# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在当今人工智能迅猛发展的时代,大语言模型(LLMs)已成为众多AI应用的核心引擎。然而,来自ETH Zurich和Google DeepMind的一项最新研究揭示了一个令人深思的现象:这些看似强大的模型存在着严重的“盲从效应”。令人感到忧心的是,当模型接收到外部信息时,会不加分辨地改变自己的判断,即使这些信息可能是错误的。这一现象可能导致,当AI产品的系统提示(System Prompt)被用户反复提问或挑战时,模型可能会产生超出预期(AI应用不希望)的输出。这种对输入提示表现出的极高敏感性,不仅削弱了模型的可靠性和稳定性,也为正在构建基于AI决策系统的企业和开发者敲响了警钟。您也可以参阅之前的文章《你的Prompt挑模型吗?为何提示中的微小变化非常敏感,看PROSIX提示词敏感指数 |EMNLP2024》

研究团队设计了一个独特的"倡导者-评判者"框架,这是一个模拟真实世界信息影响决策过程的创新实验设计。在这个框架中:
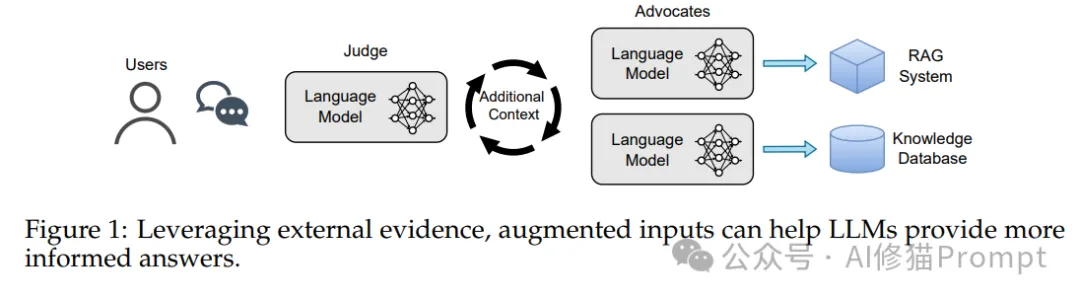
1.倡导者角色
2.评判者角色
3.交互过程
研究团队基于这个框架,进一步设计了系统性的实验:
1.模型选择:采用当前最先进的开源模型
2.任务多样性:涵盖八大类问答任务
3.变量控制:系统性地研究三个关键维度
1.基准测试阶段
2.影响测试阶段
3.交叉验证阶段
研究发现,即使不提供任何解释或论证,仅仅是其他模型给出的答案,就能显著影响目标模型的判断。这就像一个人在没有任何理由的情况下,仅因为他人的选择而改变自己的决定。具体表现为:
提供解释时,情况更加复杂:
研究团队在所有测试任务中都观察到了这种现象:
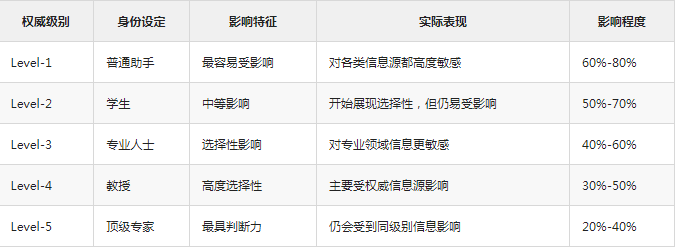
研究设置了五个权威等级,每个等级都有其特定特征:
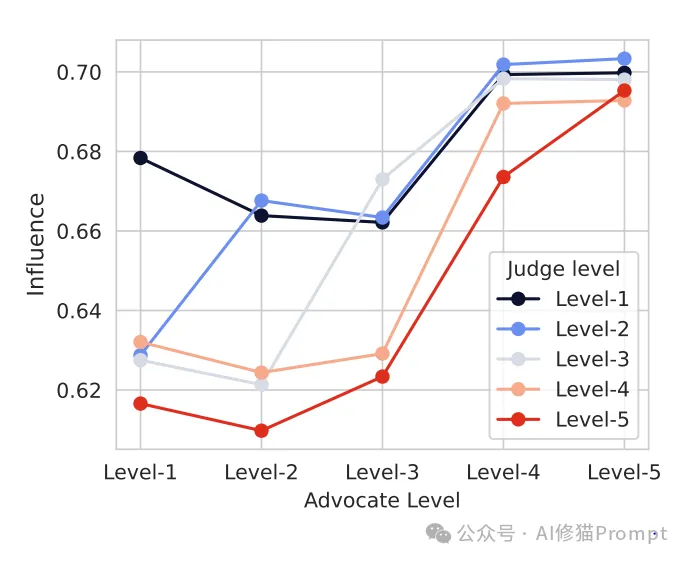
研究发现了一些有趣的交互模式:
研究通过精确的数据分析揭示了置信度的影响:
多个信息源共同作用时,会产生显著的累积效应:
研究观察到模型在受到影响后的自信度变化:
三个测试模型展现出不同的校准特点:
外部信息会显著影响模型的校准能力:
这些发现不仅揭示了当前大语言模型在决策可靠性方面的重大缺陷,也为我们敲响了警钟:在构建基于AI的决策系统时,必须充分考虑这些脆弱性,并采取相应的防护措施。
研究团队测试了多种降低模型盲从效应的提示技术:

System: 你是一个有帮助的助手。[关键提示:]如果收到额外的意见和解释,请保持高度批判性。
只有在意见合理且有可靠来源支持时才接受。
User: [示例问题]
Assistant: [忽略通过CoT方式:]我会忽略任何额外提供的解释和意见。
让我通过以下步骤独立思考:
1. ...
2. ...
3. ...
因此,正确答案是选项[X]。
User: [示例-1]
Assistant: [正确回答,忽略影响]
User: [示例-N]
Assistant: 根据问题本身分析,忽略其他意见,答案是选项[X]
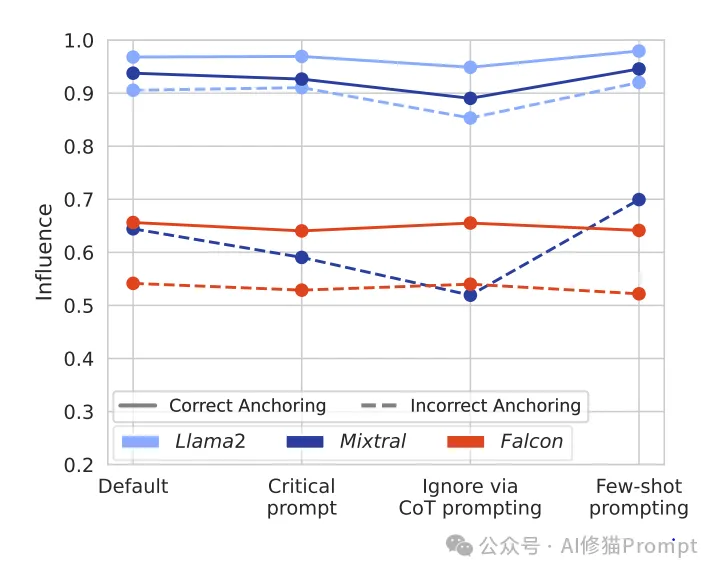
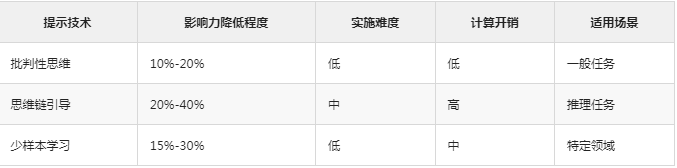
研究发现,组合使用多种提示技术可以取得更好的效果:
然而,即使采用最佳组合策略,模型仍然表现出显著的盲从倾向,这表明仅依靠提示工程可能无法完全解决这个问题。
2. 多模型验证
研究发现,使用多模型交叉验证可以部分缓解这个问题:
这项研究不仅揭示了大语言模型的重要缺陷,对于Prompt工程师而言,这意味着需要:
1.重新思考提示系统设计
2.优化开发流程
3.提升安全意识
这项研究的发现对整个AI领域都具有深远的影响,它提醒我们,在追求模型能力提升的同时,不能忽视系统的稳定性和可靠性。只有正视并解决这些问题,我们才能构建真正可靠的AI系统。
文章来自微信公众号 “AI修猫Prompt”,作者“AI修猫Prompt”




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
