# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

破解基因组的奥秘一直是生物科学的前沿挑战,如何让人工智能(AI)读懂 DNA 的复杂信息,并用它来设计和操控生命的“程序代码”?
通过深度学习算法,AI 不仅能识别基因组中细微的模式,还可以生成完整的基因序列,为基因编辑和新药开发提供前所未有的支持。
今日凌晨,斯坦福大学化学工程助理教授 Brian L. Hie 团队以封面文章的形式在权威科学期刊 Science 上发表了一项开创性研究成果 —— Evo,一个能够解码和设计 DNA、RNA 和蛋白质序列的大规模基因组基础模型。

据介绍,Evo 模型基于 3000 亿 DNA token 训练,能够在长序列的单碱基分辨率下进行预测和生成,尤其在跨物种的基因预测上取得了超越特定模型的表现。
Evo 模型专为捕捉生物学中两个核心方面:中心法则的多模态性和进化的多尺度特性。中心法则揭示了 DNA、RNA 和蛋白质的统一信息流,而进化跨越了分子、途径、细胞到生物体的各个层级。
研究发现,Evo 生成的多基因系统成功率接近 50%,生成的 CRISPR-Cas9 蛋白也经实验验证具有功能活性。此外,在全基因组生成方面,Evo 生成的序列在基因组组织、编码密度和天然基因组方面显示出高度的相似性。
Evo 不仅能够预测基因突变的效应,还具备生成完整基因组序列的能力,在基因组设计、药物开发和生物工程领域具有广阔的潜力。
美国 Gladstone 心血管病研究所的 Christina V. Theodoris 在一篇文章中评论道:“Evo 的意义在于,首次从进化多样性中提取出 DNA 的‘语法规则’,将基因组信息的建模提升到一个新的层次。”
基因组序列的演化过程展现了生物体对环境的适应与选择,随着基因组测序技术的发展,人类逐步掌握了绘制和解析基因组多样性的能力,从而揭示了基因在健康、疾病和生物适应性中的关键角色。
DNA 作为遗传信息的载体,通过四种碱基(A、T、G、C)序列记录了生物体的生命指令。
Theodoris 在评论文章中指出:“DNA 尽管只有四种碱基的 ‘词汇’,却像一种语言,编码了调控细胞各层级活动的基础信息,从DNA、RNA到蛋白质。这些信息在指导细胞功能的同时,代代相传,驱动生物体的进化。”
Theodoris 指出,正是这种进化多样性中的 DNA 序列对比,赋予了大型语言模型学习 DNA 语法的潜力,而这一能力是此前基于单一基因组的模型难以掌握的。
然而,建模基因组信息仍面临显著挑战。当前的机器学习模型多聚焦于特定分子(如蛋白质、RNA),在长 DNA 序列的生成与预测上存在局限性,尤其是在涉及基因调控和 CRISPR 免疫等复杂系统的多分子、多尺度应用中。例如,基于 Transformer 的 DNA 模型受限于较短的上下文长度,多采用将核苷酸聚合成语言模型基本单元的方法,牺牲了单碱基分辨率。
为应对这些挑战,研究团队借鉴自然语言处理模型在长文本预测与生成中的成功案例,开发了 Evo 模型。
Evo 采用了混合模型架构 StripedHyena,巧妙地将数据控制的卷积算子与多头注意力机制相结合,克服了传统 Transformer 架构在长序列 DNA 处理中的计算成本和分辨率问题,实现了在单碱基分辨率下对长达 131072 个 token 的上下文长度的高效处理,极大提升了基因组分析的精确性和效率。
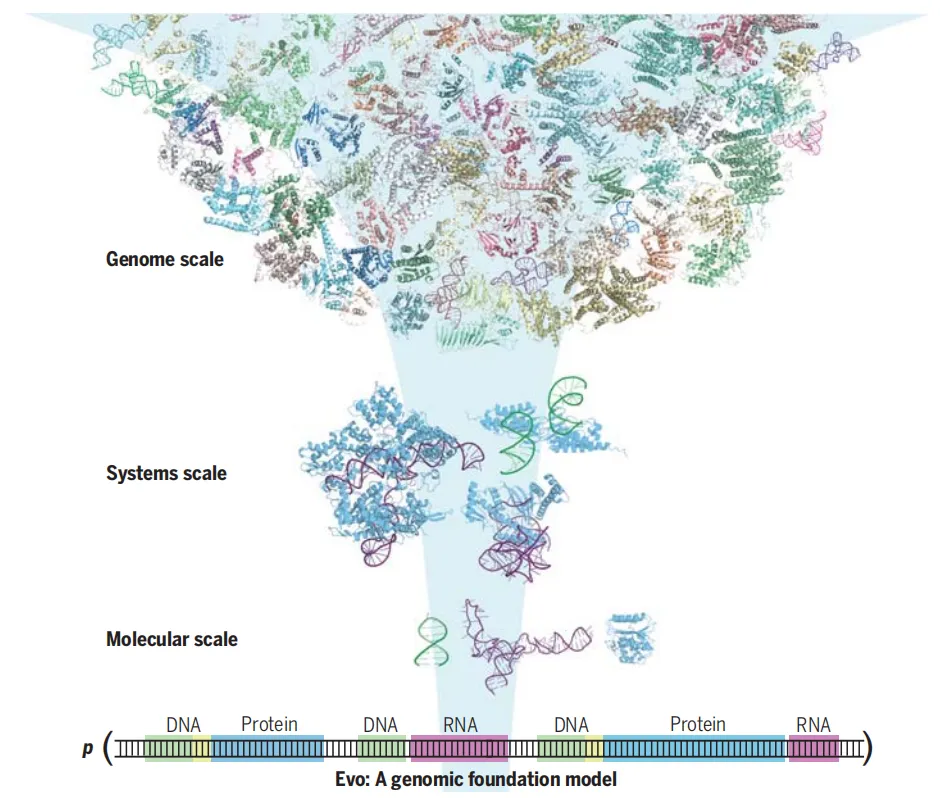
图|拥有 70 亿个参数的基因组基础模型 Evo ,可学习从单个核苷酸到整个基因组的生物复杂性。
Evo 模型使用 OpenGenome 大型数据集进行训练,该数据集包含超过 80000 个细菌和古菌基因组以及数百万个预测的噬菌体和质粒序列,涵盖 3000 亿个核苷酸 token。训练分两个阶段,先使用 8192 个 token 上下文长度,再扩展到 131072 个 token 上下文长度,参数规模达 70 亿。
通过预训练,使得 Evo 在预测突变对蛋白质和非编码 RNA 功能影响时,能够全面考虑分子间的协同作用,为基因突变的精确预测提供了可能性。
DNA 编码与自然语言中的单词和句子不同,DNA 是连续的,包含了重叠的多重信息。Theodoris 在评论文章中指出,“突变可能影响这些信息中的任何一层,因此大型语言模型需要在单核苷酸分辨率下操作,以全面理解 DNA 信息的复杂性。”
Evo 模型在单核苷酸分辨率下操作的能力,正是应对这种复杂性的核心。
