从 RAG 到 Context:2025 年 RAG 技术年终总结
从 RAG 到 Context:2025 年 RAG 技术年终总结过去的 2025 年,对于检索增强生成(RAG)技术而言,是经历深刻反思、激烈辩论与实质性演进的一年。
来自主题: AI技术研报
8598 点击 2025-12-22 09:37
 搜索
搜索
过去的 2025 年,对于检索增强生成(RAG)技术而言,是经历深刻反思、激烈辩论与实质性演进的一年。
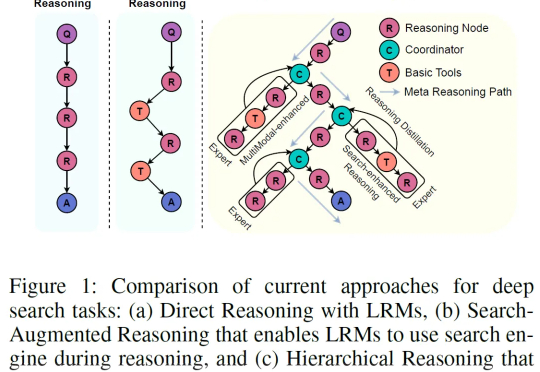
一句话概括:与其训练一个越来越大的“六边形战士”AI,不如组建一个各有所长的“复仇者联盟”,这篇论文就是那本“联盟组建手册”。

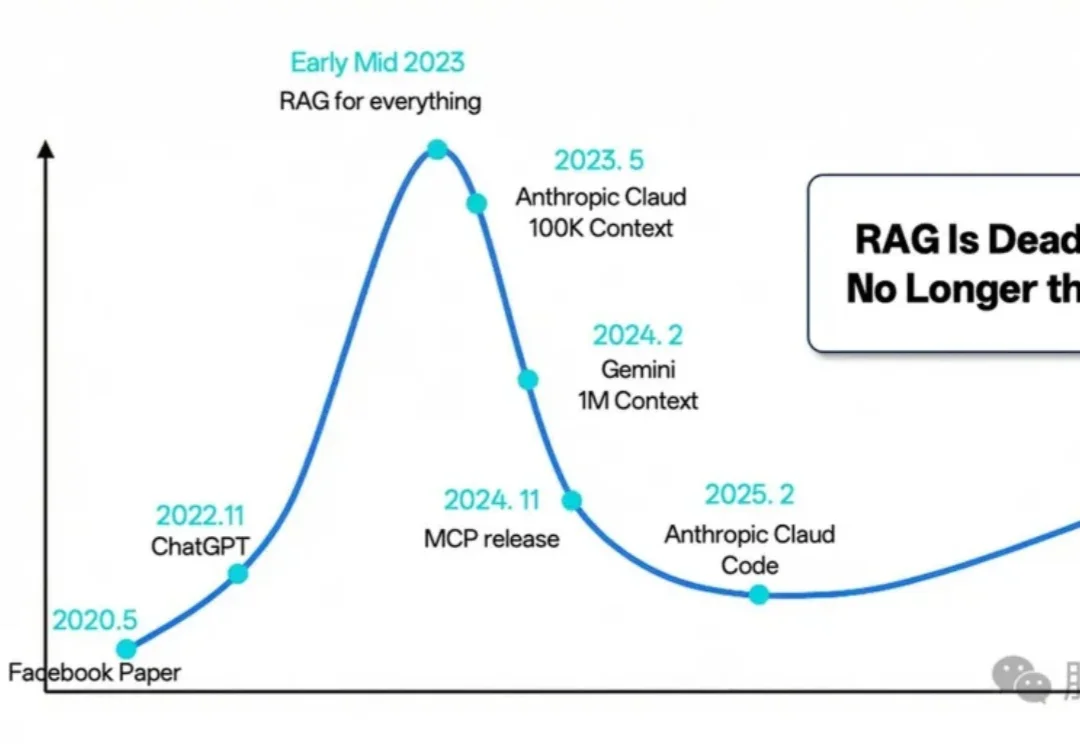
2023年至今,检索增强生成(RAG)经历了从备受瞩目到逐渐融入智能体生态的转变。尽管有人宣称“RAG已死”,但其在企业级应用中的重要性依然无可替代。RAG正从独立框架演变为智能体生态的关键子模块,2025年将在多模态、代理融合、行业定制化等领域迎来新的突破。
本文将介绍 22 种先进的RAG技术,灵感来源于 all-rag-techniques 仓库中的全面实现。这些实现使用 Python 库(如 NumPy、Matplotlib 和 OpenAI 的嵌入模型),避免使用 LangChain 或 FAISS 等依赖,以保持简单性和清晰度。

