# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
颠覆现有Agent范式、让AI拥有“主动能动性!
清华&面壁等团队最新开源新一代主动Agent交互范式 ( ProActive Agent)。
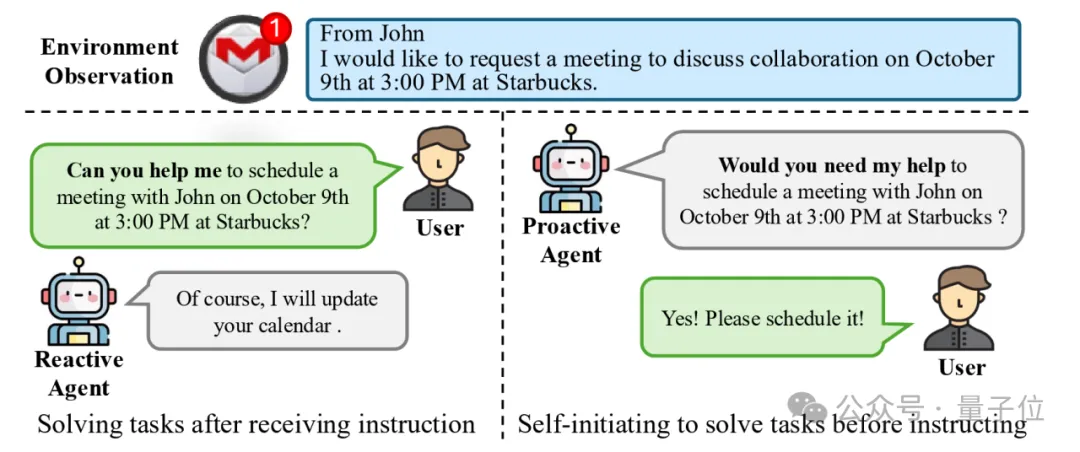
图1:两种人类与智能体交互形式的比对。左侧的被动式Agent只能被动接受用户指令并生成回复,而右侧的主动式Agent 可以通过观测环境主动推断与提出任务。
当前,哪怕是ChatGPT等最先进的AI Agent都是传统的被动式Agent (上图1左侧所示),即需要用户通过明确的指令显示告诉Agent应该做什么,Agent才能继续执行接下来的任务。
新范式下的Agent不再是简单的指令执行者,而是升级成为了具有”眼力见”的智能助手(上图1右侧所示)。
它具备”眼中有活、主动帮助”的主动能动性,能够主动观察环境、预判用户需求,像”肚子里的蛔虫”一样,在未被明确指示的情况下主动帮用户排忧解难。

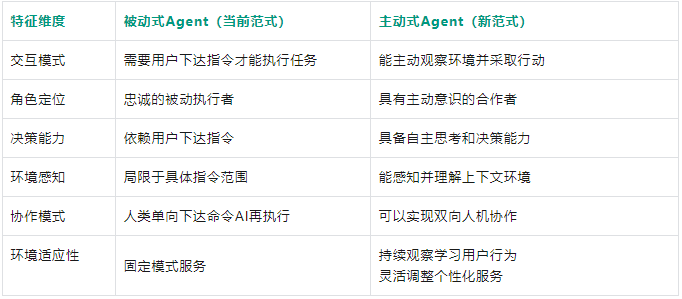
为了更清晰地理解这一技术突破的意义,我们可以通过以下表格来详细分析对比两种范式的本质区别:
主动Agent交互范式在日常生活中有丰富的应用潜力,以下是一些近期预想可实现的场景:
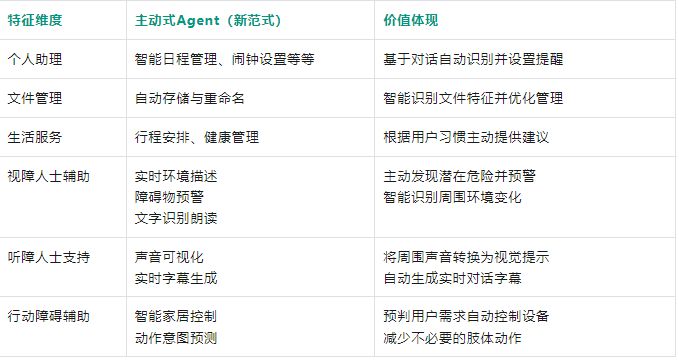
在一段情侣聊天的场景中,男生邀请女生一起要在周六去环球影城并于早上八点来接女生。
当Agent获取用户授权之后随时保持在线的“候命状态”,当Agent通过上下文聊天内容实时识别到女生的需求,在没有用户明确下指令的情况下,Agent主动帮女生定了一个周六早上七点的闹钟用来提醒起床。
当用户在电脑上接收到一份重要文件(学习课件、发票等)时,Agent 主动帮用户把文件存到了本地,并自动识别出PDF文件第一页显示的标题然后帮用户把文件名进行了重命名。
该研究除了提出以上开创性的主动Agent之外,还通过采集不同场景下的人类活动数据构建了一个环境模拟器,进而构建了数据集 ProactiveBench,通过训练模型获得了与人类高度一致的奖励模型,并比对了不同模型在数据集下的性能。