研究人员对 DNA 序列建模进行 scaling laws 分析,比较了 Transformer++、Mamba、Hyena 和 StripedHyena 等多种架构。结果显示,StripedHyena 在不同计算预算下表现出更优的缩放率,能稳定训练,且在计算最优前沿之外的性能也较好,这为选择该架构作为 Evo 的基础提供了依据。
Theodoris 评论道:“Evo 采用了 StripedHyena 架构,将计算时间增加较慢的 Hyena 算子与传统 Transformer 算子结合,提升了生成质量和计算效率,且其扩展规律与自然语言、计算机视觉的规律类似,为未来的模型扩展提供了计算资源分配的最佳方式。”
研究人员在多种预测和生成任务中测试了 Evo 的能力,来验证它解码遗传序列并在细胞内多层次调控中执行任务的能力。
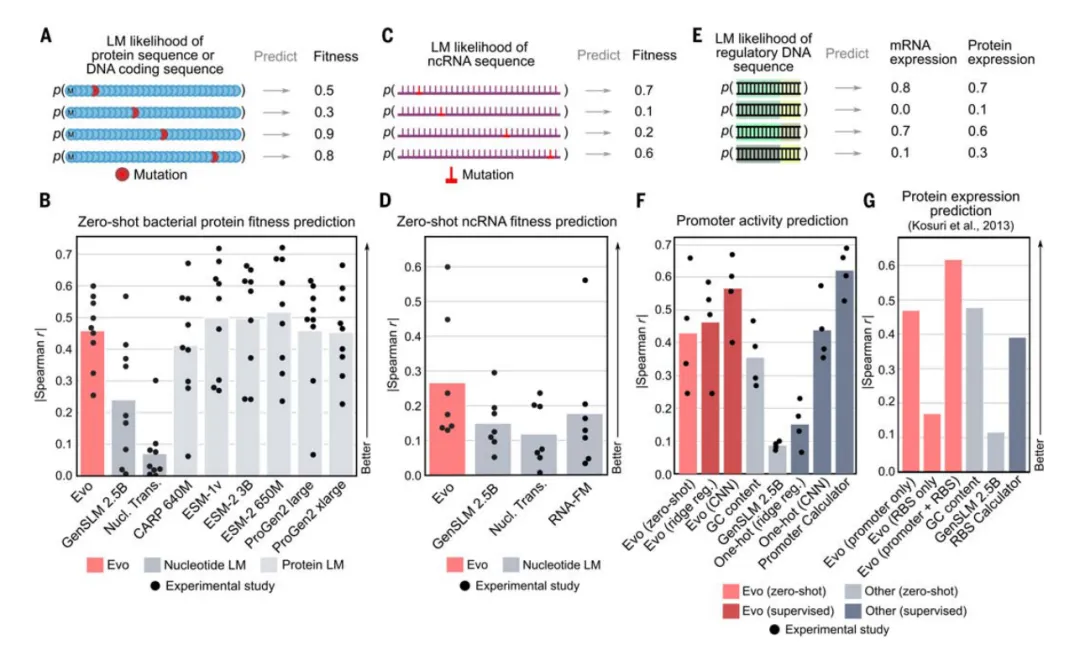
实验数据显示,Evo 在预测突变对蛋白质功能影响方面展现出领先性能,在原核生物蛋白质的 DMS 数据集中,Evo 的零样本预测能力优于其他核苷酸模型,接近某些专注于蛋白质的语言模型。
在人类蛋白质数据集上,由于初始数据量有限,表现略逊,但 Evo 在进一步训练中的改进潜力巨大,尤其在预测困惑度与适应性关联方面的发现提供了重要启示。
图|Evo 学习跨越蛋白质、ncRNAs 和调控 DNA 的功能
Evo 的跨物种预测能力不仅限于蛋白质。在非编码RNA的功能预测中,Evo 在多个 DMS 任务中的表现超越其他核苷酸语言模型。尤其在预测 5S rRNA 突变对大肠杆菌生长影响时,Evo 的斯皮尔曼相关系数达 0.60,表现出优异的突变影响预测能力。
此外,Evo 在调控 DNA 活性预测方面,以高零样本似然度显著关联启动子活性,结合监督模型后接近先进的预测方法,为非编码区域的功能研究提供了有力支持。
研究发现,Evo 在生成式设计中的表现同样亮眼。经过微调的 Evo 模型可以根据提示生成多种类型的 CRISPR-Cas 系统,其中筛选出的 EvoCas9-1 被实验验证具有与天然 SpCas9 类似的体外切割活性。
除了 CRISPR 系统,Evo 生成的 sgRNA 能够提升 SpCas9 的切割效率,同时生成的 Cas9 系统部分与天然 Cas9 序列同一性较低,展示了较强的多样性与功能性。
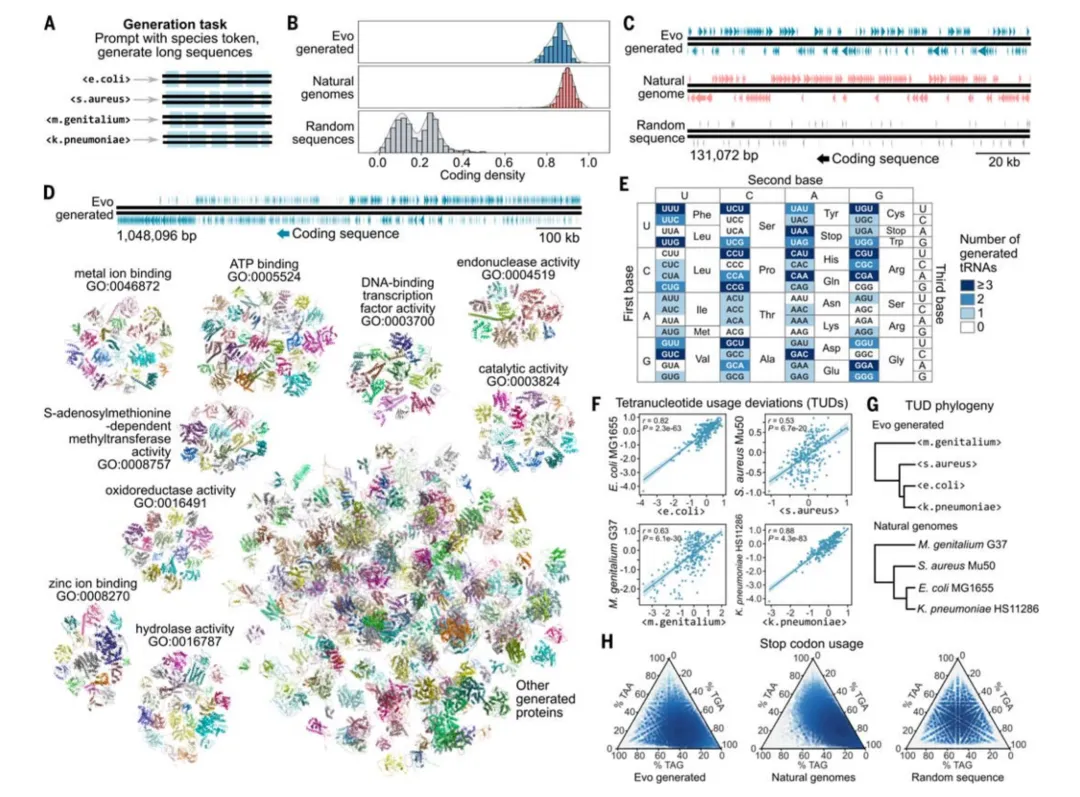
图|Evo 可生成具有可信基因组结构的巨量级序列
在转座子生成方面,Evo 同样展现出灵活性和准确性。Evo 生成的 IS200 和 IS605 元素在体外实验中表现良好,部分元件成功实现了切除与插入功能,显示出在生成功能性转座子中的潜力。例如, IS200 类似元件的成功率接近 50%,生成的 TnpA 蛋白具有功能性的发夹结构和低同一性,显示出在转座子生成中的广泛适应性。
Theodoris 称:“Evo 在基因工具生成中的表现,显示了 AI 在基因设计的广泛应用性。”
Theodoris 认为,这项突破性的研究展现了如何在计算最优的架构下实现数据和模型规模的合理配置,不仅对未来更大规模的基因组建模有指导意义,也标志着基因组大模型与自然语言处理的跨领域创新。
尽管 Evo 生成的基因组规模序列(约1 Mb)在编码密度、GC含量、蛋白质结构预测、tRNA生成等方面高度接近天然基因组,但目前研究仍有瓶颈。
首先,Evo 模型在仅含 3000 亿原核生物 token 的数据集预训练,相比海量公开基因组数据只是一小部分,这导致其预测人类蛋白质突变功能效应的能力受限。
其次,与自然语言模型类似,Evo 在生成长序列时难以保证连贯性和多样性。例如,生成 CRISPR - Cas 序列时会有 cas 基因缺失或不完整问题,生成百万碱基长的基因组序列时难以涵盖全套 rRNAs 等关键 token 基因,影响序列完整性和可用性。
研究团队指出,未来将通过扩大数据集、增加模型规模、丰富训练上下文等手段提升 Evo 的性能。
在功能拓展方面,利用基因组语言模型引导多基因系统定向进化,提高多基因环境下分子结构预测的准确性,并通过优化条件和提示工程让 Evo 成为下一代序列搜索算法核心,从关系或语义层面挖掘宏基因组信息。
在数据拓展和安全方面,计划纳入真核基因组,但因其复杂性高,需在模型工程、计算资源和安全校准投入大量资源。结合大规模基因组改造进展,Evo 将推动生物工程和设计扩展到全基因组规模。
