# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型(LLMs)在推理任务上展现出了令人瞩目的能力,但其推理思维方式的单一性一直是制约性能提升的关键瓶颈。目前的研究主要关注如何通过思维链(Chain-of-Thought)等方法来提升推理的质量,却忽视了一个重要维度——推理类型的多样性。
1.思维多样性不足
2.推理策略单一
3.现有增强方法的不足
卡内基梅隆大学和通义千问团队的研究者们提出了一个发人深省的问题:为什么不让 AI 像人类一样,根据问题特点灵活运用不同的推理方式?这一思路催生了 TypedThinker 框架,为大模型注入了多维度的思维能力。

图片由修猫创作

1.认知科学启发
2.技术可行性
3.应用需求
研究团队在四个基准数据集(LogiQA、BBH、GSM8k 和 MATH)上的分析示了一个重要发现:不同类型的推理各有所长,能解决不同类型的问题。
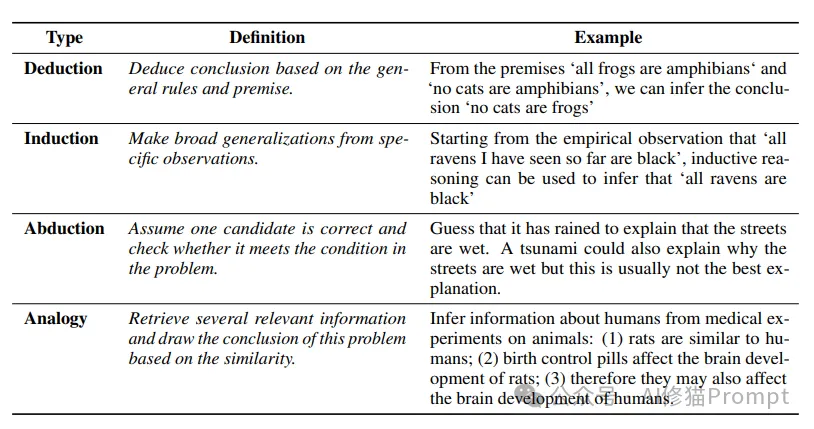
1.演绎推理(Deductive)
前提1:所有程序员都懂编程
前提2:小明是程序员
结论:小明懂编程
2.归纳推理(Inductive)
观察1:1+3=4
观察2:2+3=5
观察3:4+3=7
规律:任意数加3,结果比原数大3
3.溯因推理(Abductive)
现象:地面是湿的
可能原因1:下雨了(最可能)
可能原因2:有人浇水
可能原因3:水管破裂
4.类比推理(Analogical)
已知:太阳系中地球绕太阳运转
类比:其他行星也可能绕太阳运转
验证:观察证实推测正确
研究团队通过大规模实验证明了推理类型的重要性:
1.数据规模
2.实验设置
3.关键发现
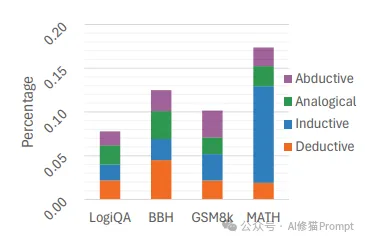
不同推理类型的优势互补
TypedThinker 框架包含三个核心组件,每个组件都经过精心设计以实现特定功能:
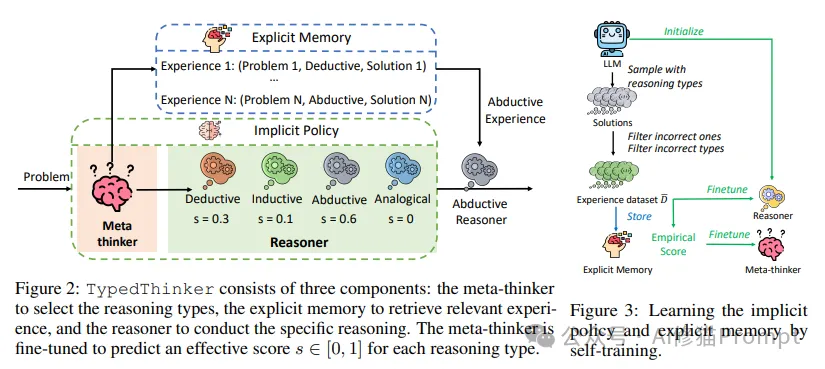
1.元思考者(Meta-thinker)
2.显式记忆库(Explicit Memory)
3.推理器(Reasoner)
TypedThinker 的完整工作流程包含以下步骤:
1.问题分析
2.推理类型选择
3.经验检索
4.推理执行
5.结果处理
TypedThinker 采用创新的自训练方式来持续优化性能:
1.数据收集
2.效果评估
3.模型优化
4.质量控制
5.持续改进
1.数据集
2.基线模型
3.评估指标
在四个基准数据集上的详细实验结果:
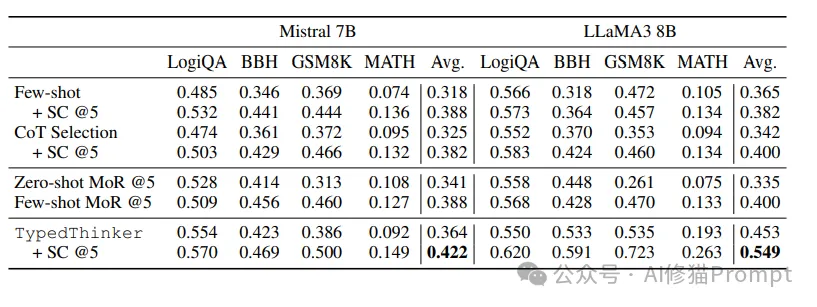
1.Mistral 7B
2.LLaMA3 8B
3.泛化性验证
4.GPT-4提升效果
1.推理类型的重要性
a. 独特优势
b. 互补性
c. 适应性
2.元思考者的效果
a. 预测准确性
b. 泛化能力
c. 决策可靠性
3.记忆库的作用
