# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在多模态AI领域,基于预训练视觉编码器与MLLM的方法(如LLaVA系列)在视觉理解任务上展现出卓越性能。
而基于Rectified Flow的模型(如Stable Diffusion 3及其衍生版本)则在视觉生成方面取得重大突破。
能否将这两种简单的技术范式统一到单一模型中?
来自DeepSeek、北大、香港大学以及清华大学的团队研究表明:
在LLM框架内直接融合这两种结构,就可以实现视觉理解与生成能力的有效统一。

简单来说,JanusFlow将基于视觉编码器和LLM的理解框架与基于Rectified Flow的生成框架直接融合,实现了两者在单一LLM中的端到端训练。
其核心设计包括:(1)采用解耦的视觉编码器分别优化理解与生成能力;(2)利用理解端编码器对生成端特征进行表征对齐,显著提升RF的训练效率。基于1.3B规模的LLM,JanusFlow在视觉理解和生成任务上均超过此前同规模的统一多模态模型。

在LLM基础上,JanusFlow加入了如下组件:
1、视觉理解编码器(图中的Und. Encoder):我们使用SigLIP将输入的图片转换成Visual embeddings;专注于视觉理解任务的特征提取。
2、视觉生成编解码器(图中的Gen. Encoder/Decoder):轻量级模块,总参数量约70M;基于SDXL-VAE的latent space进行生成;编码器:利用双层ConvNeXt Block将输入latent z_t 转换为visual embeddings;解码器:通过双层ConvNeXt Block将处理后的embeddings解码为latent space中的速度v 。
