# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
昨天,为大家介绍了生成式对抗网络GAN,今天再来为大家介绍另一个有趣的模型:扩散模型,包括Stability AI、OpenAI、Google Brain在内的多个研究团队基于扩散模型提出了多种创新模型,如以文生图、图像生成视频生成等~

扩散模型(Diffusion Models)是一种新型的生成模型,其灵感来源于非平衡热力学中的扩散过程。这种模型通过模拟从数据集中逐步添加噪声的过程,直至数据完全转化为噪声,然后再通过逆向过程从噪声中恢复出原始数据。
扩散模型的起源可以追溯到2015年,当时有研究者提出了深度生成模型(Deep Generative Models),这为后来的扩散模型奠定了基础。2018年,Diffusion Models被正式提出,它通过学习数据分布的逆过程,实现了更加稳定、多样化的样本生成。
扩散模型的技术发展经历了几个重要的阶段。最初,扩散模型被用于图像生成任务,并在这一领域超越了原有的生成对抗网络(GAN)成为新的SOTA(State of the Art)。随后,扩散模型的应用领域逐渐扩展到自然语言处理、波形信号处理等多个领域。以下是扩散模型技术发展的几个关键节点:
扩散模型的核心思想是模拟数据从有序状态向无序状态的扩散过程,以及相反的从无序状态恢复到有序状态的逆扩散过程。这两个过程共同构成了扩散模型的完整生命周期。
在前向扩散过程中,模型逐步向数据中引入噪声,直至数据完全转化为噪声。这个过程可以看作是一个马尔可夫链,其中每个状态只依赖于前一个状态。具体来说,模型通过以下步骤实现数据的逐步噪声化:
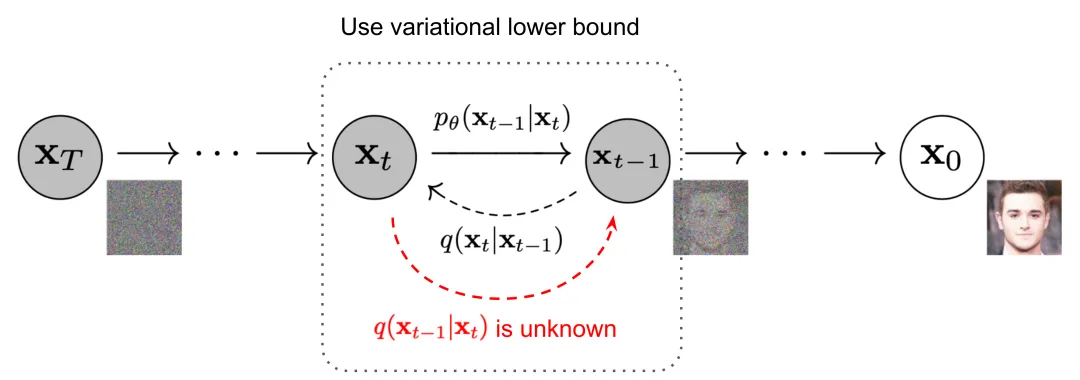
逆向扩散过程是前向扩散过程的逆操作,目标是从噪声状态恢复出原始数据。这个过程同样是一个参数化的马尔可夫链,通过以下步骤实现数据的逐步去噪:
扩散模型的训练目标是使神经网络能够准确预测在前向扩散过程中添加的噪声。这通常通过最小化预测噪声和实际噪声之间的差异来实现。一旦模型训练完成,就可以通过逆向扩散过程从纯噪声中生成新的数据样本。
总结来说,扩散模型通过模拟数据的扩散和逆扩散过程,实现了从简单分布到复杂数据分布的生成,这一过程不仅在理论上具有创新性,而且在实际应用中展现出了强大的生成能力。
Denoising Diffusion Probabilistic Models(DDPMs)是近年来在生成模型领域取得显著进展的一类模型。其基本原理是通过逐步添加噪声到数据中,形成一个正向扩散过程,然后学习如何从噪声中恢复出原始数据,即进行反向扩散。
Score-Based Generative Models(SGMs)是一种新兴的生成模型,主要通过学习数据分布的得分函数(score function)来实现样本生成。这种方法不直接建模数据的概率分布,而是通过对数概率密度函数的梯度进行建模。
DALL·E是OpenAI开发的一种基于扩散模型的图像生成系统,能够根据文本描述生成高质量的图像。自2021年首次发布以来,DALL·E系列不断迭代,最新版本DALL·E 3于2023年推出。
Imagen是Google DeepMind推出的一款高质量文本到图像生成模型,旨在生成与用户提示紧密对齐的图像。Imagen 2于2023年发布,进一步提升了生成图像的质量和准确性。
Stable Diffusion是由Stability AI开发的一款开源图像生成模型,广泛应用于艺术创作和商业项目。自2022年发布以来,Stable Diffusion迅速获得了用户的青睐。
扩散模型在生成图像、文本和其他数据类型方面展现出了巨大的潜力。根据最新的研究进展,扩散模型能够生成高度逼真、细节丰富的图像,这在图像生成任务中表现得尤为出色。例如,在图像合成方面,扩散模型通过逐步去噪的方式生成数据,能够产生质量较高且逼真的样本,这一点在多个数据集上的FID(Frechet Inception Distance)分数得到了体现,FID分数越低表示生成图像与真实图像的相似度越高。
扩散模型的另一个显著优势是其灵活性。研究显示,扩散模型可以灵活地调整生成过程中的参数,例如噪声强度、采样步数等,从而控制生成样本的多样性和风格,满足不同用户的需求。这种灵活性使得扩散模型能够适应多变的应用场景,如艺术创作、数据增强等。
相比于其他生成模型如生成对抗网络(GANs),扩散模型的训练通常更为稳定。扩散模型直接使用均方误差(MSE)等损失函数,直接衡量模型输出与真实数据之间的差异,而无需依赖一个网络进行对抗训练,降低了训练的不稳定性和复杂性。这一点在多个研究中得到了证实,扩散模型在训练过程中出现的模式崩溃现象较少,生成结果的一致性和可靠性更高。
