# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
开发AI应用的朋友们都有深刻的感受,在实际应用开发中,如何让LLM高效地使用外部工具,一直是困扰Prompt工程师的一个关键问题。最近,来自Faculty Science Ltd的研究团队提出的Language Hooks框架,为这个问题提供了一个令人耳目一新的解决方案。


在深入探讨Language Hooks框架之前,我们需要先理解当前LLM工具使用方案的困境。作为一线Prompt工程师,我们每天都在与各种工具使用示例打交道。这些示例就像是Prompt中的"肿瘤",不断膨胀,却又无法切除。
您可能遇到过这样的场景:我们需要开发一个能够进行数学计算、知识检索和代码生成的AI助手。按照传统方案,我们需要在Prompt中塞入大量的工具使用示例:如何调用计算器、如何搜索信息、如何使用代码编辑器等。这些示例不仅占用了宝贵的上下文空间,还与具体任务紧密耦合。更糟糕的是,当我们需要支持新的工具时,这些示例会呈指数级增长。
另一种常见的方案是通过微调来让模型学会使用工具。这种方法虽然避免了在Prompt中塞入示例,但带来了新的问题:每次添加或修改工具能力,都需要重新训练模型。在快速迭代的项目中,这种方案的维护成本高得令人望而却步。
Language Hooks框架的核心思想可以用一句话概括:将工具使用能力从模型和提示中完全解耦出来。这种思路看似简单,实则蕴含深刻的洞见。
传统方案之所以陷入困境,根本原因在于它们都试图让模型"学会"使用工具。无论是通过示例展示还是通过微调注入,本质上都是在教模型"如何使用工具"。这种思路导致工具使用能力与模型或提示紧密耦合,难以扩展和维护。
Language Hooks框架则另辟蹊径:与其教模型使用工具,不如在模型生成过程中动态注入工具能力。这就像是给模型装上了一个个"钩子",可以在需要时自动触发相应的工具能力。这种设计带来了革命性的变化:
首先,工具使用不再依赖于任务相关的示例。同一个计算器钩子可以用于解决数学题,也可以用于财务分析,完全不需要在提示中说明如何使用。这释放了大量的提示空间,让我们能够专注于描述任务本身。
其次,工具能力与具体模型解耦。无论是GPT-3还是Claude,都可以使用相同的钩子系统。这不仅降低了维护成本,还提供了跨模型的复用能力。当我们需要切换到新的模型时,不需要重新设计工具使用方案。
最重要的是,这种设计实现了真正的模块化。每个钩子都是独立的功能单元,可以根据需要自由组合。添加新的工具能力就像插入新的钩子一样简单,不会影响现有功能。
Language Hooks框架的技术实现堪称优雅。它的核心是一个事件驱动的系统,由三个关键组件构成:程序(Program)、触发器(Trigger)和资格检查(Eligibility)。
程序组件负责执行具体的工具调用。以计算器钩子为例,它的程序组件会接收当前的生成上下文,提取其中的数学表达式,使用SymPy进行计算,然后将结果更新回上下文。这个过程完全透明,模型无需知道计算是如何完成的。
触发器组件则负责判断何时需要调用工具。它可以是一个简单的规则匹配器,也可以是一个复杂的文本分类器。关键是它的判断必须轻量级且可配置。研究团队在实验中发现,使用小型的辅助LLM作为触发器效果最好,既保证了准确性,又避免了过度消耗资源。
资格检查组件看似简单,实则至关重要。它的主要职责是防止钩子的无限递归和循环调用。例如,当计算器钩子修正了一个计算错误后,可能会触发新的计算需求。资格检查组件会根据执行历史和当前状态,决定是否允许新的调用。
这三个组件协同工作的方式非常巧妙。当模型生成文本时,系统会自动检查是否有钩子被触发。如果有,就按优先级执行相应的程序。程序执行完后,模型会基于更新后的上下文继续生成。整个过程就像是给模型装上了一个智能助手,在需要时自动提供帮助。
为了更直观地理解Language Hooks框架的工作原理,让我们通过一个具体的例子来说明。假设我们需要回答这样一个问题:"Taylor Swift的歌曲Love Story和Blank Space的发行时间相差多少年?"这个看似简单的问题实际上需要多个步骤来解决,很好地展示了框架的工作流程。
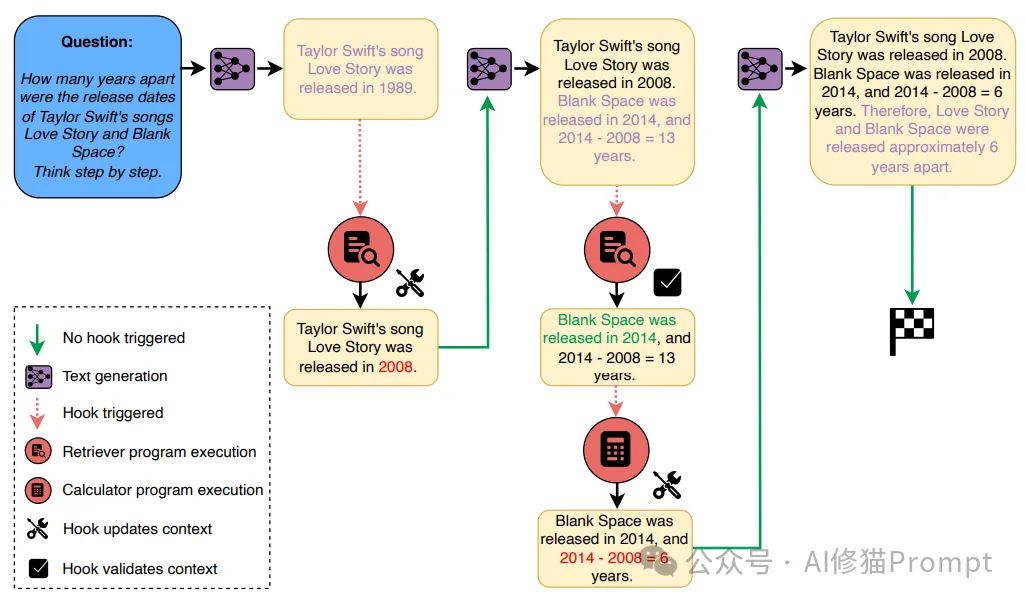
1.初始生成阶段
2.检索和修正
3.继续处理
4.计算和验证
这个例子展示了框架的几个关键特性:
通过这种方式,框架能够在保持对话自然流畅的同时,确保信息的准确性和推理的正确性。这种能力在处理需要多步验证和计算的复杂问题时尤为重要。
理论是美好的,但实践才是检验真理的唯一标准。研究团队在数学推理和多跳问答两类具有挑战性的任务上对Language Hooks框架进行了全面测试,结果令人瞩目。
在数学推理任务上,团队使用了三个测试集:GSM8K、GSM-HARD和GSM-HARD-filtered。实验结果显示:
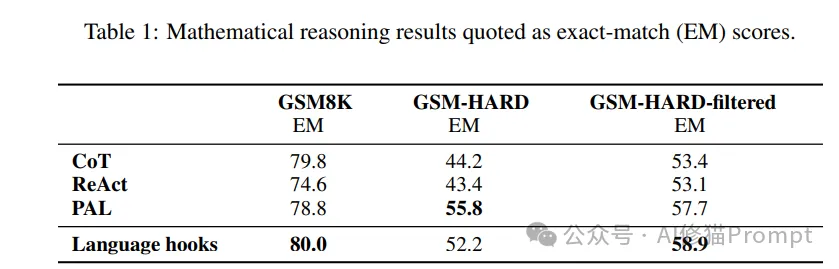
1.在GSM8K数据集上:
2.在更具挑战性的GSM-HARD数据集上:
3.在GSM-HARD-filtered数据集上:
这些结果表明,Language Hooks框架在数学推理任务上展现出了稳定且优秀的性能。特别是在基础数据集GSM8K上,它实现了所有方法中的最高准确率。即使在更具挑战性的变体数据集上,它也保持了很强的竞争力。
在多跳问答任务上,研究团队使用了HotPotQA和2WikiMultiHopQA两个数据集,分别从精确匹配(EM)和F1分数两个维度进行评估:
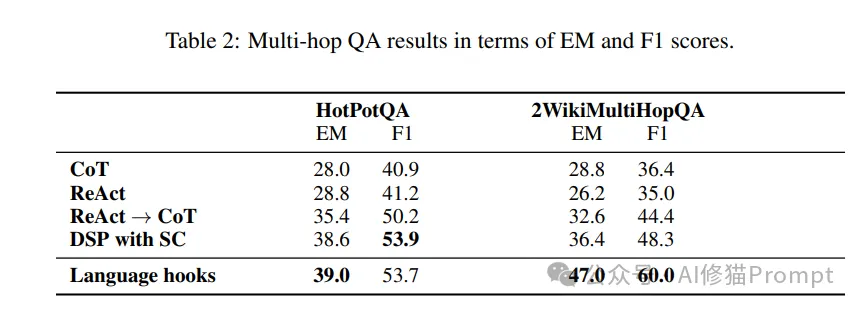
1.HotPotQA数据集:
2.2WikiMultiHopQA数据集:
这些结果特别值得关注,因为它们展示了Language Hooks框架在处理复杂推理任务时的优势。在2WikiMultiHopQA上,框架的表现尤其出色,F1分数达到60.0%,远超其他方法。这说明框架不仅能够准确找到答案(体现在较高的EM分数),还能更全面地理解和处理问题(体现在更高的F1分数)。
这些实验结果的重要性不仅在于数字的提升,更在于它们揭示了框架的几个关键优势:
1.稳定性:在不同类型的任务和数据集上都能保持优秀的表现。
2.可靠性:特别是在处理复杂问题时,框架展现出了更强的推理能力和更高的准确性。
3.通用性:无论是数学计算还是知识检索,框架都能有效处理,证明了其设计的灵活性。
这些结果充分证明了Language Hooks框架的实用价值,也为未来的改进和应用指明了方向。
理解了框架的整体设计后,让我们通过三个具体案例来深入探讨其工程实践。这些案例不仅展示了框架的实用性,更为Prompt工程师提供了宝贵的实现参考。
计算器钩子看似简单,实则暗藏玄机。它的核心任务是确保模型的数学计算准确无误,但实现这个目标并不容易。首先,它需要准确识别文本中的计算表达式。研究团队采用了一个巧妙的方案:使用轻量级的辅助LLM来提取表达式。这个LLM经过特殊训练,专门用于识别数学表达式,既保证了准确性,又避免了性能开销。