3、注意力机制:在我们的初步实验中,我们发现生成任务中causal attention和bidirectional attention效果相当;基于效率和简洁性考虑,统一采用causal attention处理两类任务。
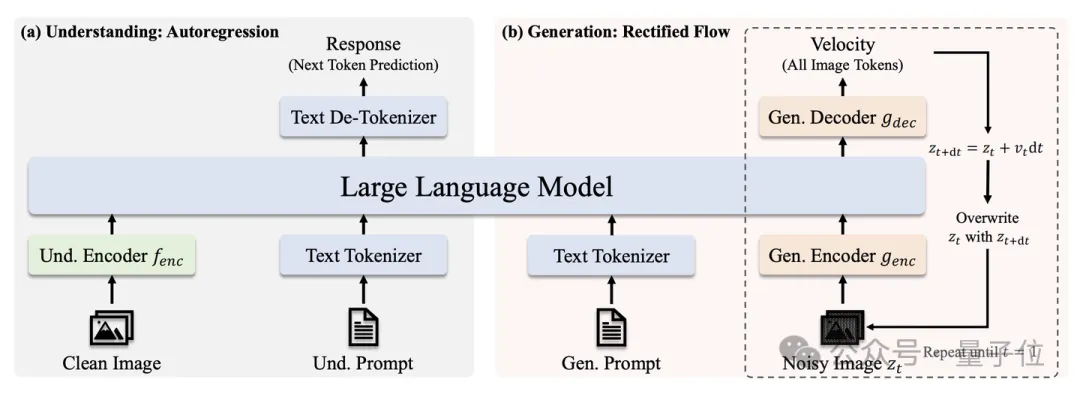
JanusFlow有两种生成模式:
1、视觉理解(文+图->文):此时,JanusFlow的推理模式是正常的自回归模式,通过预测下一个token来生成回复
2、图片生成(文->图):此时,JanusFlow的推理模式是采用欧拉法求解Rectified Flow学出的ODE,从t=0的纯噪声逐步推进到t=1的干净图像。我们在生成过程中使用Classifier-Free Guidance并把迭代步数设置为30步。
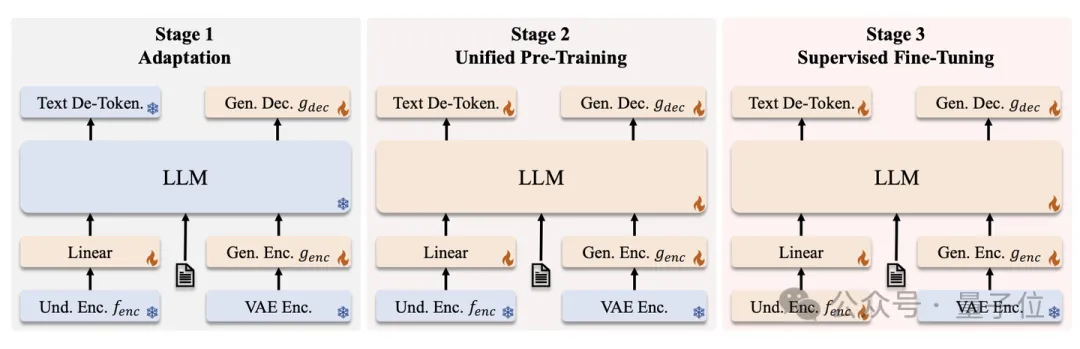
我们的训练分为 Adaptation,Pre-Training 和 Supervised Fine-Tuning三阶段。我们的训练数据包括视觉理解(图生文)和视觉生成(文生图)两类。特别地,由于发现RF收敛速度显著慢于AR,我们在预训练阶段采用了非对称的数据配比策略(理解:生成=2:8),实验证明该配比能够有效平衡模型的两方面能力。详细训练流程和数据配置请见论文。
