# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当下的手机及AIPC中都会安装本地大模型,然而上下文长度增加,推理时的计算成本也会显著增长。最明显的一个后果就是,用户输入问题后需要等待很久才能看到结果。
为此,已有多种优化方案提出,例如Flash Attention,而11月26日英伟达提出的Star Attention机制,可用于提升Transformer模型在处理长序列时的效率和准确性。
值得一提的是,这篇文章受到了广泛的关注,登顶Hugging Face每日论文榜首。

论文地址:https://arxiv.org/abs/2411.17116
在了解Star Attention如何改进大模型推理前,让我们先看看当前大模型的推理过程涉及的两个步骤:
1)prompt编码,即模型处理输入并在缓存中存储KV(键值)向量;
2)token生成,即模型关注KV缓存并自回归生成新令牌,同时用新 的KV向量更新缓存。
在许多长上下文任务中,输入由一个长上下文后跟一个短查询和一个短答案组成。当大模型的上下文变得越来越长之后,回答查询所需的信息通常局限在上下文的小部分内,意味着上下文只需关注附近的token,而查询token需要关注所有之前上下文涉及的内容。
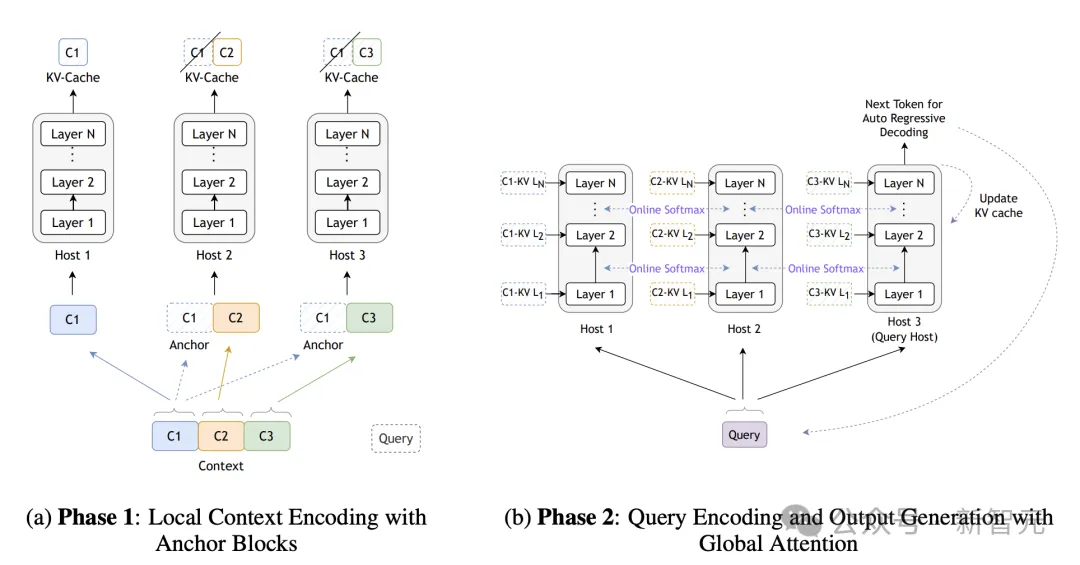
Star Attention下的两阶段推理
系统中所有设备被分组为多个主机(host),其中一个主机被标记 为「查询」主机。输入序列分为两个阶段处理。
阶段一:上下文编码
输入的上下文部分被分割成较小的块,并分配到各个主机。除了第一个块之外,所有块的前面都加上一个初始块,称为「锚点」块(anchor block)。每个主机处理其分配的块,并存储非锚点部分的KV缓存。
阶段二:查询编码和token生成
输入查询被广播到所有主机,在每个主机中,它首先访问在第一阶段计算出的本地KV缓存。然后「查询」主机通过聚合所有主机的softmax归一化统计数据来计算全局注意力。这个过程对于每个生成的token都会重复。