提取到表达式后,钩子使用SymPy进行验证和计算。但关键不在于计算本身,而在于如何处理计算结果。如果发现错误,钩子不能简单地替换结果,还需要考虑上下文的连贯性。例如,如果模型基于错误的计算继续推理,这些推理也需要被适当处理。研究团队的解决方案是:一旦发现计算错误,就截断后续推理,让模型基于正确的结果重新生成。这种处理方式既保证了准确性,又维持了输出的自然流畅。
检索器钩子的实现体现了更深的技术洞见。它的核心挑战是:如何在保证知识准确性的同时不破坏模型的生成连贯性?研究团队采用了一个多阶段的方案:
第一步是查询生成。钩子不是简单地提取关键词,而是让模型生成多个相关但不同的查询。这种多样性策略大大提高了找到相关信息的概率。例如,对于"谁发明了相对论"这个问题,系统会生成"Einstein relativity theory"、"special relativity history"等多个查询。
然后是知识整合。获取到信息后,关键是如何将其自然地融入生成内容。团队开发了一个特殊的重写算法,它不是简单的拼接,而是考虑了上下文的连贯性。算法会分析当前生成的内容,找到合适的整合点,然后以自然的方式插入新知识。
最后是引用追踪。为了增加可信度,钩子会自动为使用的知识添加引用标记。这些标记不会干扰阅读流畅性,但提供了重要的溯源信息。
护栏钩子解决了一个棘手的问题:如何处理模型的过度保守行为?在实际应用中,模型经常会因为不确定性而拒绝回答有价值的问题。护栏钩子通过一个巧妙的机制来解决这个问题:
它首先会分析模型的拒绝回答是否真的必要。如果判断问题本身是安全的,钩子会添加一个特殊的引用前缀让模型以一种更开放的方式重新生成回答。这个过程中,钩子会确保生成内容符合安全标准,同时标记不确定性,让用户了解潜在风险。
这种设计既提高了模型的可用性,又不损害其安全性,是一个非常优雅的平衡方案。
Language Hooks框架的意义远不止于解决工具使用问题,它实际上开创了一种全新的Prompt工程范式。这种范式将给我们的工作带来深远影响。
首要的是开发思维的转变。传统的Prompt工程往往陷入"教会模型做什么"的思维定式。我们花费大量精力设计示例,试图让模型理解如何使用工具。Language Hooks框架提醒我们:也许我们不需要教模型使用工具,而是应该为模型提供一个支持工具使用的环境。这种思维转变将极大地简化我们的工作。
再次是效率的提升。在新范式下,我们可以把精力集中在业务逻辑本身,而不是工具使用的细节上。例如,在开发一个财务分析助手时,我们可以专注于设计分析流程,而不需要关心如何教模型使用计算器或数据库。这不仅提高了开发效率,更提升了系统的可维护性。
最重要的是可能性的扩展。通过钩子系统,我们可以为模型添加各种强大的能力,不受提示空间的限制。这为AI应用的创新打开了新的天地。例如,我们可以开发专门的钩子来处理图像生成、代码执行、数据可视化等复杂任务,大大扩展了应用的边界。
Language Hooks框架的出现,为困扰Prompt工程师的工具使用问题提供了一个优雅的解决方案。但它的意义不仅在于解决具体问题,更在于开创了一种新的开发范式。这种将工具使用与模型解耦的方法,必将重塑AI应用的开发方式。
对于每一位Prompt工程师来说,现在正是拥抱这一变革的最佳时机。通过理解和运用Language Hooks框架,我们可以构建出更强大、更灵活、更易维护的AI应用。这不仅能提升我们的工作效率,更能为用户创造更大的价值。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
