# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
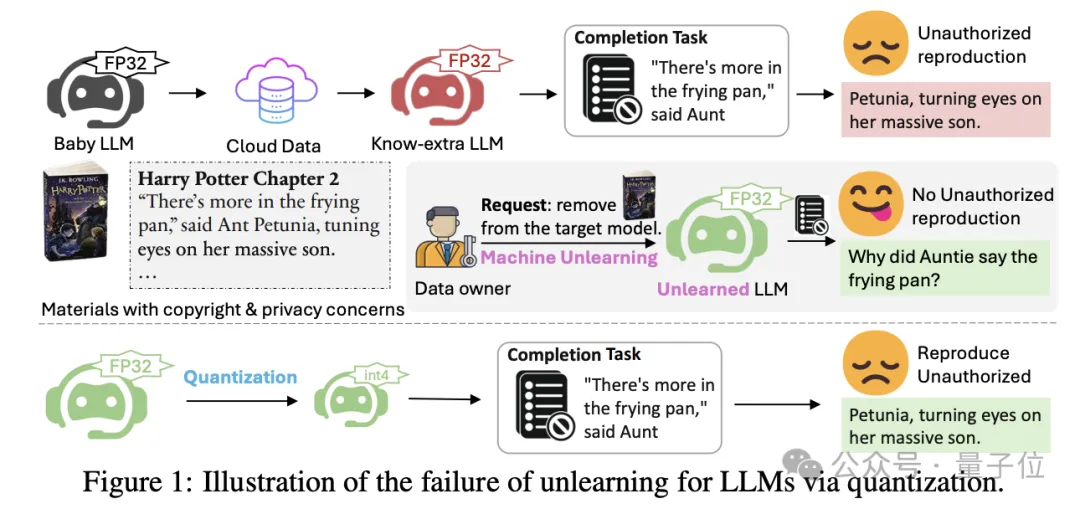
4-bit量化,能让现有反学习/机器遗忘技术失灵!
也就是大模型在人类要求下“假装”忘记了特定知识(版权、私人内容等),但有手段能让它重新“回忆”起来。
最近,来自宾夕法尼亚州立大学、哈佛大学、亚马逊团队的一项新研究在reddit、Hacker News上引起热议。

他们发现对“失忆”的模型量化(quantization),可以部分或甚至完全恢复其已遗忘的知识。
原因是在量化过程中,模型参数的微小变化可能导致量化后的模型权重与原始模型权重相同。
看到这项研究后,不少网友也表示有点意外:
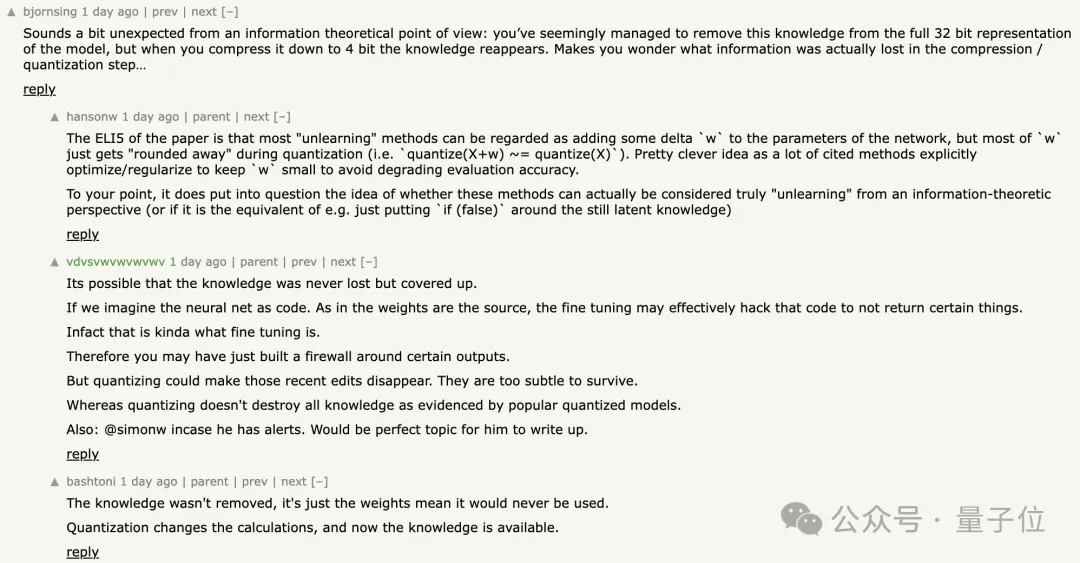
从信息理论的角度来看这有点出人意料,似乎已经在完整的32-bit中成功移除了这些知识,但当你将其压缩到4-bit时,知识又重新出现了。
这让人不禁想知道在压缩/量化步骤中到底丢失了什么信息。

可能这些知识从未真正丢失,只是被隐藏了。
如果我们把神经网络看作是代码,权重就是源代码,微调实际上可能有效地修改了这些代码,以阻止返回某些结果。
因此,你可能只是在某些输出周围建立了防火墙。但量化可能使这些最近的编辑消失,它们太微小而无法保留。
值得一提的是,团队提出了一种缓解此问题的策略。
这种策略通过构建模块级别的显著性图来指导遗忘过程,只更新与遗忘数据最相关的模型部分,从而在保持模型效用的同时,减少量化后知识恢复的风险。
话不多说,具体来康康。

大模型在训练过程中可能会无意学习到人类不希望它保留的知识,例如版权和私人内容。为了解决这个问题,研究者们此前提出了反学习(machine unlearning)的概念,旨在不重新训练模型的情况下,从模型中移除特定知识。
现有的主流反学习方法包括梯度上升(GA)和负向偏好优化(NPO)两大类,通常会采用较小的学习率并加入效用约束,以在遗忘特定内容的同时保持模型的整体性能。
用于优化模型遗忘的最常用数学表达式是:
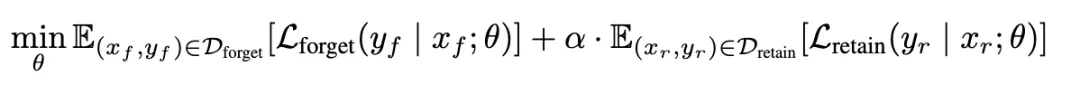
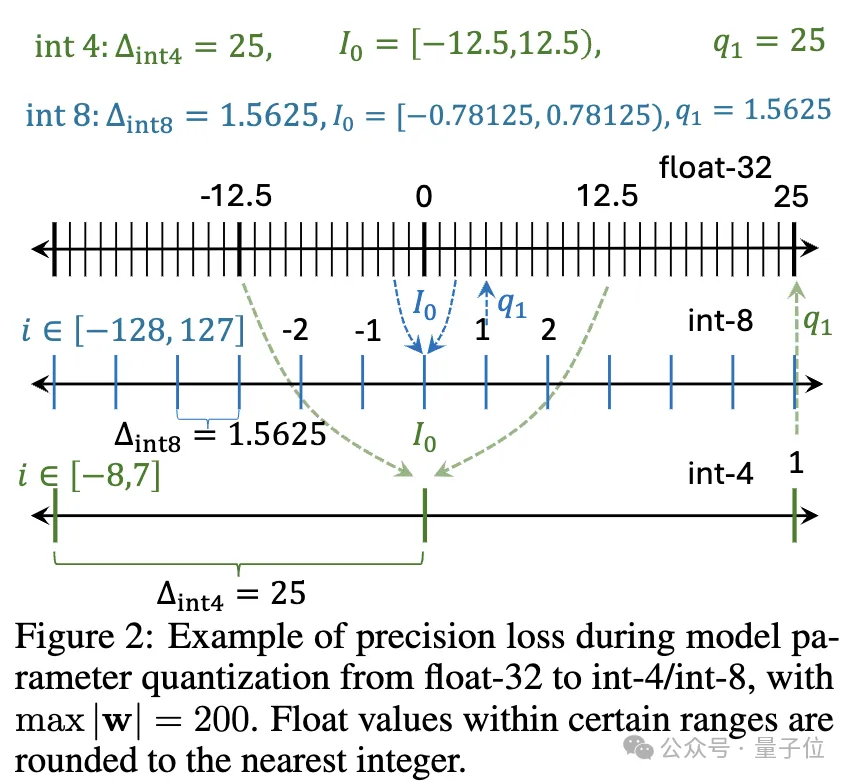
再来看量化,考虑一组或一块权重w,线性操作可以表示为y=wx,量化后为y=Q(w)x,其中 Q(⋅)是量化函数:
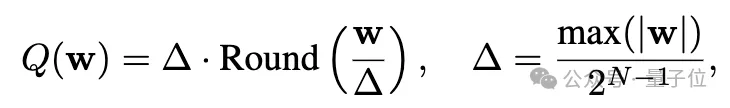
在这项研究中,研究人员使用Q(f)表示量化后的模型f。因此,实施一个反学习法然后对遗忘后的模型进行量化可以写为:
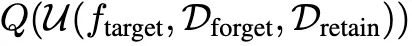
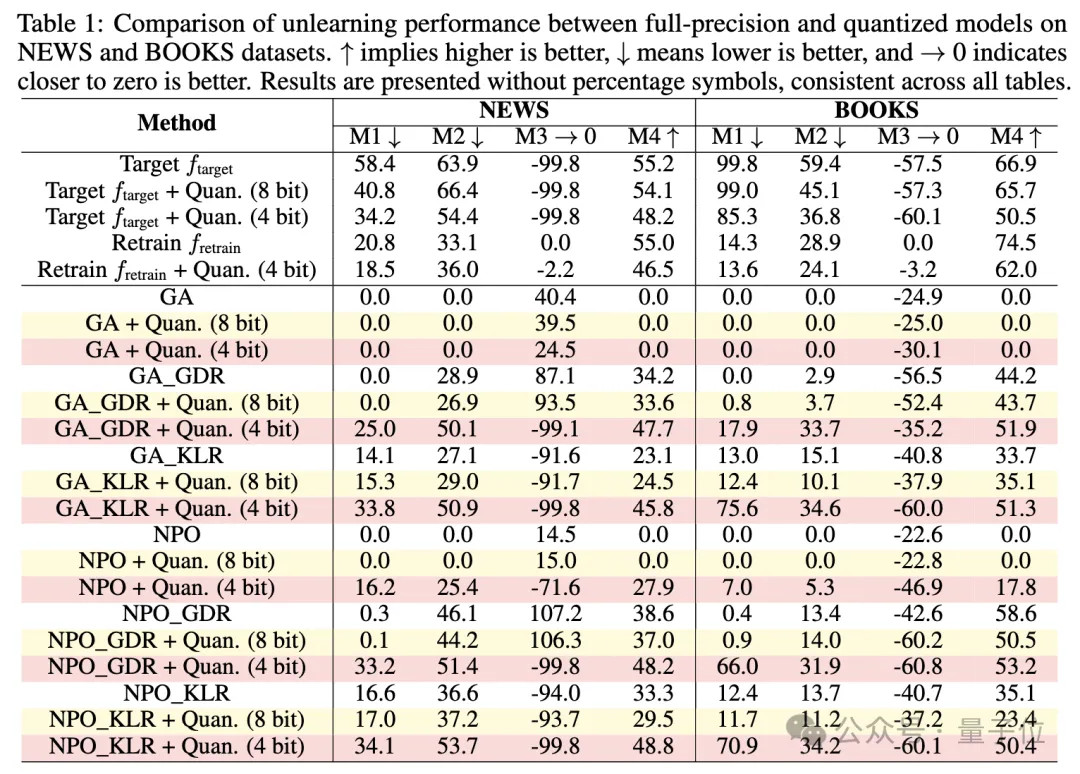
研究人员评估了针对大模型的六种有效的反学习方法——结合NPO、GA两种策略,在保留集上进行梯度下降(GDR)或最小化KL散度(KLR),形成了GA、GA_GDR、GA_KLR、NPO、NPO_GDR、NPO_KLR。
结果显示,这些方法在经过量化后会出现“灾难性失败”。
具体表现为,在全精度下,加入效用约束的反学习法平均保留21%的目标遗忘知识,但经过4-bit量化后,这一比例急剧上升到83%。
这意味着大部分被“遗忘”的知识通过简单的量化操作就能恢复。
实验中还使用了不同位数的量化,包括4-bit和8-bit量化,量化精度对遗忘效果也有显著影响,8-bit量化的影响相对较小,模型表现接近全精度版本,但在4-bit量化下,遗忘性能显著恶化。
实验在NEWS(BBC新闻文章)和BOOKS(哈利波特系列)等基准数据集上进行,使用了四个评估指标:
逐字记忆(VerMem,评估逐字复制能力)、知识记忆(KnowMem,评估知识问答能力)、隐私泄露(PrivLeak,基于成员推理攻击评估隐私保护程度)以及保留集效用(评估模型在非遗忘数据上的表现)。
研究人员还分析了各种量化技术对遗忘的影响,用GPTQ和AWQ两种先进的4-bit量化法在相同的实验设置下进行实验,NEWS数据集上的结果如下:
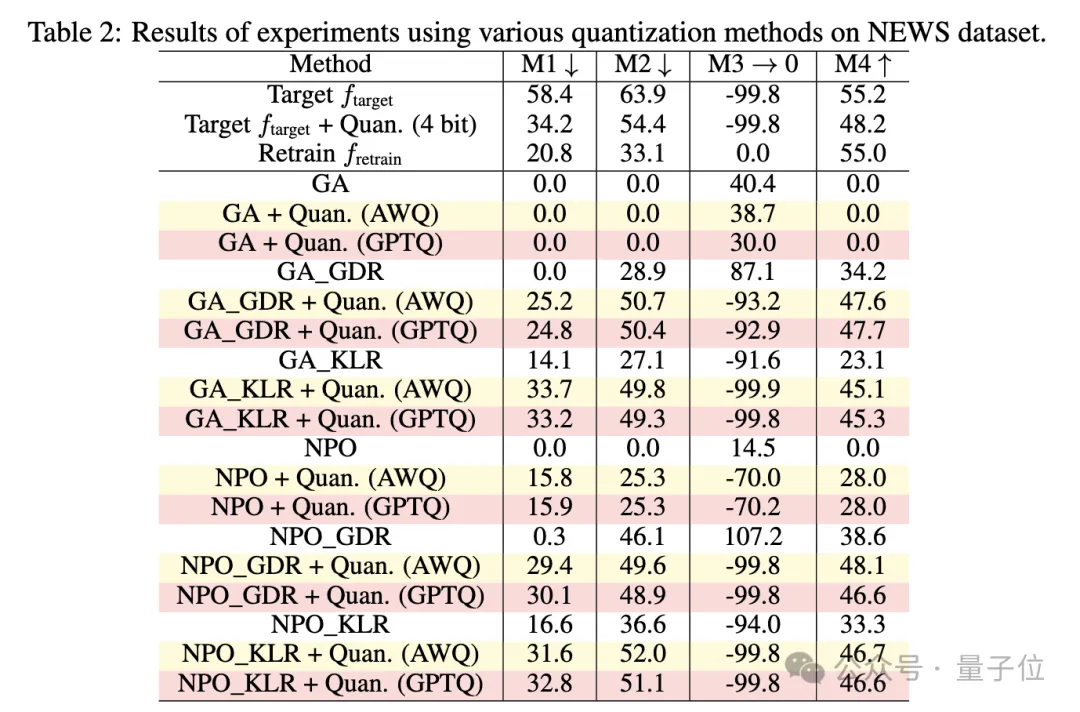
GPTQ和AWQ的表现与RTN相似。
尽管研究人员表示已努力有效地调整参数,但校准数据集是通用的,而不是针对遗忘数据集的领域进行定制,这意味着GPTQ和AWQ仍然可能保留了本应被遗忘的知识。
经分析,研究人员认为这一问题的根本原因在于:
现有反学习法为了保持模型效用而使用较小的学习率和效用约束,导致模型权重变化很小,在量化过程中原模型和遗忘后模型的权重很容易被映射到相同的离散值,从而使被遗忘的知识重新显现。
由此,研究人员提出了一种称作SURE(Saliency-Based Unlearning with a Large Learning Rate)的框架作为改进方案。
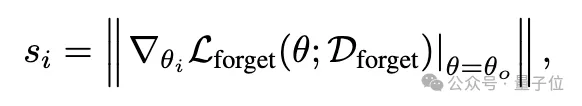
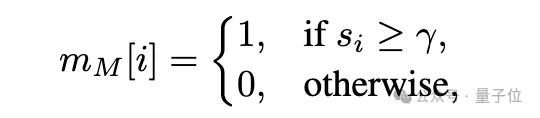