当前,Agentic RAG(Retrieval-Augmented Generation)正逐步成为大型语言模型访问外部知识的关键路径。但在真实实践中,搜索智能体的强化学习训练并未展现出预期的稳定优势。一方面,部分方法优化的目标与真实下游需求存在偏离,另一方面,搜索器与生成器间的耦合也影响了泛化与部署效率。
作为一家在银行技术领域拥有超过 30 年行业经验的领军供应商,我们拥有丰富且极具创新性的代码库,并通过战略性收购不断扩大业务。
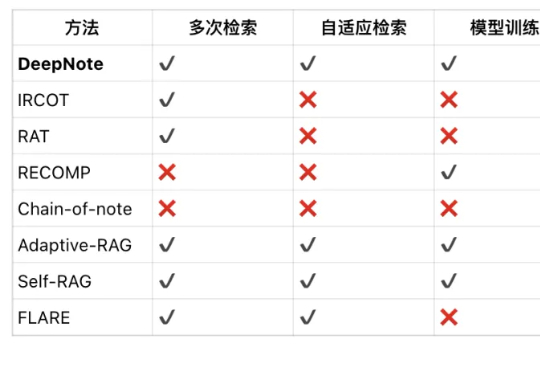
在当前大语言模型(LLMs)广泛应用于问答、对话等任务的背景下,如何更有效地结合外部知识、提升模型对复杂问题的理解与解答能力,成为 RAG(Retrieval-Augmented Generation)方向的核心挑战。
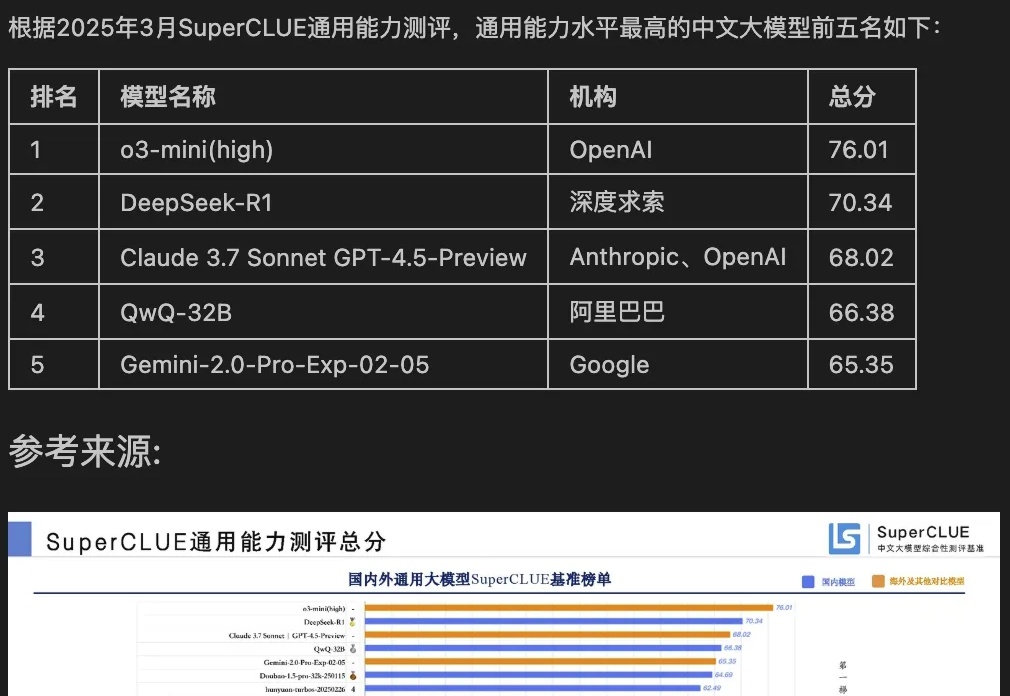
随着技术的深入应用,如何高效利用大模型技术优化用户体验,同时应对其带来的诸多挑战?本文将从RAG的发展趋势、技术挑战、核心举措以及未来展望四个维度总结我们应对挑战的新的思路和方法。

作为一名从业七年的程序员,最近听到很多程序员朋友都喜提了n+1裁员大礼包。
RAG应用的一大复杂性体现在其多样的原始知识结构与表示。特别在企业场景下,混合多种媒体形式且具有复杂布局的文档随处可见,比如一份PPT: