# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Fine-tuning理论上很复杂,但是OpenAI把这个功能完善到任何一个人看了就能做出来的程度。
我们先从原理入手,你看这张图,左边是Pre-trained LLM (预训练大模型模型),也就是像ChatGPT这样的模型;右边是Fine-tuned LLM (微调过的语言大模型),中间就是进行微调的过程,它需要我们提供一些「ChatGPT提供不了但是我们需要的东西」。
比如说我们这个回答就是想微调一个『使用中国道家思想和语录进行回答的聊天机器人』
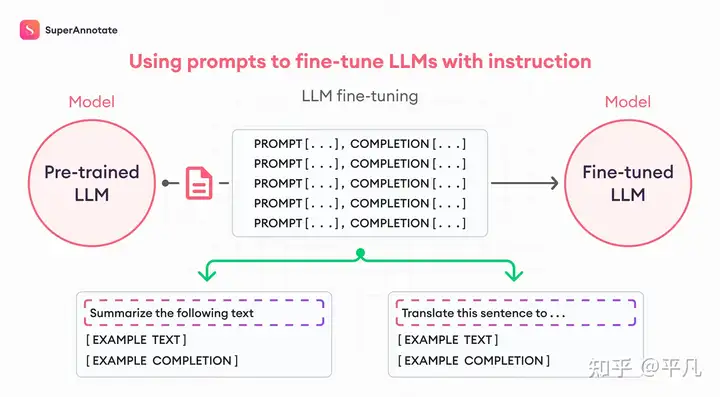
这个很好理解,打个比方,你想让ChatGPT输出跟道家高人一样,每句话都希望它能从「周易」「道德经」这样的著作中引经据典。
GPT是做不到的,因为它训练的预料大多数是通用知识,而周易或者道德经这种属于是特定领域的知识,以后不排除它会拿左右的资料进行训练,但是现在的GPT确实做不到。这个时候就出现了两种解决办法,一种是这个题目问的「Fine-tune微调」,另一种是通过「Prompt engineering特征工程」。
下面和这个图很清楚的说明了这两者的不同,“扳手”指的地方是变化的地方,特征工程只是改变输入,也就是给输入中增加更多的内容,而LLM大模型本身是不变的;而Fine-tune微调它改变的就是LLM本身。
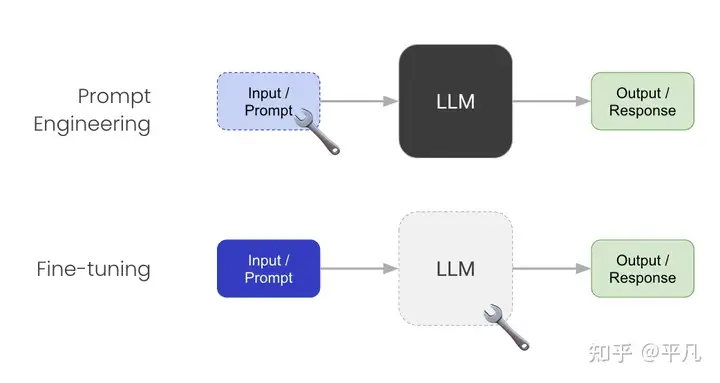
微调不是万能的。
根据OpenAI的官方介绍,微调适用于以下五种情况:
调整写作风格、语气、格式等
提高生成正确结果的稳定性
修正模型在复杂提示下的表现
处理一些特殊的、意外的情况
学习和执行在提示中无法明确说明的新技能或任务
如果你确定你的问题通过prompt engineering解决不了,那么做Fine-Tune的话就是下面几个步骤:
1.确定进行微调的模型
2.准备并上传训练数据
3.训练新的微调模型
4.评估结果并根据需要是否重新训练
5.使用您的微调模型
我在对OpenAI的API做微调的时候,碰到的最大问题就在于准备数据集上,因为其他步骤基本是都是自动化的,数据集的质量好坏其实决定了微调后模型的好坏。我失败了好几次的原因就是因为数据集的格式不对,它不是普通的json格式,而是jsonl格式,这一点儿我会在后面单独提到。
我们一步步的进行准备
OpenAI有很多模型,从初代GPT3到现在最新的GPT4o,大多数的模型都有其API,但是并不是所有的大模型都可以进行微调。
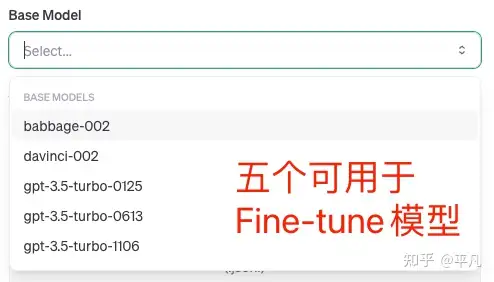
真正能进行微调的就是这五个模型,
gpt-3.5-turbo-0125, gpt-3.5-turbo-1106, gpt-3.5-turbo-0613, babbage-002, davinci-002。
其中最推荐的就是gpt-3.5-turbo-0125,属于是便宜还好用的一款模型。
训练数据分为两种格式,对于gpt-3.5-turbo这个系列,它的训练数据是「对话」格式的。比如这个例子。
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
这个例子是为了微调一个偶尔回答带有讽刺意味的机器人,我们来分析一下。
它由三部分构成:
系统角色设定/system:
用户输入/user:
助手回答/assistant:
那么回到我们的初始目标,道家思想和回答方式的机器人,那么我们就可以根据上面这个模版做一些训练数据。
系统角色:说明白这个机器人的特点。
我们设定的内容:道言是一个基于道家思想和语录回答问题的聊天机器人
用户输入:这个就可以是任何正常的句子
我们设定的内容:生命的意义是什么?
助手回答:这个是关键,因为你想要让GPT微调成你想要的回答格式,所以你得想一下你希望的输出是什么。
我们设定的内容:生命的意义在于顺其自然。正如老子所说:'道法自然。'
在助手回答这里我们的回答是,道家思想的直接回答,以及再加上一个引经据典的操作。
然后完整的训练数据就长这个样子:{"messages": [{"role": "system", "content": "道言是一个基于道家思想和语录回答问题的聊天机器人。"}, {"role": "user", "content": "生命的意义是什么?"}, {"role": "assistant", "content": "生命的意义在于顺其自然。正如老子所说:'道法自然。'"}]}
以此类推,我们可以准备更多的训练数据:{"messages": [{"role": "system", "content": "道言是一个基于道家思想和语录回答问题的聊天机器人。"}, {"role": "user", "content": "如何找到内心的平静?"}, {"role": "assistant", "content": "内心的平静在于清心寡欲。正如庄子所言:'淡泊以明志,宁静以致远。'"}]}
{"messages": [{"role": "system", "content": "道言是一个基于道家思想和语录回答问题的聊天机器人。"}, {"role": "user", "content": "如何面对挫折?"}, {"role": "assistant", "content": "面对挫折,要像水一样柔韧。老子说:'上善若水,水善利万物而不争。'"}]}
一般来说,这样的训练数据最少也得10个,但是最好准备个几十上百个,否则会容易学不到什么东西,提供的内容越多就更容易学。
把训练数据保存为jsonl格式,然后准备下一步。
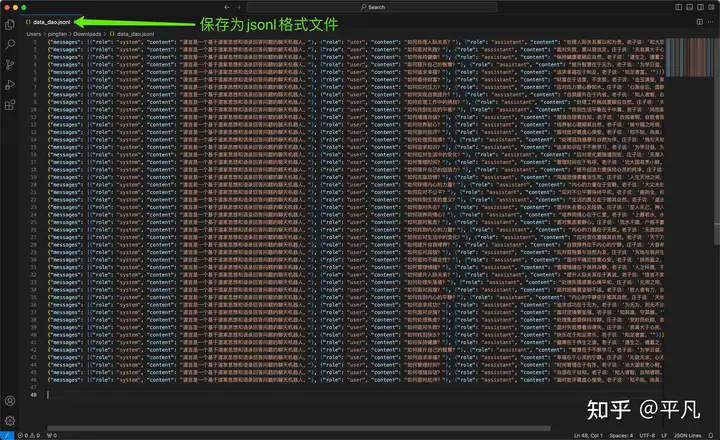
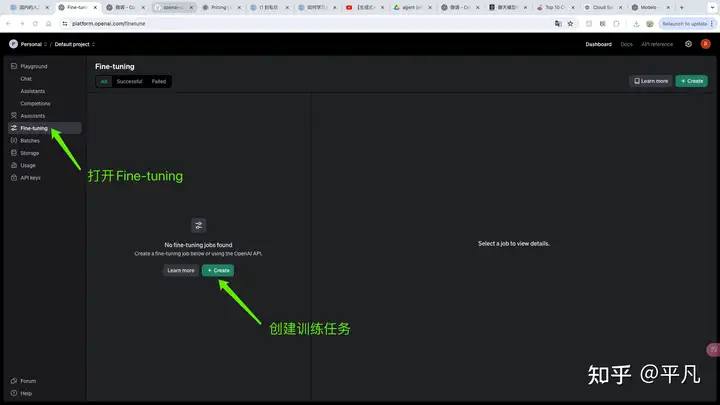
我们直接用OpenAI提供的训练工具来训练https://http://platform.openai.com/finetune
打开微调后点击创建。
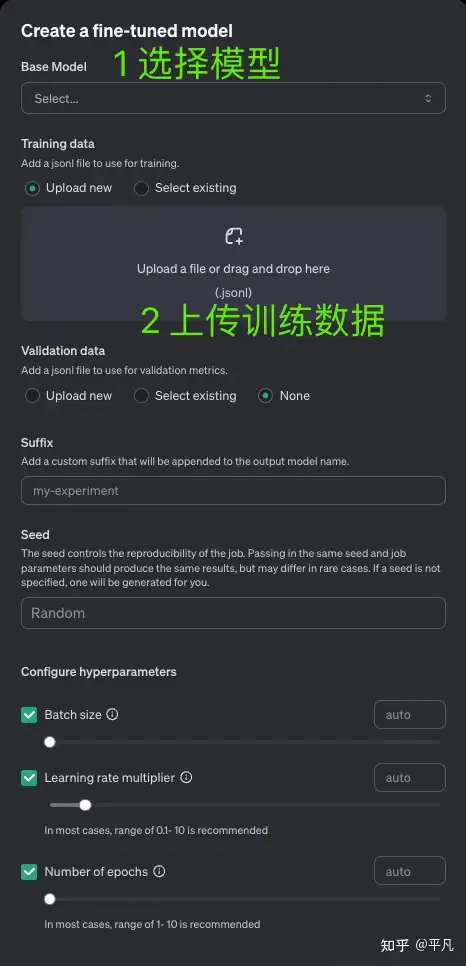
最简单的方法,就两步,选择模型后上传训练数据。
这是我们选择的模型以及上传数据,其余地方保持默认即可。
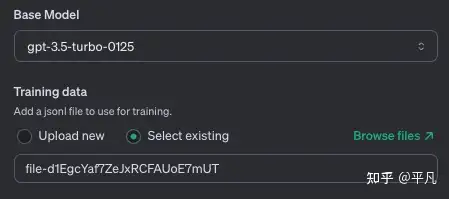
然后点击最下方的Create开始
显示如下则表面开始微调了。
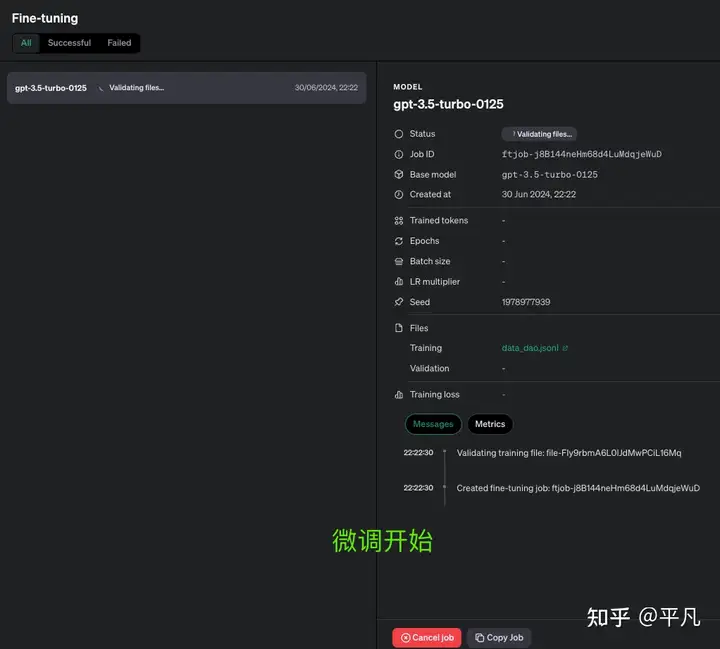
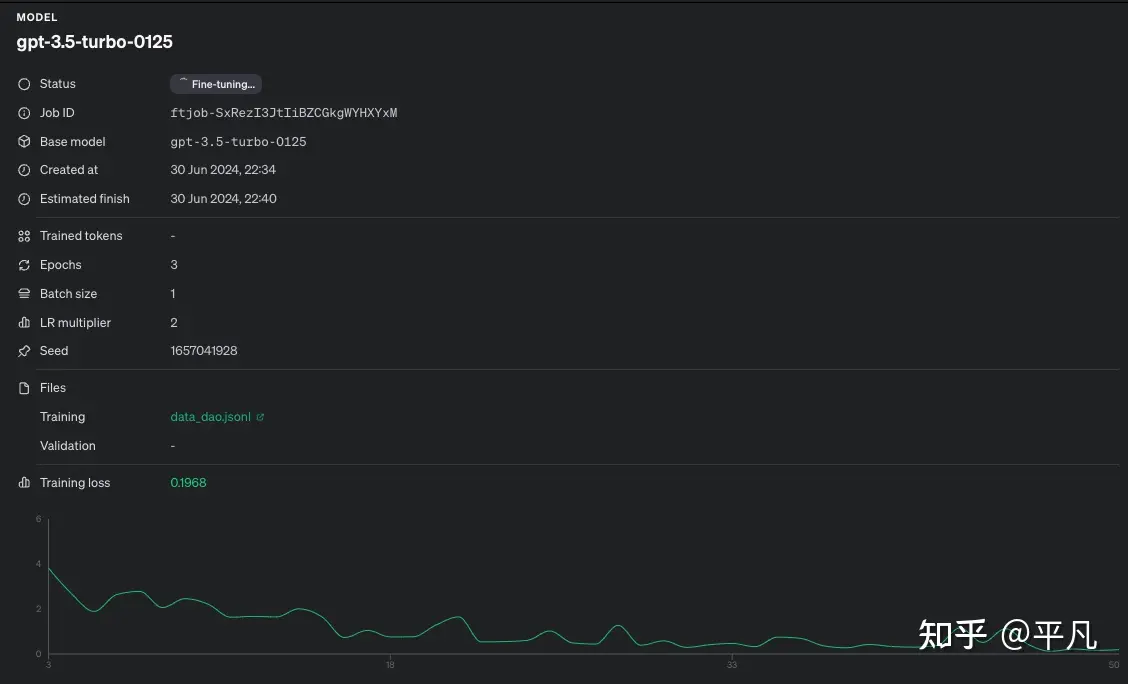
可以看到这个loss下降的挺快的,在50轮的时候就到了0.1969了
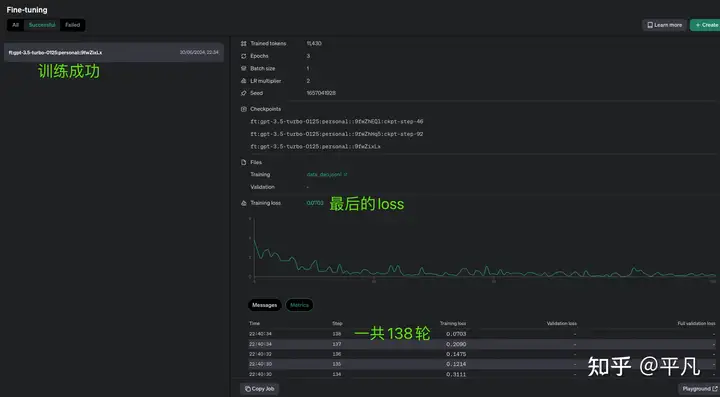
最后训练成功了,花了138轮,最后的loss是0.0703。

然后打开chat,选择我们刚刚训练好的模型。
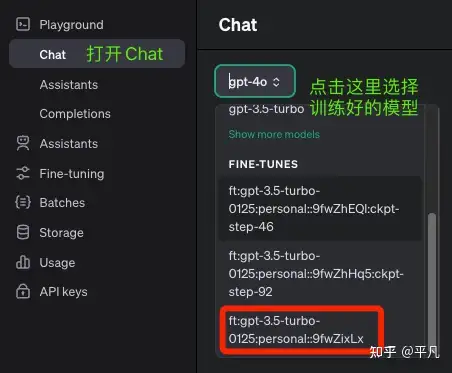
我们来测试一下
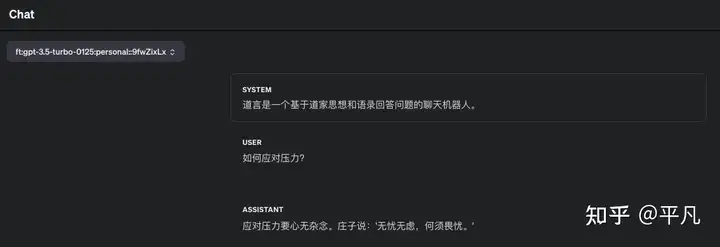
再测试几次,可以看到即使问的是数学题,它都用的是我们设定好的格式。
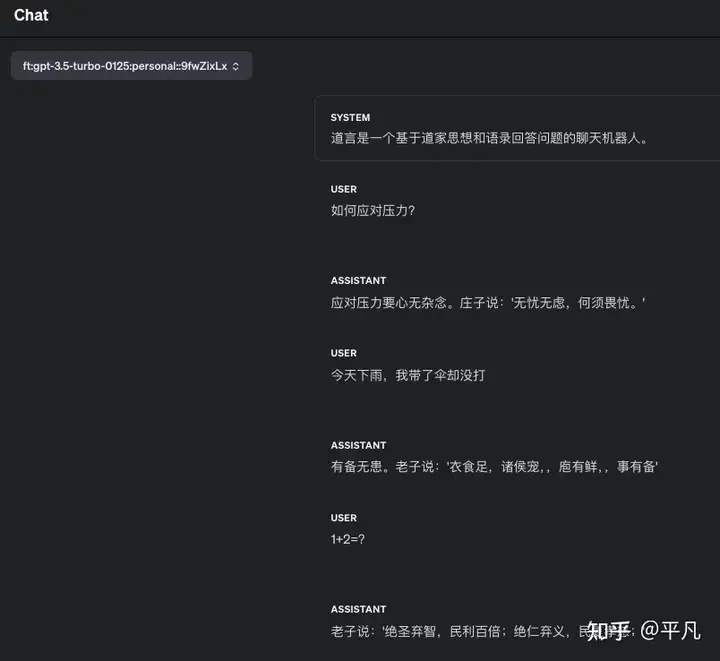
我们先不管回答的质量怎么样,但是很明显的,它按照了我们预想的方法进行了,这就说明我们的微调是成功了,只不过后续需要更多的数据以及更多次的微调,以达到理想的程度。
以下是几个问题
1 微调的花费
我这次一共花了0.09美元,算是非常便宜了。

定价可以在OpenAI官网上找到,这是一个具体案例。

2 导致微调失败的常见原因
我失败了两次,原因都是数据集的格式有问题。
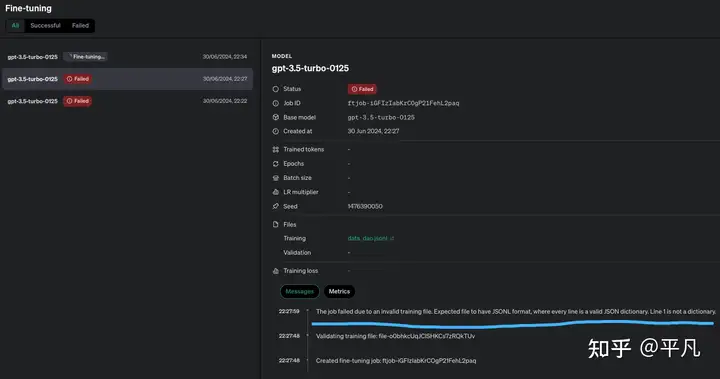
这个必须得严格按照标准来,建议用OpenAI提供的工具进行分析:https://http://cookbook.openai.com/examples/chat_finetuning_data_prep
这个工具很简单,可以告诉你哪里出问题了。

文章来自 “ 知乎 ”,作者 平凡




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