用一个不那么严谨的例子来概述上面的过程:想象一场烹饪比赛(上下文token),每个厨师(主机)负责准备一道菜的一部分(块)。
为了确保味道一致,每个厨师除了准备自己的部分,还在前面加了一点「锚点」调料(锚点块)。每个厨师准备好自己的部分后,记住自己部分的口味(KV缓存)。
阶段二的查询编码和token生成可视为:评委(查询token)来品尝菜肴,并决定下一道菜的口味(生成新token)。评委先品尝每个厨师的部分,看看哪个部分最符合他们的口味。
最后,评委汇总所有厨师的意见,确定下一道菜的口味,并告诉厨师们。
Star Attention带来的性能提升,主要体现在以下两个方面:
1)高达11倍的加速
在多个长上下文基准测试上,Star Attention所加持的8B Llama3的推理速度显著提升,随着序列长度增加,加速比从1.1x提升到2.7x。
而在参数量更大的Llama3.1-70B上,推理的加速比提升更为显著。

与此同时,对比采用全局注意力的基准,Star Attention相对准确率的降低只在0~3%范围内。
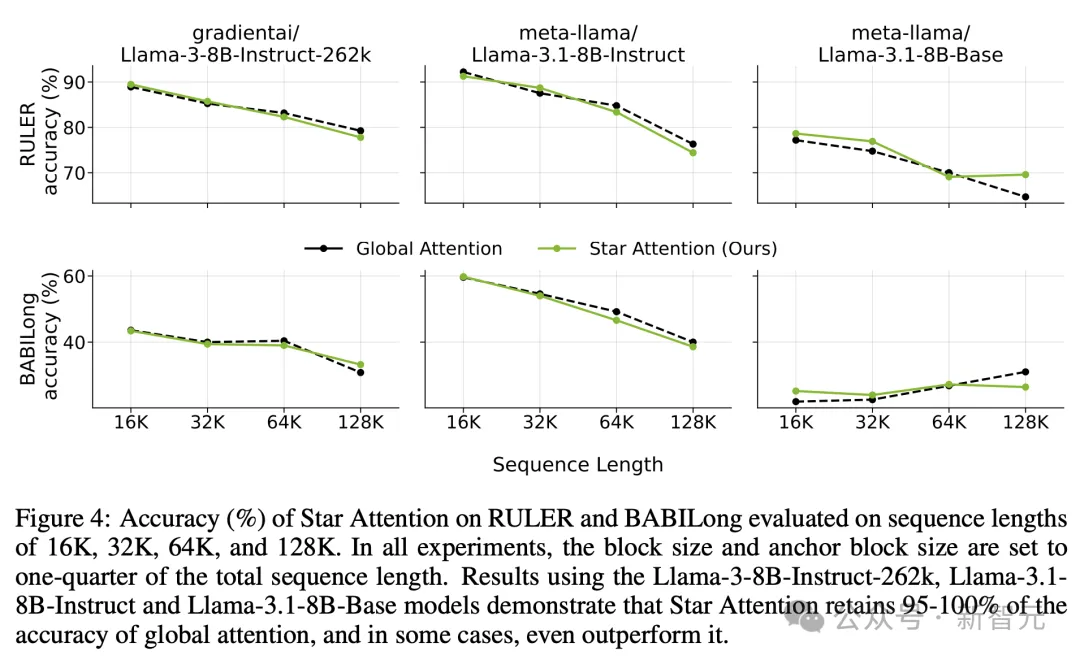
随着上下文长度的增加,star attention推理的准确性相比全局注意力几乎相同,但推理计算成本显著下降
在更长的上下文尺度(128K)中,上下文编码过程中不同块的大小,也会影响推理的准确性和速度。块尺寸越大,Star Attention 的准确性越高。
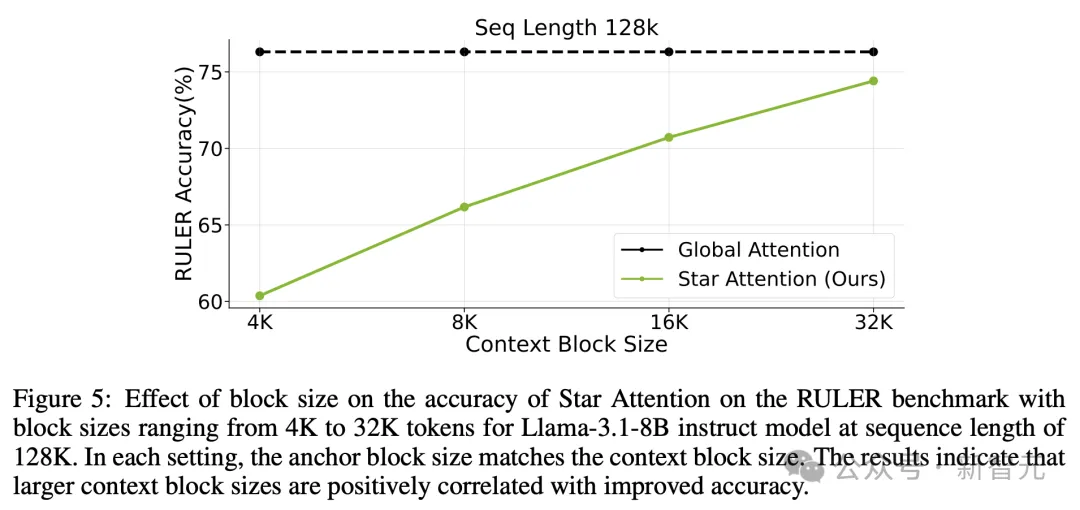
在 RULER 基准测试上,不同块大小对Star Attention准确性的影响,块大小范围从4K到32K,适用于序列长度为128K的Llama-3.1-8B instruct 模型
用于评估的RULER,包含了13个任务,分为4个领域:大海捞针 (检索)、多跳追踪、聚合和问答,

不同任务中,全局注意力和Star Attention的准确性差异对比