下图展示了主动Agent技术原理的整体流程。为了让智能体能够主动提出任务,该研究设计了三个组件以模拟不同场景下的环境信息,用户行为和对智能体提出任务的反馈。
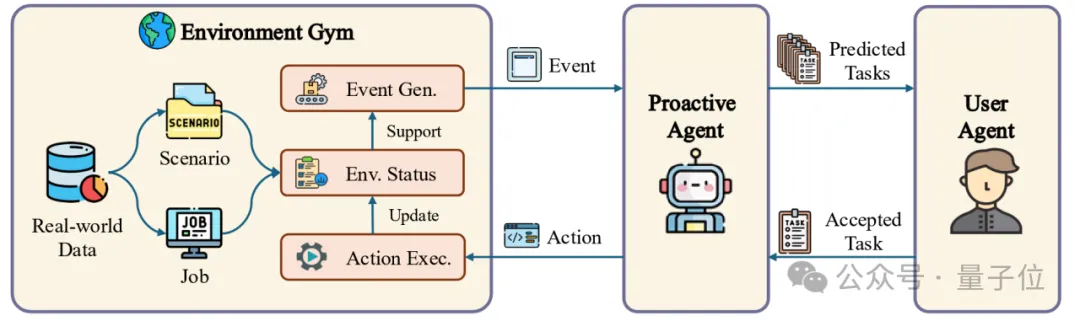
图2 数据生成过程总览。该过程包含了初始环境与任务设置,事件生成,主动预测,用户判断和行动执行。
其中:
1、环境模拟器模拟了一个特定环境,并为智能体的交互提供了一个沙盒条件。
模拟器通过使用基于 Activity Watcher软件采集到的真实人类数据以提升生成事件的质量。
环境模拟器的主要功能为事件生成与状态维护:通过使用GPT-4o 从人类注释员处收集的种子事件以生成一个需要交互的具体环境,同时生成所有相关实体以让智能体执行任务。
对于每个场景,环境模拟器接收用户活动并生成详细的,逻辑通顺合理的事件,环境模拟器将会持续生成事件,更新实体状态,产生特定反馈,直到当前环境下没有更多事件以供生成。
2、主动智能体将会通过环境模拟器提供的信息预测用户意图,生成预测任务。
每当智能体接受一个新事件后,它将首先更新自己的记忆,结合用户之前的反馈和历史交互信息,主动智能体将能够结合用户性格提出可能的任务。
如果主动智能体没有检测到需要,其将保持静默,反之将会提出一个任务。一旦此任务被用户接受,那么主动智能体将在环境模拟器中执行该任务,并进而产生后续的系列事件。
3、用户智能体将模拟用户行为并对主动智能体的任务做出反馈。
用户智能体为经过提示的 GPT-4o,在获取预测之后,用户智能体将会决定是否接受任务。
该研究通过从人类标注员处收集判断,并训练一个奖励模型以模拟这一过程。人类标注员在研究开发的标注平台上进行标注,对特定时间下,9个不同的大语言模型生成的多样化预测进行判断,并通过多数投票的方式决定某个回合用户是否具有需求,以及用户倾向于接受什么类型的任务。
值得一提的是,人类标注员在测试集上达到了91.67%的一致性,充分说明了测试集的可靠性。
该研究提出了一套度量方式衡量奖励模型和人工标注员的一致性。
在这四个度量方式上进行召回率、精确度、准确度和 F1 分数的计算,从结果上看,所有的现有模型都在正确检测上表现良好,但对于其他指标则性能较差。现有模型倾向于接受智能体的任务,尽管可能毫无助益。相对的,该研究训练的模型性能最优,因此被选为 ProactiveBench 的奖励模型。