扩散模型的理论基础源于坚实的数学基础,包括非平衡热力学和随机过程理论。这一理论框架有助于深入理解和分析模型的行为和性能,为模型的改进和优化提供了理论指导。例如,扩散模型中的Denoising Diffusion Probabilistic Models (DDPMs) 和 Score-Based Generative Models (SGMs) 都是基于随机微分方程(SDEs)构建的,这些模型的数学性质为理解和改进模型提供了坚实的基础。
扩散模型可以相对容易地扩展到不同的数据类型和领域,如从图像生成扩展到文本生成、语音合成等,具有广泛的应用前景。这种可扩展性使得扩散模型能够适应多种数据模态和应用需求,从而在多个领域中发挥作用。例如,扩散模型已经被应用于自然语言处理、生物信息学和金融数据生成等领域,显示出其强大的泛化能力。
扩散模型在生成高质量数据样本方面虽然表现出色,但其背后的计算成本不容忽视。由于扩散模型需要执行大量的迭代步骤来逐步生成图像或数据,这导致了相对较高的计算成本。研究表明,扩散模型的采样步骤通常需要上千次迭代,每次迭代都需要模型进行前向计算,这在资源消耗上是相当可观的。例如,在ImageNet数据集上的实验中,扩散模型的单次生成可能需要数小时到数天的时间,这取决于模型的复杂度和硬件配置。此外,扩散模型在训练过程中需要存储和处理大量的中间数据,这也增加了计算成本。
扩散模型的参数量通常较大,这导致了对显存的高需求。在高分辨率图像生成任务中,显存的需求尤为突出。例如,一些最新的扩散模型在处理1024x1024分辨率的图像时,可能需要超过24GB的显存。这对于大多数个人用户和小型实验室来说是一个不小的挑战,因为他们可能没有足够的硬件资源来支持这样的模型训练和推理。显存的限制也意味着在实际应用中,扩散模型可能需要在更强大的硬件上运行,这无疑增加了部署成本。
尽管扩散模型能够生成高质量的数据样本,但其采样速度慢是一个显著的劣势。如前所述,扩散模型通常需要上千个步骤来生成一个样本,这使得实时生成或快速迭代变得困难。在实际应用中,如在线内容生成或交互式应用,慢速采样可能成为用户体验的瓶颈。例如,一些商业应用可能需要在几秒钟内生成图像,而扩散模型的慢速采样无法满足这样的需求。
一些扩散模型可能缺乏编码能力,这意味着它们无法直接对隐空间进行编辑和操作。这在某些需要对生成内容进行精细控制和修改的任务中可能会受到限制。例如,在图像编辑应用中,用户可能希望在生成的图像中添加或删除特定的元素,而缺乏编码能力的扩散模型难以实现这样的操作。
扩散模型的训练过程相对复杂,涉及到大量的超参数调整和优化策略的选择。由于扩散模型的训练过程涉及到多个阶段,包括前向扩散和反向去噪,因此需要仔细地调整和优化超参数,如噪声水平、采样步数等。这些超参数的选择对模型的性能有着直接的影响,而找到最佳的超参数组合往往需要大量的实验和调整。此外,扩散模型的训练通常需要大量的数据和计算资源,这增加了训练的难度和成本。
为了解决扩散模型采样速度慢的问题,未来的研究可以集中在开发更高效的采样方法上。以下是一些可能的研究方向:
- 优化时间步长:通过设计优化问题来寻找特定数值ODE求解器在扩散模型中更合适的时间步长,减少采样步骤同时保持生成质量。实验表明,与均匀时间步长相比,优化时间步长可以显著提高图像生成性能。
- 并行化采样:利用多个GPU之间的并行性,将模型输入分成多个patch,每个分配给一个GPU处理,通过位移patch并行性减少通信开销,实现加速。
- 改进的扩散过程:探索非马尔可夫过程,允许每一步依赖更多以往的样本来进行预测新样本,以较大的步长做出准确的预测,从而加快采样过程。
- 部分采样:在generation process中忽略一部分的时间节点,只使用剩下的时间节点来生成样本,直接减少采样时间。
扩散模型在最大似然估计的表现不如基于似然函数的生成模型,未来的研究可以集中在如何提高扩散模型的似然估计能力:
- 损失函数设计:通过设计损失函数的权重函数,使得plug-in reverse SDE生成样本的似然函数值小于等于损失函数值,即损失函数是似然函数的上界。
- 噪声进度优化:通过设计或学习前向过程的噪声进度来增大变分下界(VLB),从而提高似然估计。
- 学习反向方差:学习反向过程的方差,减少拟合误差,有效地最大化VLB。
扩散模型在泛化到各种数据类型的能力上存在局限,未来的研究可以探索如何增强模型的数据泛化能力:
- 特征空间统一:将数据转化到统一形式的latent space,然后在latent space上进行扩散,使得扩散模型能够处理非连续性数据。
- 数据依赖的转换核:根据数据类型的特点设计diffusion process中的transition kernels,使扩散模型可以直接应用于特定的数据类型。
- 跨模态数据融合:探索多模态数据源的融合,提高扩散模型在处理多模态时间序列和时空数据时的预测性能和上下文理解能力。
- 结合大模型:结合大型语言模型(LLMs)与扩散模型,利用LLMs的自然语言理解能力增强时间推理,并为复杂系统提供更全面的视图。
文章来自微信公众号“智驻未来”,作者“小智”



