# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
新的大语言模型(LLM)评估基准对于跟上大语言模型的快速发展至关重要。
近日,淘宝天猫集团的研究者们提出了中文简短问答(Chinese SimpleQA),这是首个全面的中文基准,具有“中文、多样性、高质量、静态、易于评估”五个特性,用于评估语言模型回答简短问题的真实性能力。
研究人员表示,中文简短问答能够指导开发者更好地理解其模型的中文真实性能力,并促进基础模型的发展。
论文地址:https://arxiv.org/abs/2411.07140
人工智能发展中的一个重大挑战是确保语言模型生成的回答在事实上准确无误。当前前沿模型有时会产生错误输出或缺乏证据支持的答案,这就是所谓的“幻觉”问题,极大地阻碍了通用人工智能技术(如大语言模型)的广泛应用。此外,评估现有大语言模型的真实性能力也颇具难度。例如,大语言模型通常会生成冗长的回复,包含大量事实性陈述。最近,为解决上述评估问题,OpenAI发布了简短问答基准(SimpleQA),其中包含4326个简洁且寻求事实的问题,使得衡量真实性变得简单可靠。
然而,简短问答基准主要针对英语,导致对大语言模型在其他语言中的能力了解有限。此外,受近期几个中文大语言模型基准(如C-Eval、CMMLU)的启发,为了评估大语言模型在中文语境下的真实性能力,淘天集团的研究人员提出了中文简短问答基准。该基准由3000个高质量问题组成,涵盖从人文到科学工程等6个主要主题。具体而言,中文简短问答的显著主要特征如下:
研究人员在中文简短问答上对现有大语言模型进行了全面评估和分析,得出了以下一些有洞察力的发现:
