# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在闭着眼睛听一首歌的时候,你有没有在脑海里想象过,应该搭配什么画面?
Kimi 内测的最新功能「创作音乐视频」,就是奔着当 MV 导演去的。长文本领先的 Kimi,默不作声地「跨界」了。APPSO 也受邀首批体验了这一新功能。

给 Kimi 一首歌,然后等待几首歌的时间,它就还你一个短视频,能踩点,懂分镜,审美也不错。
懂王入场曲、川普战歌《YMCA》,谁上头了?每当音乐响起,特朗普握紧双拳,上下挥动,没有人比他更懂怎么搓澡。
不妨试试拿 Kimi 做个同款。我上传了一段 11 秒的《YMCA》片段,并用提示词描述了视频的画面和分镜。
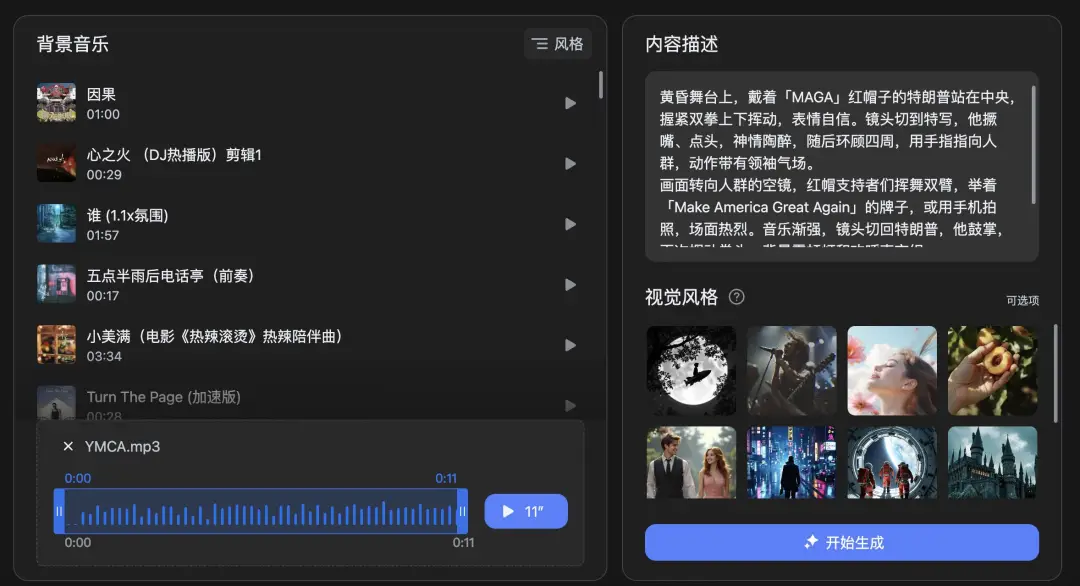
其中有个高难度的要求:帽子写上「MAGA」,应援的牌子更是要写一整个句子:「Make America Great Again」。
Kimi 理解了,它为每个镜头扩写了提示词,短短的 11 秒,有 6 个片段,同时符合我的提示词里的镜头切换逻辑。

接下来,打开音量,或者戴上耳机,欣赏一下完整视频。

特朗普的脸偶尔会崩,至于文字,缩写很稳,单词也不容易拼错,但就是没有生成符合要求的句子。
不过,舞王的感觉对了,胸前的红领带很鲜艳,特写尤其传神。
除了迪斯科神曲,《青花瓷》这样的经典中国风歌曲,Kimi 也能 hold 住。

近景切全景,特写切远景,有人物,也有空镜,每个镜头都是按照提示词的要求设计的,烟雨江南的意境到位了。

可惜人物的稳定性不够好,这位女主角从头到尾长得都不一样,手指的动作也比较诡异,一眼看出,这是个 AI。
以及 Kimi 可以解释一下吗,为什么她的手上还戴了戒指?为什么青花瓷瓶自己会滑动?

除了自己上传音乐,我们也可以复制粘贴抖音链接。
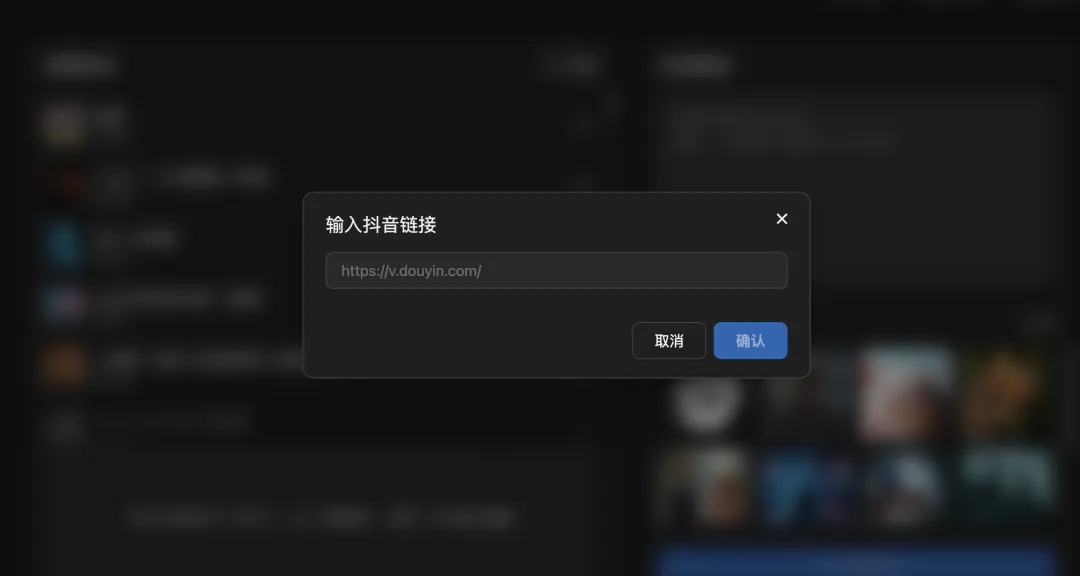
以后一键 get 同款抖音热歌,变得不费吹灰之力了。
我选择了周传雄在抖音的一段 800 万点赞的吉他弹唱视频,Kimi 可以提取出音乐,画面的提示词还是我们自己来写。

让 AI 也来弹唱一段吧,虽然音乐里包含了歌词,但实践表明,对口型什么的就别想了。

这次主要都是室内的中近景,人物的一致性保持得不错,帽子和 T 恤都不带变的,但场景就不那么完美了。
毕竟,音乐视频还是一个 Kimi 的内测功能,至少从每个片段扩写的提示词来看,这位 AI 导演挺擅长写分镜,将我粗略的指令,细化成了具体的镜头语言,又不偏离原意。
以后我们听歌时脑海里的大致画面,都可以描述给 AI,让它帮我们「剪辑」。
自定义的趣味性比较强,因为我们可以自己上传音乐、抖音链接,或者选择 Kimi 提供的背景音乐,创作更加自由。
同时,Kimi 有很多模板可以体验,音乐是固定好的,并且会附加一些文字和特效,对于新手来说更加友好,只需要描述画面。

《哈利波特》重映,经典归来仍是大热 IP,Kimi 也提供了一个哈利波特风格的模板。
那就试试生成哈利·波特和马尔福·德拉科的针锋相对名场面,主要包括,魔法比试、禁林探险、魁地奇球场。

视频的特效和转场酷炫,不过,两位的颜值不太稳定,马尔福有个瞬间特别像他爸,哈利波特的脸时而青春美少年时而方脸大叔。
而且,视频中也有一些错误,让人犯恐怖谷效应,六个手指就不说了,金色飞贼看着像个发光的甲虫,甚至中途冒出一个诡异的人头。
但不得不说,这个模板下有不少漂亮的画面,Kimi 的审美还是可以的。


「布达佩斯大饭店」的模板,则洋溢着对称美学和梦幻色彩。
韦斯·安德森或许也没想过,因为 AI 和我的异想天开,他的风格可以和古典的中国风融合,画面切换还能与音乐节奏完美同步。

不过,舞者的面部和腿部动作看起来有些怪异,像是伪人。怎么把握人体结构,Kimi 还得练习。
不局限在三次元,让 Kimi 这位剪刀手将动漫人物放进好莱坞歌舞电影之中,也未尝不可。
比如,让《火影忍者》的鸣人和佐助,出演一段《爱乐之城》风格的 MV。
出现的问题就比较多了,上一秒,两人的脸部特写都很不错,下一秒,切换到跳舞,鸣人的舞伴莫名其妙地变成了女生。
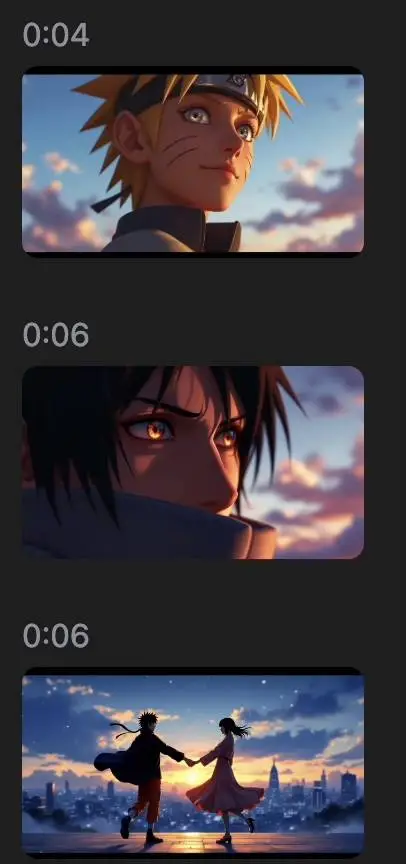
不用担心,不必从头再来,Kimi 支持片段的微调,哪个片段不满意,就可以针对性地重新生成,或者说,抽卡。
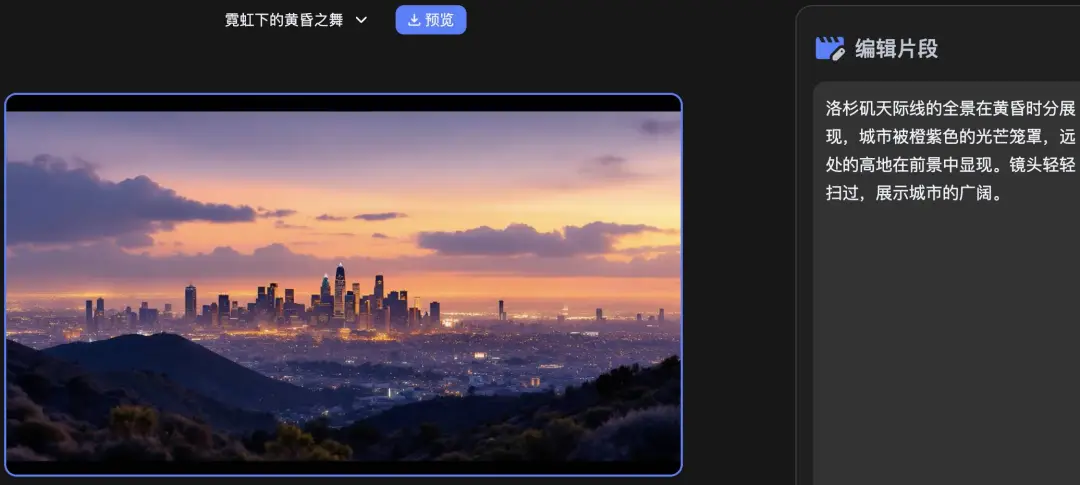
我对不满意的片段重新生成了几次,得到了以下的结果,明明是同一个人,前后的画风仿佛有次元壁。

可以说,差强人意——没有用错成语,大体上还可让人满意。至少,空镜和特写是好看的。
人人生成一段简单的 MV,难度基本等于零。当然,如果模板的选择更多,那就更方便开脑洞,也不担心撞风格了。
我们可以为熟悉的音乐创作 MV、基于喜欢的模板创作 MV,但从头开始,完全创作独一无二的作品,也不是不行。
方法是,走 AI 一条龙服务——为 AI 音乐,生成 AI 视频。
我之前用一张工作群回复收到的图片,让 Suno 图生音乐,生成了一段 30 秒的 k-pop 风格《收到之歌》。
用这首歌,让 Kimi 生成一段打工人的写实视频,会如何呢?
30 秒的 MV,Kimi 生成用了 15 分钟左右,平心而论,速度不算太慢,毕竟,我们自己把素材一个个搜罗起来再剪辑,时间可能要按小时甚至按天计算。
首先,它给这支 MV 取的名字就够伤人了——《打工人的不眠夜》,凄凄惨惨戚戚。

视频展现了打工人的群像,场景有些复杂,从早上切换到晚上,最后一段旋律的踩点丝滑。
更重要的是,Kimi 把打工人疲惫的精神面貌表现出来了,咖啡不离身,一天对着电脑,在凌乱的工位吃饭,这不就是世另我吗。
音乐视频,可以说是 Kimi 对外公布的第一个多模态功能。
11 月 16 日,Kimi 正式发布新一代数学推理模型 k0-math,对标 OpenAI o1 系列,月之暗面创始人杨植麟在现场回答了媒体提问。
被问到 Kimi 怎么不做多模态,杨植麟表示,「我们也做,几个多模态的能力在内测」。

在他看来,AI 接下来最重要的是思考和交互这两个能力,多模态肯定是必要的,但思考决定了它的上限。
未来,Kimi 的多模态会怎样迭代,把一致性做得更好,还是很值得期待一下的。
每次创作,Kimi 会先欣赏音乐,想象搭配音乐的故事,再根据故事生成画面,然后根据画面剪辑成视频。从前,这个流程让人类来做,可能要花好几天,甚至需要一个项目组。

AI 让任何人都可以讲述自己的故事,围绕我们的生活经验和兴趣爱好,生成非常个人化的内容,虽然现在问题还挺多,但未来可期。
不是所有歌曲都有精心拍摄的 MV,不是每个人都懂剪辑,但有了 AI 之后,我们喜欢的每首歌,或者自己生成的歌,都可以拥有一个专属视频。
一瞬的闪念,私人的心情,美妙的创意,都有了安放之处,和变成现实的权利。问题可以慢慢解决,但我们要先让可能性存在。
文章来自于微信公众号“APPSO”,作者“发现明日产品的”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
