# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
别说什么“没数据就去标注啊,没钱标注就别做大模型啊”这种风凉话,有些人数据不足也能做大模型,是因为有野心,就能想出来稀缺数据场景下的大模型解决方案,或者整理出本文将要介绍的 "Practical Guide to Fine-tuning with Limited Data" 这样的综述。
而有些人,像我,是因为老板想做大模型。
但是训练数据显然是不够的,我们行业主要是因为标注专业性太强,原始数据也本来就少,巧妇难为无米之炊,变不出很多的数据来。但是大模型是一定要做的,每个大点的公司都有老板想要一个大模型,君要臣做大模型,臣不得不做大模型。
所以我就去读了这篇文章,主要就是解决微调大模型时训练数据不足问题。
论文标题:
A Practical Guide to Fine-tuning with Limited Data
论文链接:
https://arxiv.org/pdf/2411.09539

作者来自德国和英国,作者全是典型德裔,一作和二作是慕尼黑工业大学医学人工智能方向的,所以可能他们做这篇工作本来是关注小语种 + 医学 +AI 方向的解决思路。
我不是做医学的,不过我们行业的专业性也很强,所以完全可供参考。
除了专业性导致训练数据匮乏之外,小语种也可能导致数据匮乏。我目前倒是不需要解决语言方面的问题,只管中文就行,但是以后万一我们的大模型需要对接小语种客户怎么办呢?所以对于小语种方面我也可以关注关注。
现在大模型应用的范式一般是“预训练-微调-推理(提示学习)”,大模型在海量数据上进行预训练学习到通用知识,通过微调、few-shot 学习等方式将大模型的能力迁移到特定任务领域,这就是迁移学习。
预训练阶段需要海量数据,微调阶段一般也需要足量的数据,否则可能会出现过拟合、泛化能力差和性能不佳等问题。
本文按照预训练、微调、few-shot 学习三个阶段,总结的全部方法如图所示:
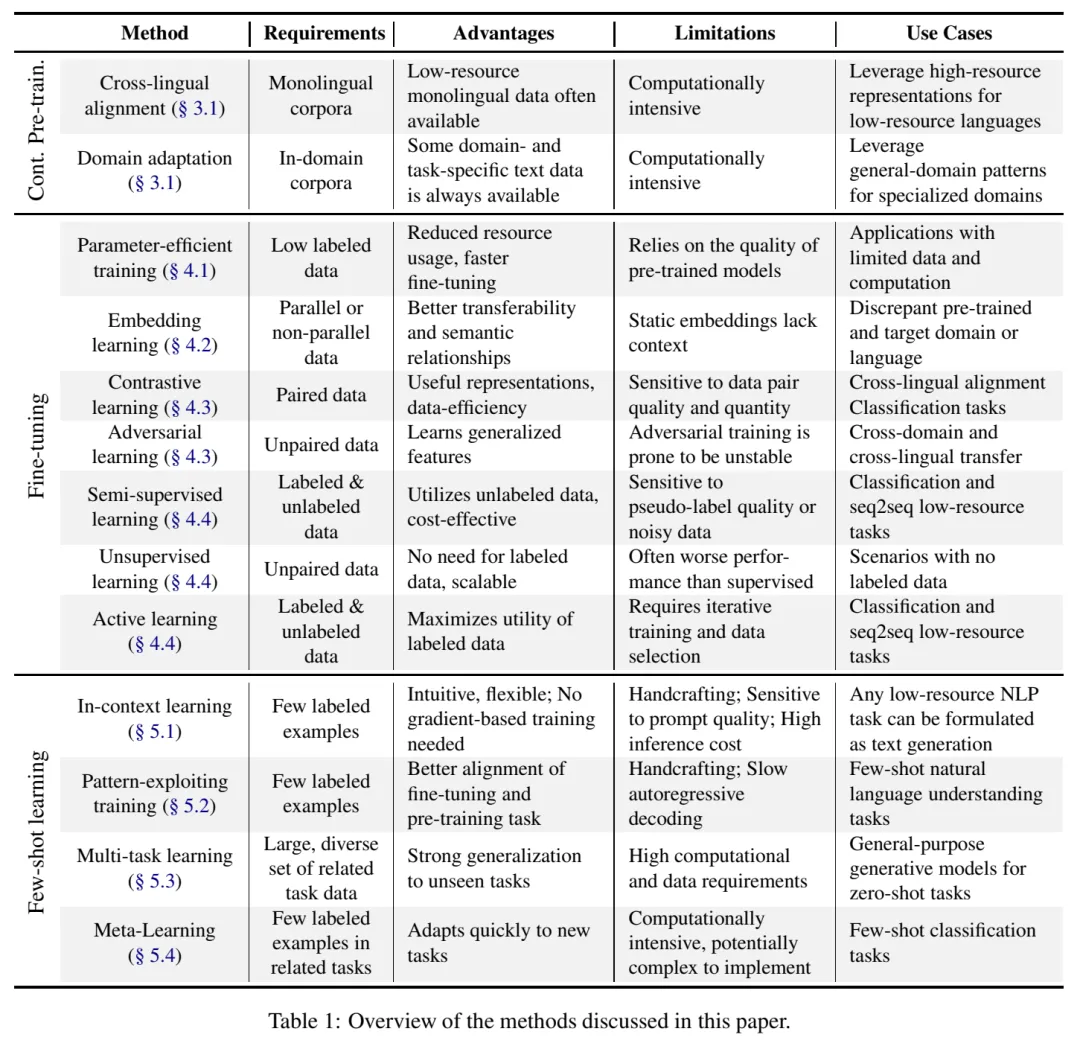
以下我会对文中提及的方法做简单介绍,感兴趣的读者可以去详细阅读论文,或者评论私聊与我讨论。
包括最初的预训练和继续预训练阶段,主要是拿来看的,毕竟这种方案适合有条件的大户人家,从预训练开始做大模型那种。也可以拿来作为选大模型基底的标准,就是说如果没做这些事的大模型就不行,不用选了……
这块方法主要缺点就是计算量大,毕竟要把方法融进复杂的预训练之中:
对比学习和对抗学习就是不需要手工标注很复杂的标签,但是需要设计好适当且合理的学习目标。感觉还是要看具体的数据情况,要讲个有道理的故事。
Few-shot 学习就是仅给出特定领域的少量样本,就让模型学到该领域的知识,做出正确的回答。
这块是总结了各种论文的解决方案,以供参考。不过感觉这块其实是纯纯经验之谈,还是得具体问题具体分析:

图中的缩写是:
最重要的似乎还是选择合适的预训练模型,对于低资源语言或专业领域建议使用较大规模、预训练策略丰富(使用了 cross-lingual alignment 和 domain adaptation)的模型。
(感觉这属于正确的废话,大家都知道大模型只要够好,什么提示模版都不用硬上,只要随便问问,大模型自己就能输出很不错的回答。)
在极低资源场景下,建议先考虑上下文学习,又快又不用训练,表现也可以。如果需要微调,优先考虑 PEFT 方法中的 adapter 和 prefix-tuning 方法。
其他方法也可以用于增强模型表现能力。
如果能弄到更多数据就去弄,能从根本上解决数据不足的问题。
实在是没数据,首先找最厉害的模型基底,先用提示学习(包括 ICL 和 PET)的方式测试模型效果,然后尝试部分微调(如 adapter 和 prefix-tuning),其它方法也可以增强模型效果。具体的方法可以在本文中找参考文献。
以后可能会分享一下我在数据永远不够条件下做大模型的实践思路和工作成效,以本文作为初步调研结果。
文章来自于“夕小瑶科技说”,作者“不如水”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