在之前结合LLM与Diffusion Model训练统一多模态模型的尝试中,理解与生成任务通常采用同一个视觉编码器(如Show-O [1] 中理解和生成均采用MAGVIT-v2将图片转换成离散token,Transfusion [2] 中理解和生成均采用latent space里的U-Net Encoder),往往导致理解和生成任务在视觉编码层面的冲突。在我们的上一个工作 Janus [3] 中证实了对多模态理解和生成任务的编码器进行解耦能有效缓解冲突,提升模型的整体性能。在 JanusFlow 中,我们沿用了这一设计。我们进行了一系列的消融实验探究了不同视觉编码器策略的影响,证实为理解和生成任务分别配置专用编码器能够显著提升整体性能。
正如之前提到的,由于RF的训练收敛速度显著慢于AR,JanusFlow的训练开销较大。得益于我们解耦了理解与生成的编码器,我们可以使用REPA [4] 的方法来加速RF训练的收敛速度。具体而言,我们在生成数据的训练中要求视觉编码器提取的训练图片 x 的特征与其加噪样本 z_t 在LLM中的中间层特征对齐。实验表明,该方法在仅增加少量计算开销的情况下,显著提升了生成任务的收敛效率。
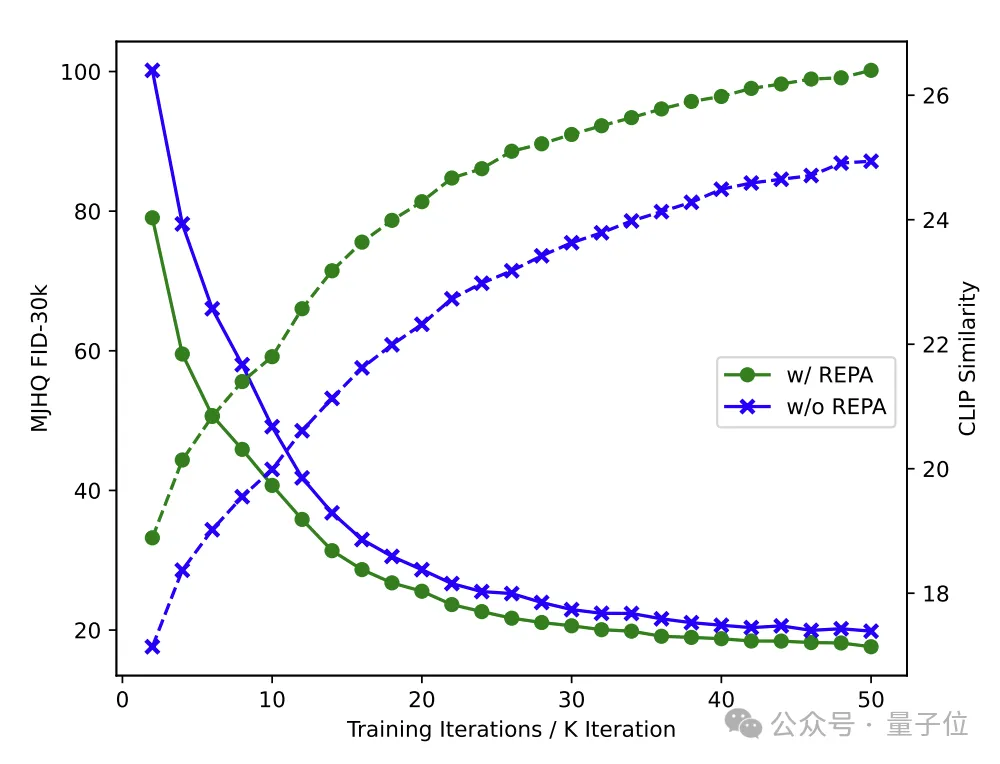
(绿线:使用REPA;蓝线:不使用REPA。使用REPA可以显著加速FID的降低(与图像质量相关)和CLIP score的升高(与文生图模型的语义准确度相关)。)
我们设计了六组对照实验以验证模型各组件的有效性:
A、不使用REPA,理解模块是SigLIP,生成模块是SDXL-VAE+ConvNeXt Block,联合训练理解与生成任务;
B、使用REPA,理解和生成模块使用共享参数的SDXL-VAE+ConvNeXt Block,联合训练理解与生成任务;这个设置类似Transfusion;
C、使用REPA,理解和生成模块使用独立参数的SDXL-VAE+ConvNeXt Block,其中,理解部分的SDXL-VAE参数参与训练,联合训练理解与生成任务;
D、理解模块是SigLIP,只训练理解数据,保持与联合训练中理解数据等量;这是同一框架和数据量下,理解模型的基准;
E、使用REPA,理解模块是SigLIP,生成模块是SDXL-VAE+ConvNeXt Block,只训练生成数据,保持与联合训练中生成数据等量;这是同一框架和数据量下,生成模型的基准;
F、使用REPA,理解模块是SigLIP,生成模块是SDXL-VAE+ConvNeXt Block,联合训练理解与生成任务。
实验结果如下图。
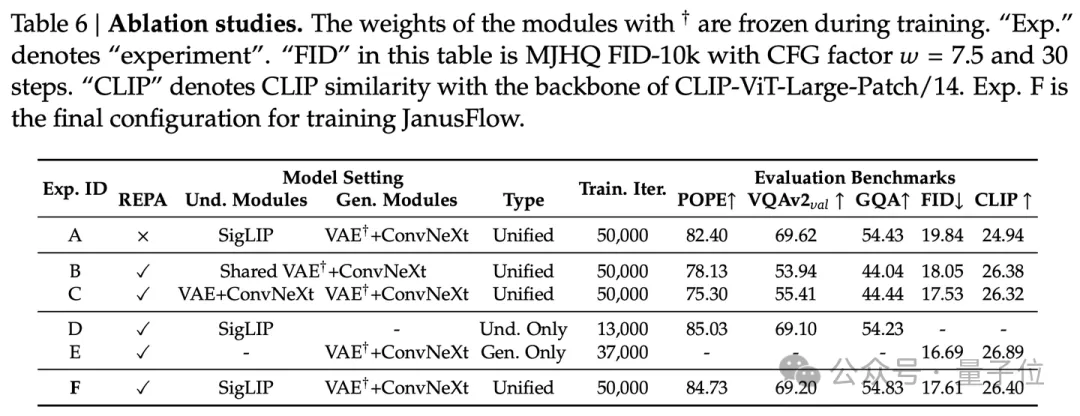
1、比较A和F:REPA的引入显著提升了生成相关的指标
2、比较B,C和F:解耦编码器并使用SigLIP作为理解模块能得到理解和生成能力最好的统一模型
3、比较D,E和F:我们的最终策略F在训练数据量和训练设置均相同的情况下,理解能力与纯理解基准相当,生成能力与纯生成基准基本持平;验证了F在保持各自性能的同时实现了两个任务的有机统一
基于以上实验结果,我们采用方案F作为JanusFlow的最终架构配置。
JanusFlow在DPGBench,GenEval和多模态理解的测评标准上都取得了强大的效果。详见表格。
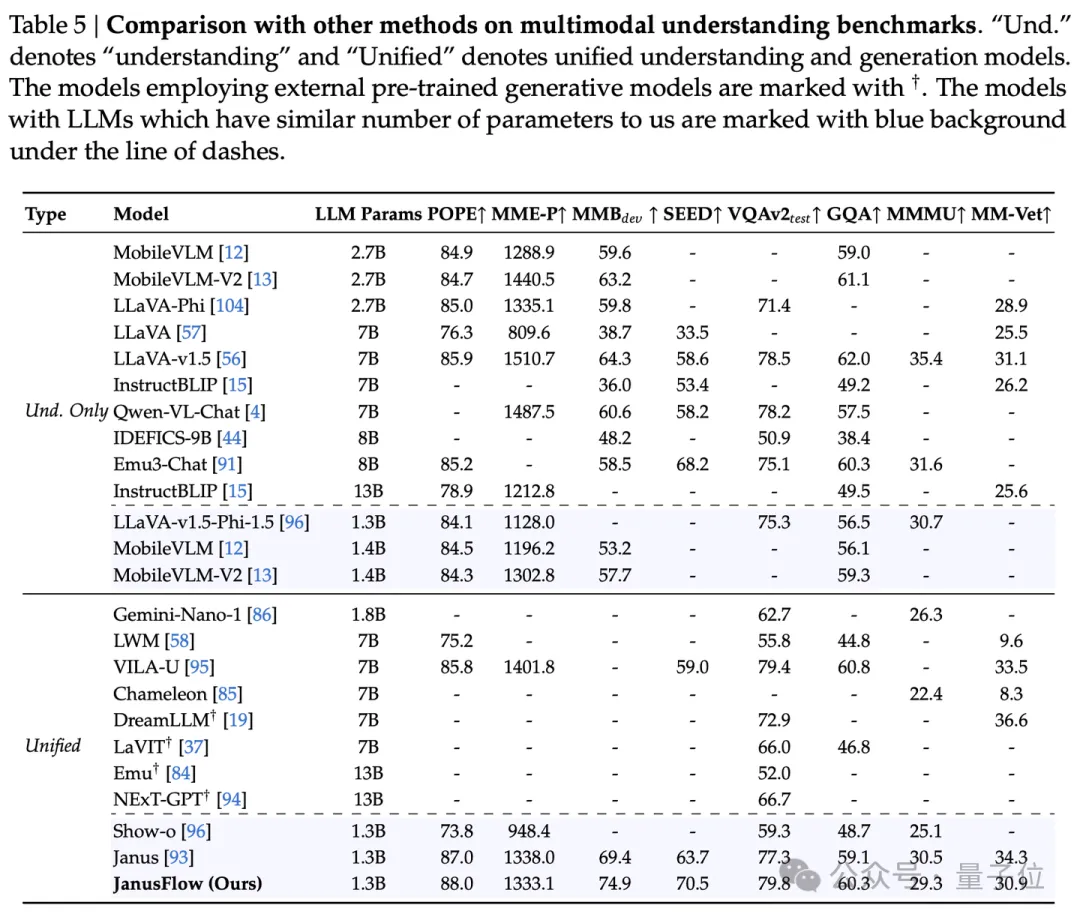
视觉理解分数:JanusFlow超过了一些同尺寸的纯理解模型
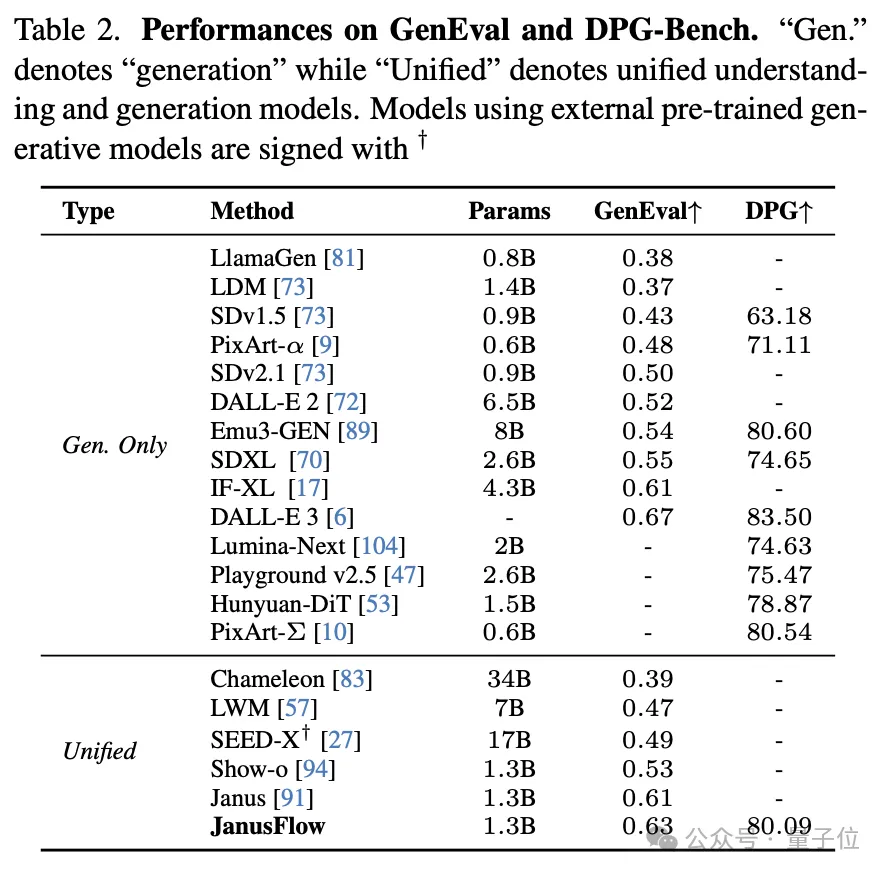
视觉生成分数:JanusFlow有较强的语义跟随能力
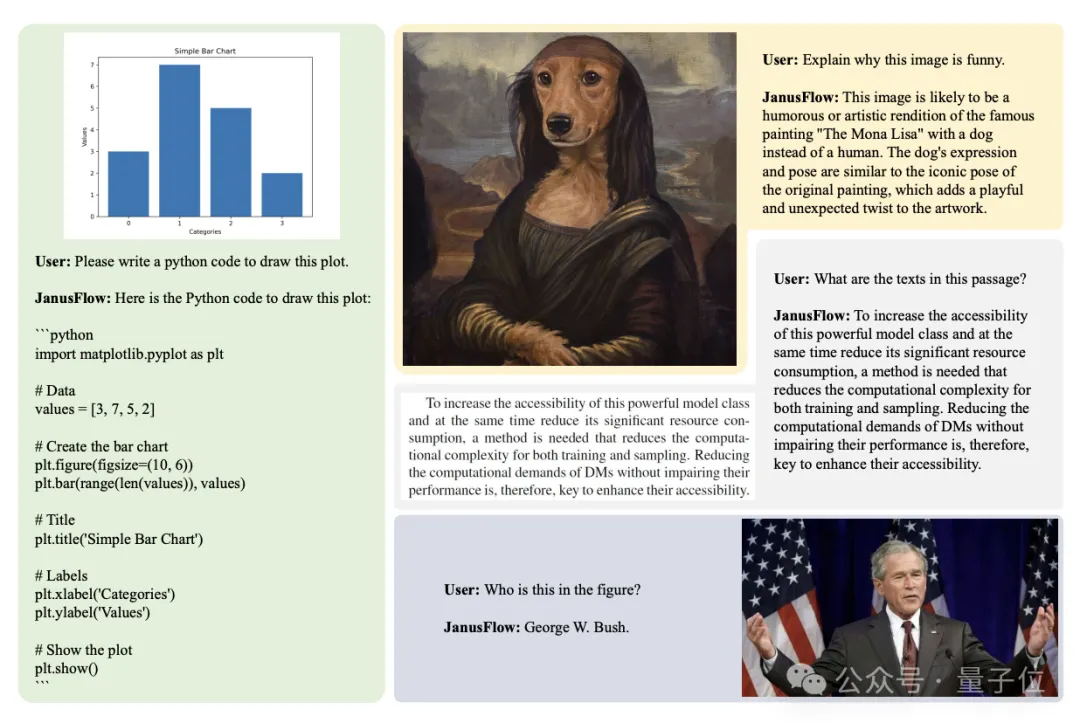
视觉理解主观效果

视觉生成主观效果
最后总结,JanusFlow通过融合自回归LLM与Rectified Flow,成功构建了一个统一的视觉理解与生成框架。该模型具有简洁的架构设计,在视觉理解和生成两大任务上均展现出强劲的竞争力。
论文链接:
https://arxiv.org/abs/2411.07975
项目主页: https://github.com/deepseek-ai/Janus
模型下载: https://huggingface.co/deepseek-ai/JanusFlow-1.3B
在线 Demo: https://huggingface.co/spaces/deepseek-ai/JanusFlow-1.3B
相关文献:
[1] Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
[2] Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
[3] Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
[4] Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
文章来自于“量子位”,作者“Janus团队”。