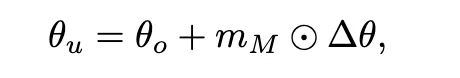
该框架通过构建模块级显著性图来指导遗忘过程,选择性地对与遗忘数据最相关的组件使用较大的学习率,同时最小化对其它功能的影响。
通过实验,验证了SURE策略防止量化后遗忘知识恢复的有效性,并且与现有的反学习方法相比,SURE在全精度模型上实现了可比的遗忘性能和模型效用。
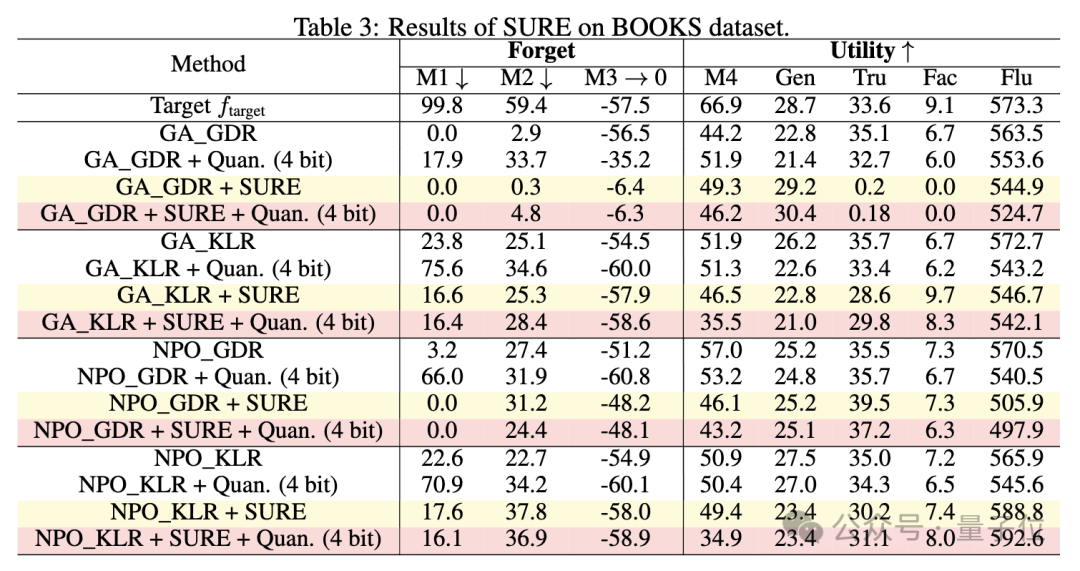
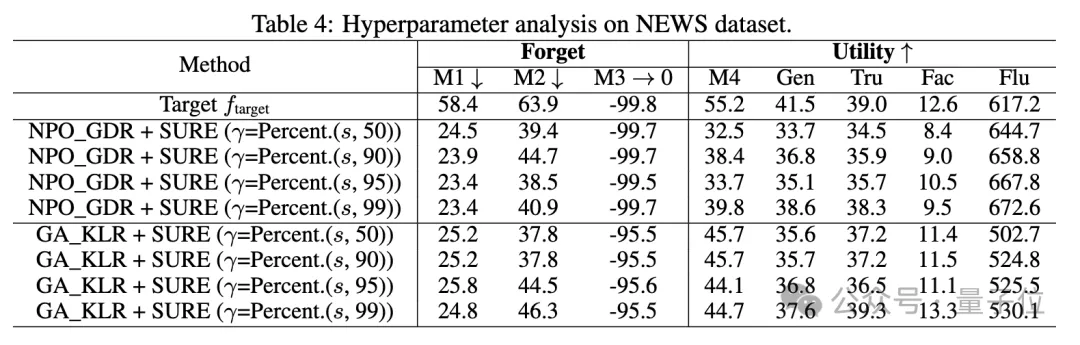
研究人员还探讨了SURE策略中不同阈值对遗忘性能的影响,发现适度的阈值可以在遗忘性能和模型效用之间取得平衡。
更多细节,感兴趣的童鞋可以查阅原论文,代码已在GitHub上公开。
论文链接:https://arxiv.org/pdf/2410.16454
参考链接:
[1]https://news.ycombinator.com/item?id=42037982
[2]https://github.com/zzwjames/FailureLLMUnlearning
文章来自于“量子位”,作者“西风”。




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