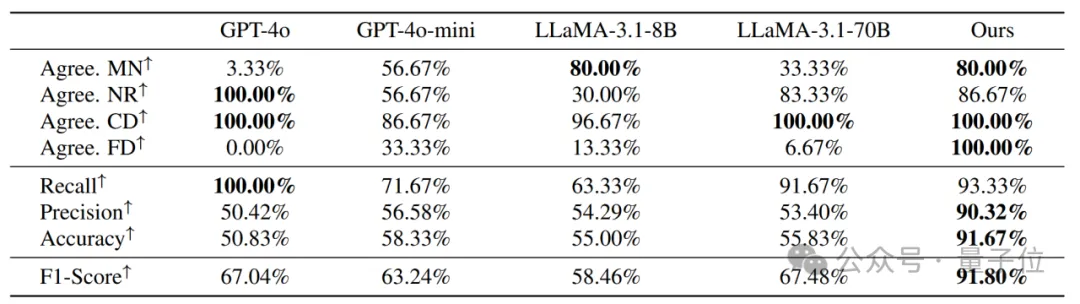
图表3 不同模型作为奖励模型的评测结果。研究展示了模型与人工标注员多数投票结果之间的一致性。在 LLaMA-3.1-instruct-8B 微调的模型取得了最好结果。
通过奖励模型,可以进一步衡量主动智能体的性能表现。该研究在不同的模型上进行了评估,并将模型预测的结果交由奖励模型进行评价。从结果上看,闭源模型会倾向于主动提出任务而不能在用户无需帮助时保持静默,模型提供的任务往往过于抽象或无用,以至于产生较高的误报率。对于开源模型,经过数据集训练的模型明显更优,这证实了研究数据合成流水线的有效性。同时,经过训练的模型也在误报率上有了明显的下降,尽管提供不必要的帮助的情况仍然存在。
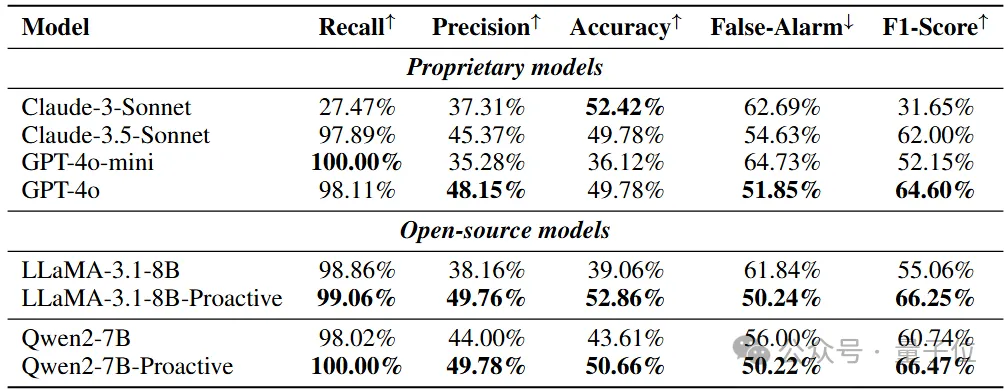
图表4 不同模型在 ProactiveBench 数据上的评测结果。GPT-4o 在闭源模型中脱颖而出,对于开源模型,基于 Qwen2-7B 微调的结果取得最好成果。
研究同样进行了消融学习以研究提出任务数量和用户反馈对于智能体性能的影响。通过让模型提出多个可能的任务并一一进行判断,所有的模型在指标上都有明显的上升。通过给予模型来自奖励模型的反馈,所有的模型误报率都有所下降,准确度有所上升,但在召回率的表现上有明显下降。通过结合奖励模型,主动智能体可以更好的检测用户需求,降低误报率。
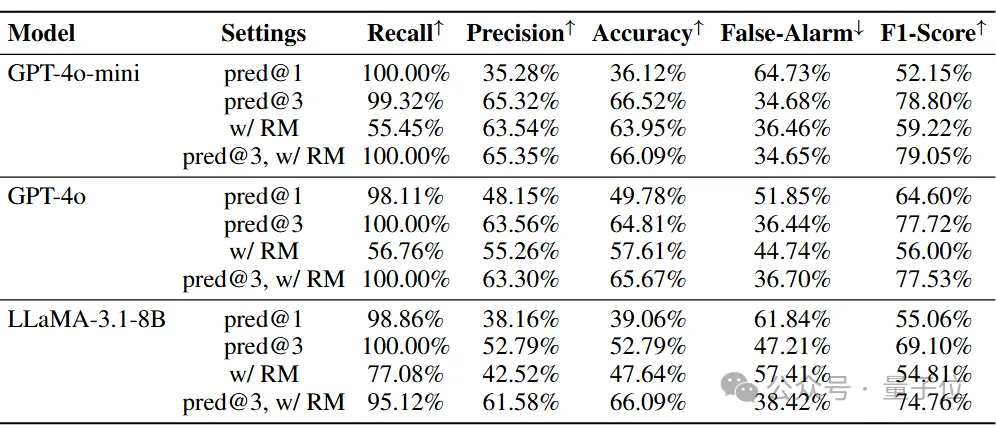
图表5 基准线,多任务预测,获取反馈之间的比较。结果表明所有的模型都有所提升。模型的误报率由于接受预测的可能性更高或被奖励模型改进而显著下降。
主动Agent(ProActive Agent)范式有望将AI从被动的工具转变为具有洞察力和主动帮助的智能协作,从而开启人机交互新革命。
论文链接:https://arxiv.org/abs/2410.12361
Github地址:https://github.com/thunlp/ProactiveAgent
文章来自于微信公众号 “量子位”,作者“清华&面壁团队”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
