaTRO框架在推理能力的提升上取得了显著成果,但也面临着一些挑战。例如,在极大型模型上引入自我奖励机制可能会导致计算开销的增加,尤其是在需要频繁采样和评估推理路径的情况下。此外,如何进一步提升自我奖励的稳定性,以及如何将LaTRO框架扩展到更多的推理任务和领域中,都是需要进一步研究的重要方向。
Salesforce研究团队通过LaTRO框架证明,大规模语言模型不仅具备潜在的推理能力,而且可以通过自我奖励机制激发和优化这种能力。LaTRO在推理任务中的平均性能提升了12.5%,为未来大规模语言模型的训练和优化提供了全新的视角。它展示了如何在没有外部反馈的情况下,通过自我优化来提升模型的推理能力。
文章来自于微信公众号“AI修猫Prompt”,作者“ AI修猫Prompt”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
