# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
曾经参与过公司内部的RAG应用,写过一篇关于RAG的技术详情以及有哪些好用的技巧,这次专注于总结一下RAG的提升方法。
还是老样子,深入浅出希望给更多的人进行科普。
RAG简单来说就是给予LLM的一些增强
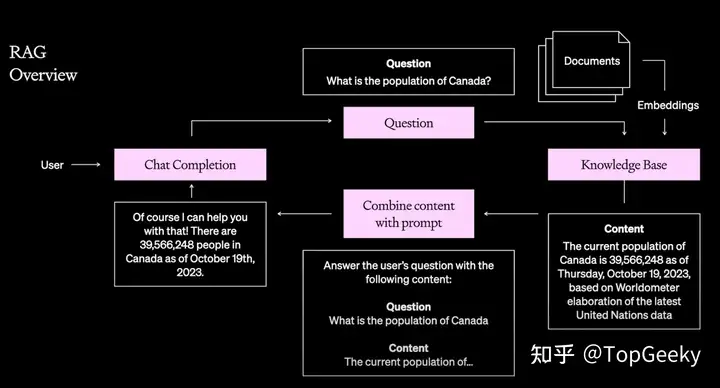
简单来说,RAG主要是由检索和生成两个阶段组成:

作者:TopGeeky
链接:https://www.zhihu.com/question/643138720/answer/3495870046
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
RAG 模型严重依赖于检索到的上下文文档的质量。如果检索器无法找到相关的事实段落,就会严重妨碍模型根据有用信息并产生准确、深入的响应的能力。
特别是现在,稀疏向量检索在语义匹配和检索高质量文档存在困难
解决方案:
虽然外部知识对于高质量的 RAG 输出是必不可少的,但即使是最大的语料库也无法完全覆盖用户可能查询的实体和概念。如果无法访问全面的知识源,该模型就会返回对利基或新兴主题的无知、通用的响应。
解决方案:
即使具有良好的检索能力,RAG 模型也常常难以正确地调节上下文文档并将外部知识合并到生成的文本中。如果没有有效的情境调节,就无法产生具体的、真实的反应。
解决方案:
对于新增加的文档而言,RAG模型确定所需要检索的内容并用于生成是十分困难的,特别是针对长内容的处理。这就需要针对新增加的信息进行清洗和划分。
解决方案:
在检索源数据时候,需要有效的方法给检索的数据进行排名,找到最想相关的数据才能更好的得到内容。
解决方案:
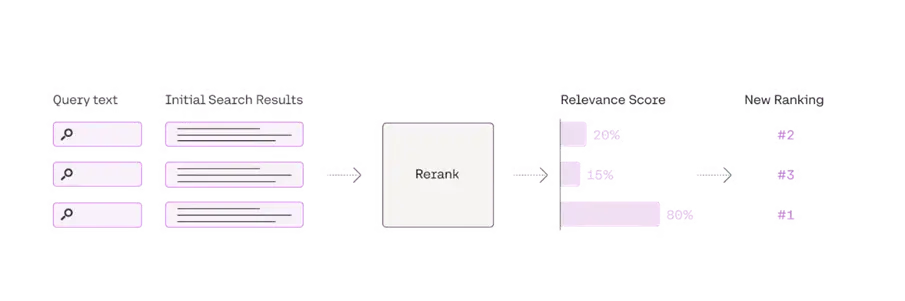
生成阶段: 痛点和解决方案
由于过度依赖语言模型先验,RAG 模型经常生成看似合理但完全错误或不忠实的语句,而没有在检索到的上下文中进行验证。
解决方案:
与传统的 QA 系统不同,RAG 模型无法了解生成文本背后的推理。模型的可解释性仍然是含蓄和不透明的,而不是明确的。
解决方案:
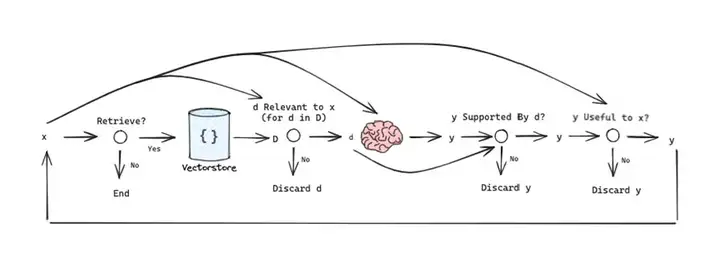
检索与生成的耦合阻碍了 RAG 模型与标准语言模型的延迟匹配。推理管道缺乏对需要毫秒响应的实时应用程序的优化。
解决方案:
在通用语料库上训练的 RAG 模型缺乏针对特定用户需求、上下文和查询生成响应的能力。如果没有个人理解,他们无法解决模棱两可的信息请求。
解决方案:
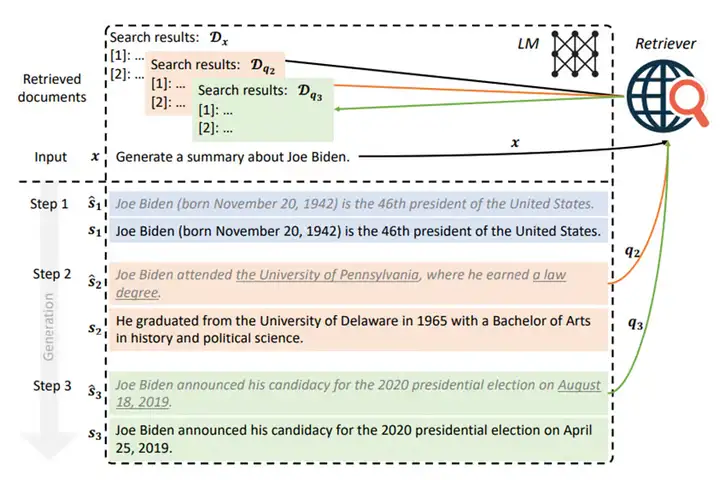
可能的接地响应的多样性使得使用自动化指标可靠地评估 RAG 模型输出的正确性和质量变得具有挑战性。人类评估也缺乏可扩展性。这阻碍了迭代改进。
解决方案:
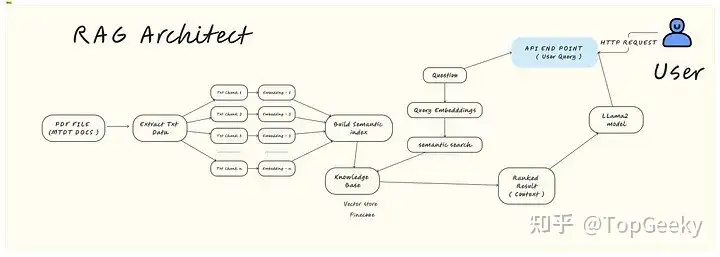
在RAG架构中会存在一下评价指标
RAG 是一种很有前途的提高 LLM 准确性和可靠性的方法,具有事实依据、减少偏见和降低维护成本等优点。虽然未知识别和检索优化等领域仍然存在挑战,但正在进行的研究正在突破 RAG 功能的界限,并为更值得信赖和信息丰富的LLM应用铺平道路。
文章来自 “知乎‘,作者 “TopGeeky” 重庆大学 软件工程硕士




【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