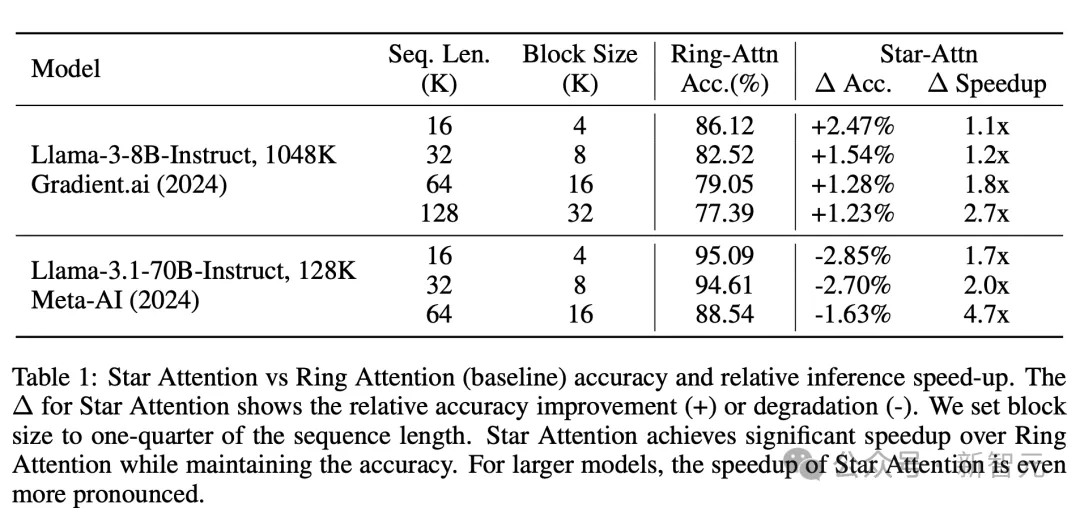
而在上下文长度更大,达到1048K时,Star Attention的推理准确性依旧保持在原基准90%,推理加速比达到了10.8×~16.9×。
而在更大的Llama3.1-70B中,Star Attention能实现更大的加速比,同时保持相似水平的准确率下降。
由于其运行机制不涉及具体模型,Star Attention可以无缝集成到大多数通过全局注意力训练的基于Transformer的LLMs中,无需额外的模型微调。
由于减少了推理的计算成本,Star Attention显著减少了内存需求,使得在本地设备(如手机,笔记本中)用LLM处理更长的序列成为可能。
实验发现,将块大小设置为总序列长度的约四分之一,可以在精度和速度之间取得最佳平衡。而用户也可以根据需求调整块大小,以在计算效率和精度之间进行权衡。
未来的研究,会尝试将Star Attention扩展到更长的序列(最长可达1M)和更大的模型,并希望能观察到甚至更的加速,同时保持相似水平的准确率。同时专注于优化「锚块」机制,并在更复杂的长上下文任务上提高性能,以增强Star Attention的可扩展性和稳健性。
总的来看,对于想要开发部署本地大模型的厂商,Star Attention是一项不容错过的技术。使用Star Attention后,本地LLM能够更快地回复用户,还可在有限的内存中兼容更长的上下文序列,从而在RAG任务中阅读更长的文本。
而对于云端大模型的提供商,Star Attention能够在几乎不影响用户体现的前提下,显著提升推理成本,实现「降本增效」,同时减少能源消费(碳足迹)。
通过在多个主机间分配上下文处理,Star Attention使上下文长度能够随主机数量线性扩展。
参考资料:
https://arxiv.org/abs/2411.17116
文章来自微信公众号“新智元”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
