# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在人工智能领域,大语言模型(LLM)的向量嵌入能力一直被视为处理文本数据的利器。然而,斯坦福大学和Google DeepMind的研究团队带来了一个颠覆性发现:LLM的向量嵌入能力可以有效应用于回归任务。通过将输入数据转换为文本形式(JSON格式),利用LLM的嵌入模块获取高维向量表示,再将这些向量作为下游回归任务的特征输入,这种方法在某些高维回归任务中的表现甚至超越了传统特征工程方法。
关于输入格式可以参考这篇文章《微软和麻省理工权威发布:Prompt格式显著影响LLM性能,JSON比Markdown准确性高42%》
这一发现具有重大意义。它不仅拓展了LLM向量嵌入的应用范畴,更为解决复杂的回归问题提供了全新思路。特别是在当前AI技术快速迭代的背景下,这种将LLM嵌入能力与传统机器学习任务结合的创新方法,为AI产品开发提供了新的可能性。

这一突破性的发现不仅拓宽了LLM的应用范畴,更为解决复杂的回归问题提供了新的思路。对于AI从业者和Prompt工程师而言,这意味着有机会利用LLM的强大嵌入能力,革新传统的数据建模方法。
研究团队通过大量实验,证实了LLM嵌入在处理高维数据时的卓越性能:
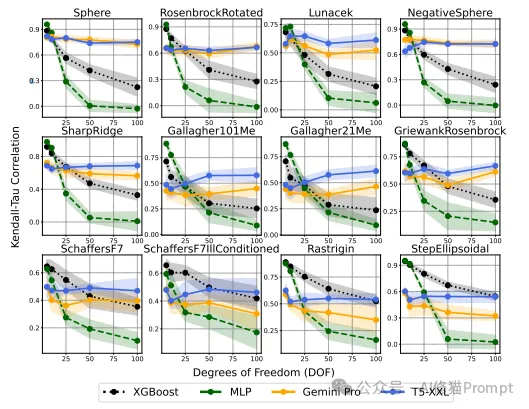
工程启示:Prompt工程师可以利用LLM嵌入在高维和噪声数据中的稳健性,减少繁琐的特征工程工作,更快速地适应不同领域的需求。
研究揭示,LLM嵌入的输入输出空间满足李普希茨连续性,为优化算法的有效性提供了理论基础。
李普希茨连续性(Lipschitz Continuity)是一种数学概念,用来描述函数的平滑程度。简单来说,假设一个函数 ( f(x) ) 满足以下条件:
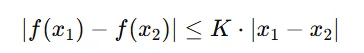
对于所有 ( x_1 ) 和 ( x_2 ),其中 ( K ) 是一个非负常数,被称为李普希茨常数。这意味着函数 ( f(x) ) 的变化不会超过输入 ( x ) 的变化乘以一个固定比例 ( K )。这种性质表明函数的增长是有界的、平滑的。
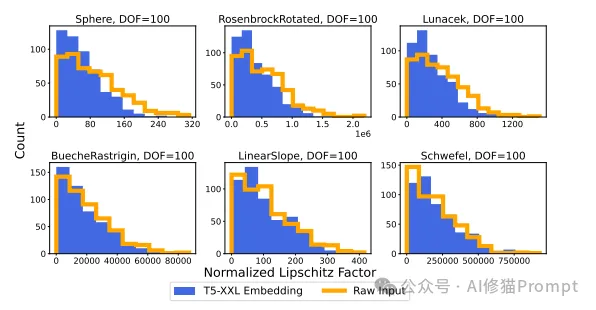
在本文中,研究团队发现LLM嵌入具有良好的李普希茨连续性,这意味着嵌入空间的变化对输入变化的反应是平滑和有界的。这一特性在以下几个方面具有重要意义:
LLM嵌入空间的平滑性表明:
由于嵌入空间的变化是平滑的,模型在训练过程中具有以下优化优势:
LLM嵌入空间中的点呈现紧密的簇状分布,类似点在空间中相距较近,而不同类别的数据点则相隔较远。这种几何特性来源于李普希茨连续性,具体表现为:
李普希茨连续性提供了理论支持,解释了为什么LLM嵌入在回归任务中能够胜过传统方法。它为优化过程的稳定性和效率奠定了基础。
研究发现,LLM的最佳性能并非简单地与模型规模正相关:

工程启示:Prompt工程师应根据具体任务需求,选择适当规模的模型,注重数据质量,而非盲目追求模型规模。
1.AutoML场景:
2.系统性能优化:
3.机器学习模型调优:
4.基础设施配置:
1.LLM嵌入在高维数据处理上的优势:
2.数学特性的验证为优化提供了理论支持:
3.模型规模与数据质量的平衡至关重要:
1.技术选择:
2.实施策略:
3.发展方向:
斯坦福大学和Google DeepMind的这项研究,揭示了LLM嵌入在回归任务中的巨大潜力,突破了传统对LLM应用范围的认知。
对于Prompt工程师和AI从业者而言,这些发现具有重要的实践指导意义。在未来的工作中,如何有效地将LLM嵌入技术应用于实际问题,提升模型性能和效率,将是一个充满机遇和挑战的课题。欢迎和我交流,以下是之前文章的资料赠予介绍。
文章来自微信公众号“AI修猫Prompt”,作者“AI修猫Prompt”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