a. 逻辑推理
b. 数学问题
c. 经验积累
1.逻辑推理案例
问题:越往高处走,气压越小。因为兰州的海拔比天津高,所以兰州的气压比天津低。
下列哪种推理最相似?
选项:
A. 市场竞争越激烈,产品质量和广告投入越大,产品销量就越大。A公司比B公司投入更多广告费用,
所以A公司的产品销量比B公司大。
B. 人越老越成熟。老张比他儿子大,所以老张比他儿子成熟。
C. 树越老年轮越多。老张家院子里的洋槐树比老李家的年龄大,所以老张家的洋槐树比老李家的年轮多。
D. 一种语言的词汇量越大,学习起来越困难。英语比意大利语难学,所以英语的词汇量比意大利语大。
分析过程:
1. 元思考者分析
- 归纳推理得分:0.5
- 演绎推理得分:0.4
- 类比推理得分:0.4
- 溯因推理得分:0.4
2. 推理执行
使用归纳推理:
- 原问题揭示规律:高度↑ → 气压↓
- 应用规律:兰州高度>天津 → 兰州气压<天津
- 对比选项寻找相似规律:
A:广告投入与销量关系不完整
B:年龄与成熟度关系可能不成立
C:树龄与年轮数量存在必然关系
D:难度与词汇量关系反向推导
3. 结论
选择C,因为树龄与年轮数量的关系最符合原问题中高度与气压的关系特征。
2.数学问题案例
问题:一个正整数m在30到80之间,是6的倍数。当m除以8时余2,
除以5时也余2。求m的值。
分析过程:
1. 元思考者分析
- 溯因推理得分:0.6
- 演绎推理得分:0.3
- 归纳推理得分:0.2
- 类比推理得分:0.1
2. 推理执行
使用溯因推理:
a) 列出可能的m值
- 6的倍数:36、42、48、54、60、66、72、78
b) 验证除以8的余数
- 36÷8=4余4
- 42÷8=5余2 √
- 48÷8=6余0
- ...
c) 对42验证除以5的余数
- 42÷5=8余2 √
3. 结论
m=42满足所有条件
对于 Prompt 工程师,TypedThinker 的研究可以在写prompt时注意以下要点:
1.问题分析
2.选择策略
3.注意事项
1.基础模板
使用[推理类型]来解决问题。
[推理类型]的定义是:[定义]。
示例:[相关案例]
现在请解决:[问题描述]
2.推理类型定义
演绎推理:从一般规则推导出具体结论
归纳推理:从具体观察总结出普遍规律
溯因推理:通过验证假设来寻找最佳解释
类比推理:基于相似性进行推理
3.示例要求
1.简单问题处理
2.复杂问题处理
3.效果优化
1.复杂问题的处理
2.推理类型的选择
3.记忆库的使用
1.技术层面
2.应用层面
3.理论层面
TypedThinker 框架通过引入多维度的推理类型,并结合元思考者和记忆库的创新设计,该框架不仅显著提升了模型性能,也为我们理解和改进 AI 推理能力提供了新的视角。对于 Prompt 工程师而言,这项研究提供了实用的工具和方法,有助于设计更有效的提示策略。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