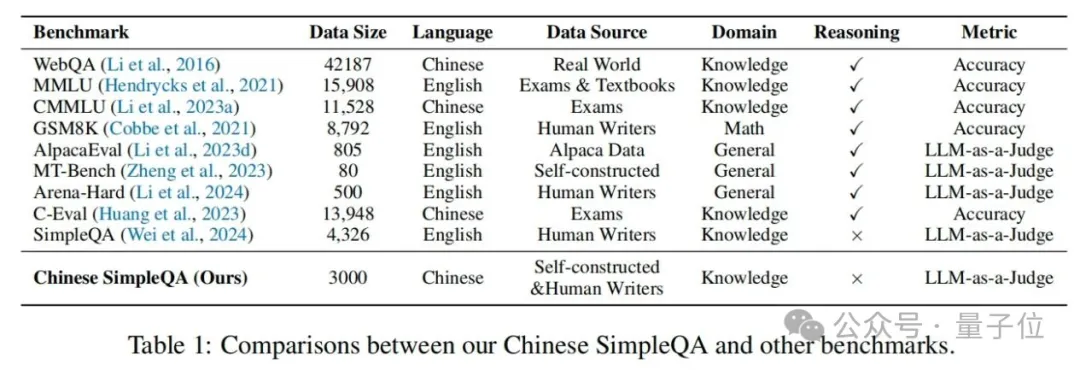
中文简短问答的类别分布,包含六个主要主题,每个主要主题包含多个二级子主题。在表1中,作者将中文简短问答与几个主流的大语言模型评估基准进行了比较,这表明中文简短问答是第一个专注于评估大语言模型中中文知识边界的基准。
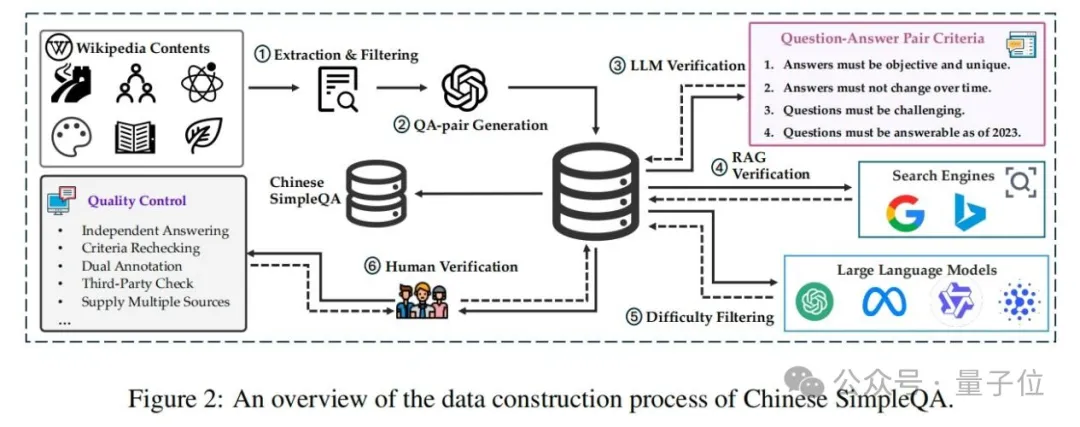
如图2所示,中文简短问答的数据收集过程涉及自动构建和人工验证。自动阶段包括:(1)提取和过滤相关知识内容,(2)自动生成问题-答案对,(3)根据预定义标准使用大语言模型验证这些对,(4)执行检索增强生成(RAG)验证,以及(5)进行难度筛选。
具体而言,首先,作者从各种知识领域(如维基百科)收集大量知识丰富的文本内容,并使用质量评估模型过滤掉低质量数据。然后,作者提示大语言模型使用这些高质量知识内容生成问题-答案对。之后,为确保中文简短问答的质量,作者使用大语言模型去除不符合预定义标准要求的样本。通过这种方式,可以获得大量初步筛选后的知识问题-答案对。同时,为了提高答案的质量,部署外部检索工具(即搜索引擎)来收集更多样化的信息,这引导大语言模型基于RAG系统评估答案的事实正确性。具体来说,应用LlamaIndex作为检索方法,以谷歌和必应的搜索结果作为数据源。关于生成和验证的详细信息可以在附录A中找到。此外,作者过滤一些简单样本以发现大语言模型的知识边界并提高中文简短问答的难度。具体来说,如果一个问题可以被四个大模型正确回答,则认为它是一个简单问题并将其丢弃。
值得注意的是,问题-答案对的构建基于以下标准:
在自动数据收集之后,采用人工验证来提高数据集质量。具体来说,每个问题由两个人工注释者独立评估。首先,注释者确定问题是否符合上述预定义标准。如果任何一个注释者认为问题不符合要求,则丢弃该样本。随后,两个注释者都使用搜索引擎检索相关信息并制定答案。在此阶段,注释者应使用权威来源(如维基百科、百度百科)的内容,并且每个注释者必须提供至少两个支持性URL。如果注释者的答案不一致,则由第三个注释者审查该样本。最终注释由第三个注释者根据前两个评估确定。最后,将人工注释结果与大语言模型生成的回复进行比较,仅保留完全一致的问题-答案对。这个严格的人工验证过程确保了数据集保持高准确性并符合既定标准。
在构建和注释中文简短问答的整个过程中,许多低质量的问题-答案对被丢弃。具体来说,最初生成了10000对。经过使用不同模型进行难度评估后,大约保留了6310对,其中约37%的较简单数据被丢弃。在此之后,经过基于规则的验证和基于模型的RAG验证,又删除了2840个样本,这意味着仅剩下约35%的原始生成数据。最后,经过彻底和严格的人工审查,仅保留了约3000个样本,约占原始数据集的30%。
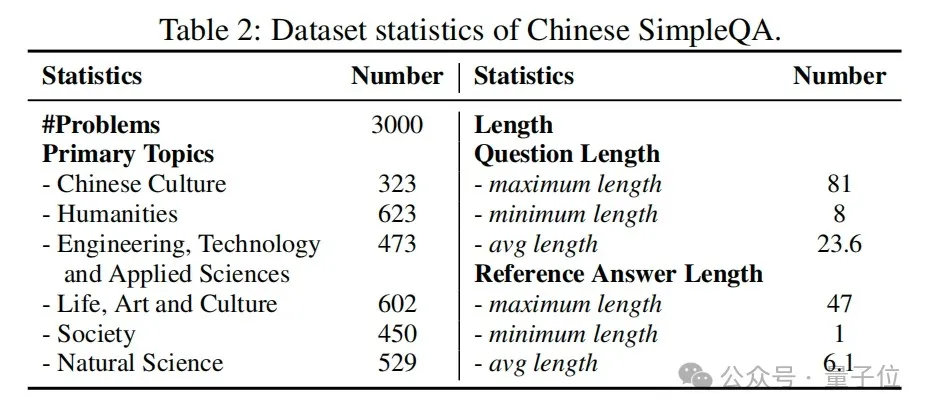
表2展示了中文简短问答的统计数据。共有3000个样本,中文简短问答在六个主要主题上的数据分布相对均衡,这可以有效地评估大语言模型在各个领域的知识边界。此外,该数据集中问题和参考答案的长度分布都非常短,这是基于知识查询的特点。值得注意的是,使用中文简短问答评估模型需要最少的输入和输出标记,从而导致非常低的评估计算和时间成本。
与SimpleQA类似,中文简短问答也采用以下五个评估指标:
作者评估了17个闭源大语言模型(即o1-preview、Doubao-pro-32k、GLM-4-Plus、GPT-4o、Qwen-Max、Gemini-1.5-pro、DeepSeek-V2.5、Claude-3.5-Sonnet、Yi-Large、moonshot-v1-8k、GPT-4-turbo、GPT-4、Baichuan3-turbo、o1-mini、Doubao-lite-4k、GPT-4o-mini、GPT-3.5)和24个开源大语言模型(即Qwen2.5系列、InternLM2.5系列、Yi-1.5系列、LLaMA3系列、DeepSeek系列、Baichuan2系列、Mistral系列、ChatGLM3和GLM-4)。
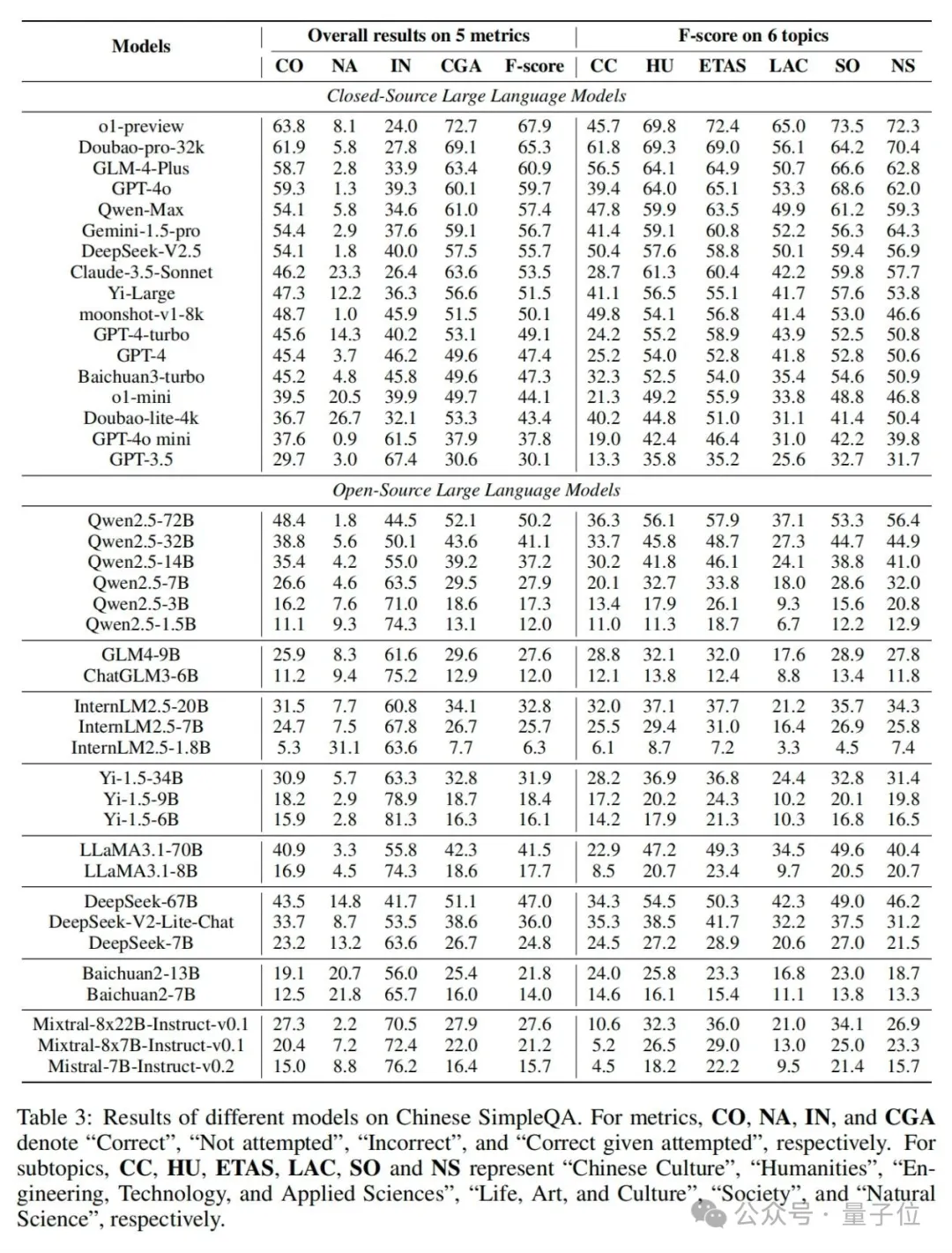
如表3所示,论文提供了不同大语言模型在中文简短问答上的性能结果。具体来说,与SimpleQA类似,作者提供了五个评估指标的总体结果。
此外,论文还报告了六个主题的F分数,以分析这些大语言模型的细粒度真实性能力。在表3中,有以下有洞察力和有趣的观察结果:
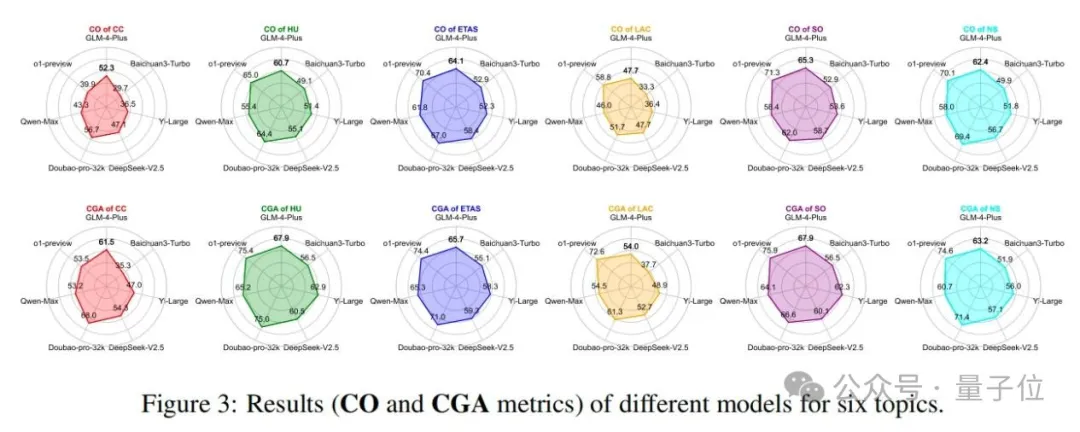
此外,论文还在图3中提供了六个主题的详细结果(CO和CGA指标)。
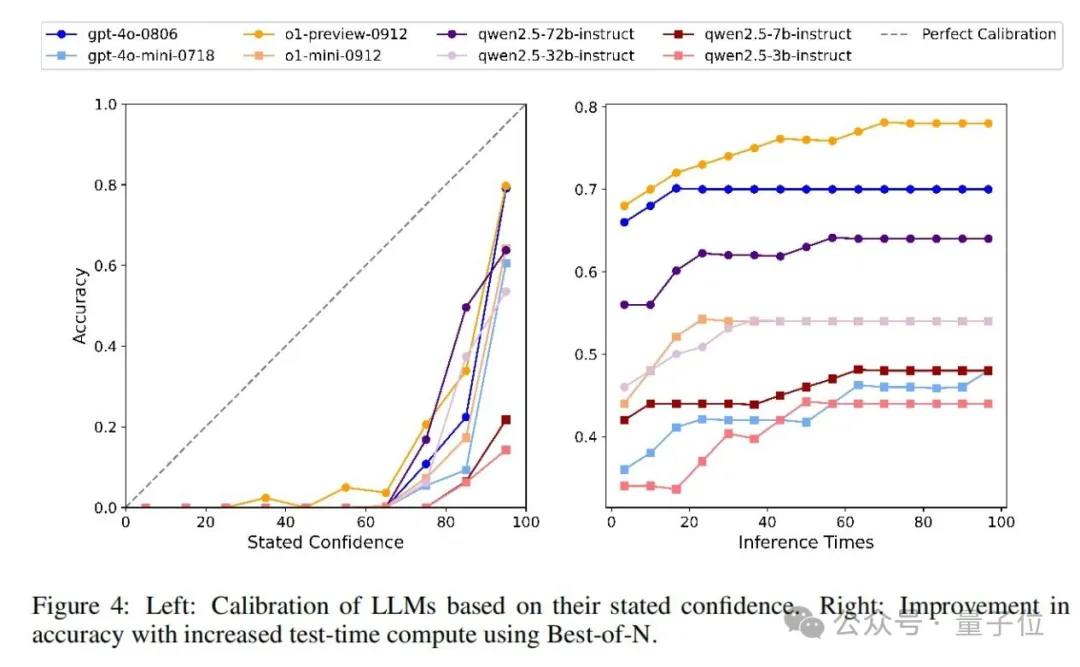
对于不同大语言模型的校准,与SimpleQA类似,作者指示模型在回答问题时提供相应的置信水平(从0到100),以衡量模型对其答案的信心(见附录B中的提示)。我们知道,一个完美校准的模型的置信度(%)应该与其答案的实际准确性相匹配。图4中的左图说明了校准性能,这表明GPT-4o比GPT-4o-mini校准得更好,o1-preview比o1-mini校准得更好。对于Qwen2.5系列,校准顺序为Qwen2.5-72B>Qwen2.5-32B>Qwen2.5-7B>Qwen2.5-3B,这表明更大的模型尺寸会导致更好的校准。此外,对于所有评估模型,它们在置信度>50的范围内的置信度低于完美校准线,这意味着它们都高估了其回复的准确性,存在过度自信的情况。
论文还评估了不同模型在增加测试时间计算时与回复准确性的关系。具体来说,从中文简短问答中随机抽取50个样本,对于每个样本,模型被要求独立回答100次。然后,使用最佳N法随着推理次数的增加获得模型的回复准确性。结果如图4中的右图所示。作者观察到,随着推理次数的增加,所有模型的回复准确性都有所提高,并最终达到一个上限。这对于中文简短问答来说是合理的,因为它专门用于探测模型知识的边界。
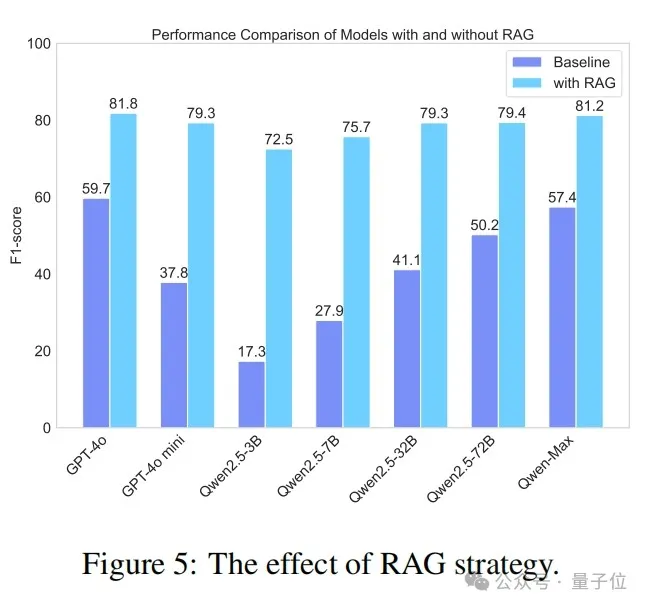
在这项研究中,论文探索了检索增强生成(RAG)策略在提高大语言模型在中文简短问答数据集上的事实准确性方面的有效性。具体来说,作者基于LlamaIndex重现了一个RAG系统,并整合了谷歌搜索API。如图5所示,所有模型在使用RAG后准确性都有显著提高。例如,Qwen2.5-3B的性能提高了三倍多。值得注意的是,几乎所有使用RAG的模型都优于原生的GPT-4o模型。同时,RAG的应用也显著降低了模型之间的性能差距。例如,使用RAG的Qwen2.5-3B与使用RAG的Qwen2.5-72B之间的F分数差异仅为6.9%。这表明RAG大大缩小了模型之间的性能差距,使较小的模型在使用RAG增强时也能实现高性能。总体而言,这表明RAG是提高大语言模型真实性的有效捷径。