在功能拓展方面,利用基因组语言模型引导多基因系统定向进化,提高多基因环境下分子结构预测的准确性,并通过优化条件和提示工程让 Evo 成为下一代序列搜索算法核心,从关系或语义层面挖掘宏基因组信息。
在数据拓展和安全方面,计划纳入真核基因组,但因其复杂性高,需在模型工程、计算资源和安全校准投入大量资源。结合大规模基因组改造进展,Evo 将推动生物工程和设计扩展到全基因组规模。
Theodoris 预测,未来模型可能学习人类及其他真核生物基因组,从而更有效地预测基因组中长距离调控交互的影响。
他还设想,通过环境因素或细胞状态的提示,可以进一步引导 Evo,使其能够在多细胞生物中根据不同的时空条件执行特定的细胞功能。
值得关注的是,生物技术是一把双刃剑,像 Evo 这样的强大基因组基础模型在带来科研突破的同时,也引发了一些安全与伦理的讨论。
例如,恶意用户可能利用 Evo 生成抗药性或免疫逃逸的微生物,尽管实际操作难度较大,但随着基因工程工具的普及,有必要对模型使用权限进行严格监管,明确“滥用”行为的界定,以确保 Evo 的安全使用。
此外,Evo 的开源性为科研带来了透明性,但其应用资源的分配也可能引发科技不平等。
目前,主要能有效运用 Evo 的机构多集中于生物技术公司和大型科研组织,这可能加剧科技红利在特定人群中的集中。为实现全球科技红利的均衡,国际社会有必要推动资源匮乏地区的技术培训与支持,以弥合科技应用的差距。
在生态层面,尽管 Evo 本身不会直接操控基因,但其生成的基因编辑系统可能带来生态挑战。基因编辑生物体释放到自然环境中可能引发生态失衡。为此,研究团队建议,全球科学界应制定更为严格的基因工程准则,以确保科学技术在尊重自然生态的前提下造福人类。
Evo 的诞生标志着生成式基因组学进入了一个新时代。
作为一款具备跨物种基因预测和生成能力的基础模型,Evo 不仅在基因组设计、药物开发等领域展现了前所未有的潜力,也推动了生命科学领域的创新。
然而,在推动技术进步的同时,科学家们也需保持对安全、社会公平和生态保护的高度关注。通过制定完善的政策和全球协作,确保 Evo 模型的负责任应用,生成式基因组学将在未来迎来更加广阔的应用前景。
文章来自于“学术头条”,作者“田小婷”。




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