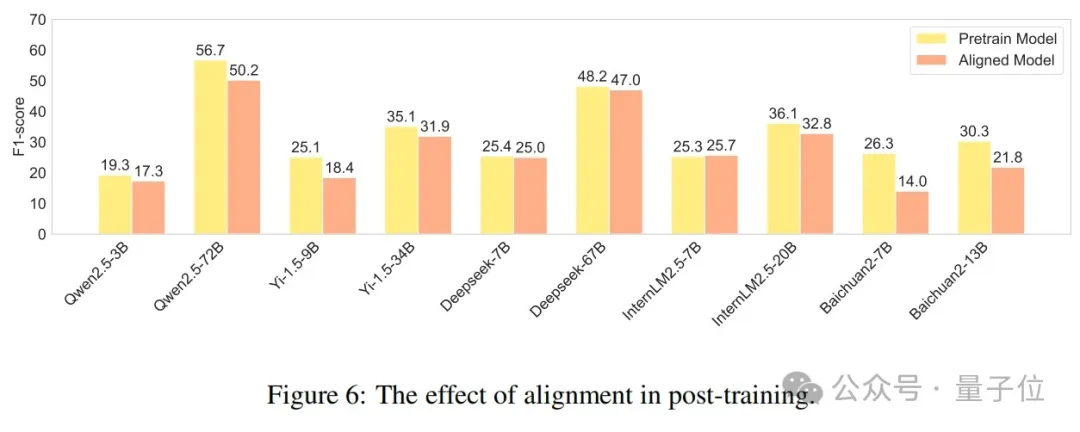
最近,先前的研究(OpenAI,2023;Song等人,2023)发现,对齐可能会导致语言模型能力的下降,即所谓的“对齐代价”。为了说明对齐对真实性的影响,作者对预训练模型和经过监督微调(SFT)或强化学习从人类反馈(RLHF)训练的对齐模型进行了比较性能分析。如图6所示,不同模型在训练后表现出不同的趋势,但大多数模型都有显著下降。其中,Baichuan2系列模型下降最为显著,Baichuan2-7B和Baichuan2-13B的F分数分别降低了47%和28%。这反映出当前大多数大语言模型的对齐训练在产生知识幻觉方面仍然存在明显缺陷,这进一步反映了此次数据集的必要性。
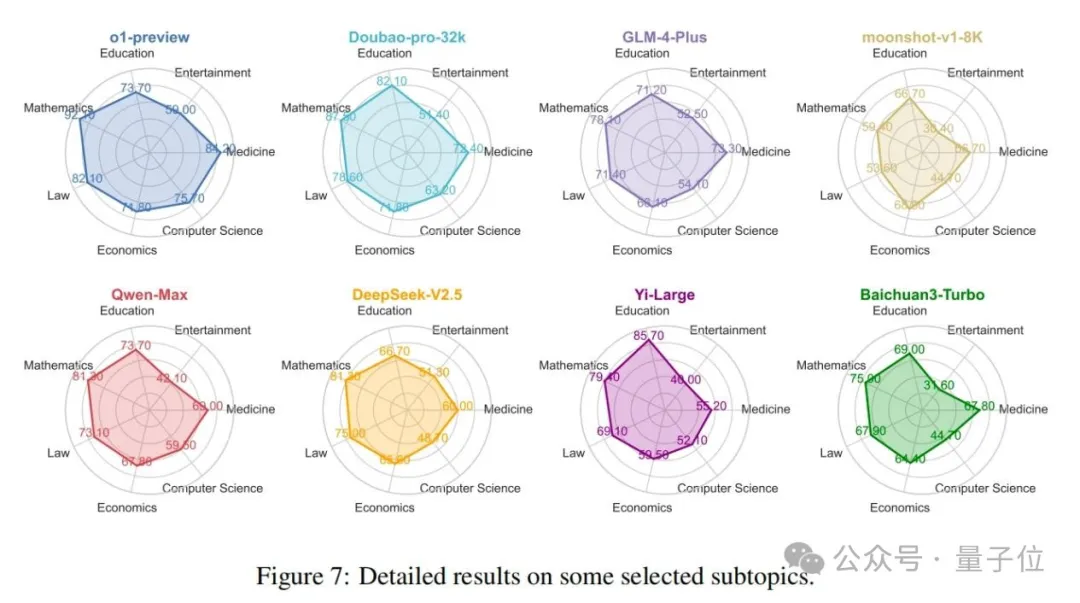
如2.2节所述,该基准涵盖了总共99个子主题,可以全面检测模型在各个领域的知识水平。图7展示了o1模型和七个著名的中文社区模型在几个常见领域内的性能比较。首先,从整体上看,o1-preview模型在这些领域中表现出最全面的性能,Doubao模型紧随其后。相比之下,Moonshot模型总体性能最弱。其次,在具体领域方面,中文社区模型和o1模型在计算机科学和医学等领域存在显著差距。然而,在教育和经济等领域,这种差距最小。值得注意的是,在教育领域,一些中文社区模型优于o1-preview,突出了它们在特定垂直领域取得成功的潜力。最后,在具体模型方面,Moonshot模型在数学、法律和娱乐等领域明显较弱,而Baichuan模型在娱乐领域也表现不佳。Yi-Large模型在教育领域表现出色,o1模型在其他领域保持最强性能。评估模型在基准数据集内不同领域的性能使用户能够确定最适合其特定需求的模型。
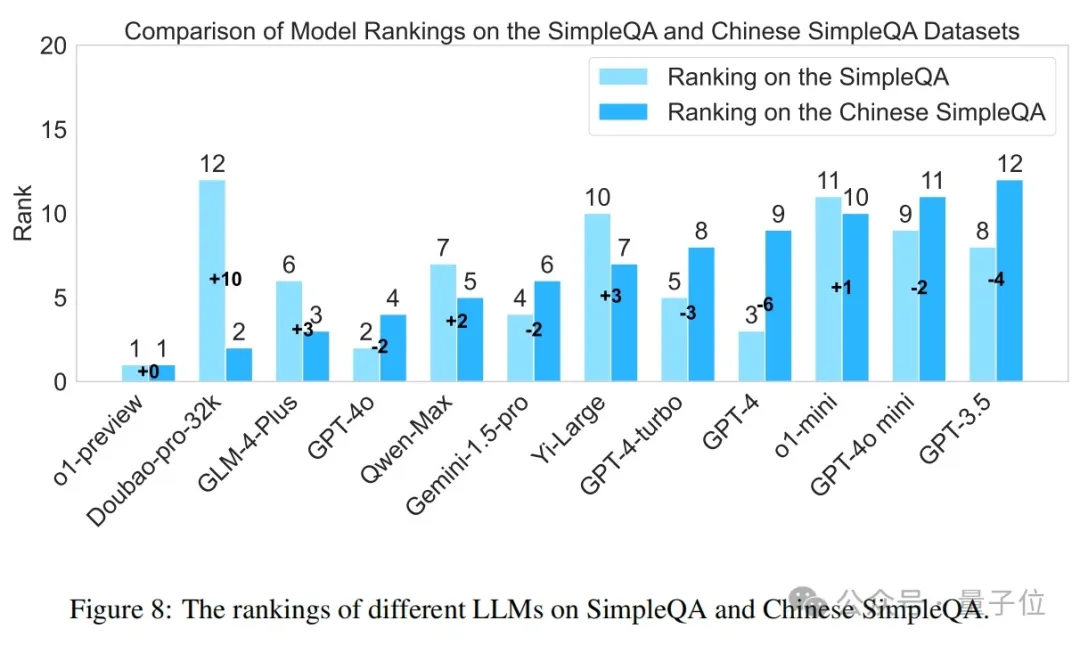
论文还比较了各种模型在SimpleQA和中文简短问答上的排名差异。如图8所示,这些两个基准上的模型性能存在显著差异。例如,Doubao-pro-32k在中文简短问答上的排名显著提高,从第12位上升到第2位(+10)。相反,GPT-4在中文简短问答上的性能下降,从第3位下降到第9位(-6)。这些差异强调了在不同语言的数据集上评估模型的重要性,以及研究优化模型在不同语言环境中性能的必要性。值得注意的是,o1-preview在两个数据集上始终保持领先地位,表明其对不同语言上下文的稳健性和适应性。此外,大多数中文社区开发的模型(如Qwen-Max、GLM-4-Plus、Yi-Large、Doubao-pro-32k)在SimpleQA上的表现优于在简短问答上的表现,展示了它们在中文任务上的竞争力。
-大语言模型真实性:大语言模型真实性是指大语言模型产生遵循事实内容的能力,包括常识、世界知识和领域事实,并且这些事实内容可以通过权威来源(如维基百科、教科书)得到证实。最近的作品探索了大语言模型作为事实知识库的潜力(Yu等人,2023;Pan等人,2023)。具体而言,现有研究主要集中在对大语言模型真实性的定性评估(Lin等人,2022;Chern等人,2023)、对知识存储机制的研究(Meng等人,2022;Chen等人,2023)以及对知识相关问题的分析(Gou等人,2023)。
-真实性基准:已经提出了许多真实性基准(Hendrycks等人,2021;Zhong等人,2023;Huang等人,2023;Li…等人,2023b;Srivastava等人,2023;Yang等人,2018)。例如,MMLU(Hendrycks等人,2021)用于测量在各种不同任务上的多任务准确性。TruthfulQA(Lin等人,2022)专注于评估语言模型生成答案的真实性。此外,HaluEval(Li等人,2023c)用于检查大语言模型产生幻觉的倾向。最近,SimpleQA(Wei等人,2024)被提出用于测量大语言模型中的简短事实性。然而,SimpleQA仅关注英语领域。相比之下,中文简短问答旨在全面评估中文语境下的真实性。
为了评估现有大语言模型的真实性能力,淘天集团的研究者们提出了第一个中文简短事实性基准(即中文简短问答),它包括6个主要主题和99个子主题。此外,中文简短问答主要具有五个重要特征(即中文、多样性、高质量、静态和易于评估)。基于中文简短问答,研究人员全面评估了现有40多个大语言模型在真实性方面的性能,并提供了详细分析,以证明中文简短问答的优势和必要性。在未来,研究人员将研究提高大语言模型的真实性,并探索将中文简短问答扩展到多语言和多模态设置。
论文地址:https://arxiv.org/abs/2411.07140
文章来自于“量子位”,作者“允中”。




【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
