# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在当前大语言模型(LLM)的应用生态中,函数调用能力(Function Calling)已经成为一项不可或缺的核心能力。它使LLM能够通过调用外部API获取实时信息、操作第三方服务,从而将模型的语言理解能力转化为实际的行动能力。从电子设计自动化到金融报告生成,从旅行规划到智能家居控制,函数调用正在将LLM的应用版图快速扩展到各个领域。
然而,如何让LLM更准确地理解和使用函数接口,一直是困扰研究者和工程师的关键问题。MediaTek Research的研究团队最近在这一领域取得了重要突破,他们从提示格式优化、数据集成策略到多语言支持等多个维度,系统性地提升了LLM的函数调用能力。本文将详细解析他们的研究发现,为从事LLM应用开发的工程师提供切实可行的优化方案。

在这项研究中,研究者首先挑战了传统的函数描述方式。他们提出了两种不同的策略来在提示中展示函数描述:
这两种策略的实验结果令人深思。研究发现,当函数描述通过专门角色呈现时,模型在相关性检测(Relevance Detection)方面表现更好。这意味着模型能更准确地判断是否需要调用函数,从而减少不必要的函数调用。研究发现,使用专门角色策略时,相关性检测准确率达到49.58%,而系统角色集成策略则为39.58%。
研究者认为,这种差异源于模型能更清晰地识别出有函数可用和无函数可用的场景之间的区别。当函数描述被放在专门的角色中时,有函数和无函数的提示模板差异更明显,这帮助模型建立了更强的区分能力。
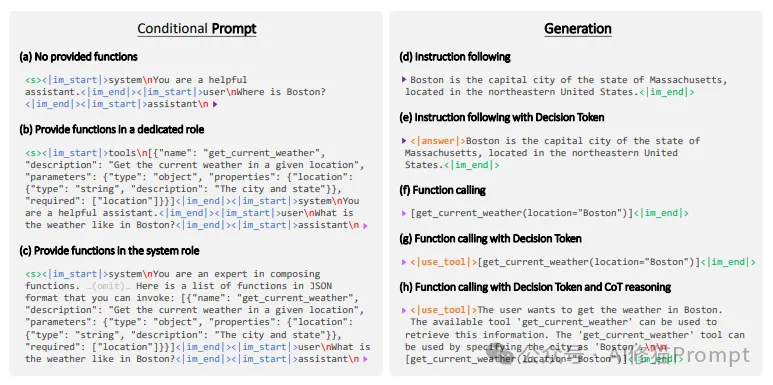
毫无疑问,精确推理时,Prompt格式显著影响推理的精准度。研究中探索了三种主要的提示格式:
1.无函数场景:
<|im_start|>system
You are a helpful assistant.
<|im_end|>
<|im_start|>user
Where is Boston?
<|im_end|>
<|im_start|>assistant
2.专门角色提供函数:
<|im_start|>tools
[{"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {"type": "object", "properties": {"location":
{"type": "string", "description": "The city and state"}},
"required": ["location"]}}]
<|im_end|>
<|im_start|>system
You are a helpful assistant.
<|im_end|>
<|im_start|>user
What is the weather like in Boston?
<|im_end|>
<|im_start|>assistant
3.系统角色集成函数:
<|im_start|>system
You are an expert in composing functions. Here is a list of functions in JSON format that you can invoke: [{"name": "get_current_weather", "description": "Get the current weather in a given location", "parameters": {"type": "object", "properties": {"location": {"type": "string", "description": "The city and state"}}, "required": ["location"]}}]
<|im_end|>
<|im_start|>user
What is the weather like in Boston?
<|im_end|>
<|im_start|>assistant
对应的生成结果示例:
1.普通回答:
Boston is the capital city of the state of Massachusetts, located in the northeastern United States.
<|im_end|>
2.带Decision Token的回答:
<|answer|>Boston is the capital city of the state of Massachusetts, located in the northeastern United States.
<|im_end|>
3.函数调用:
[get_current_weather(location="Boston")]
<|im_end|>
4.带Decision Token的函数调用:
<|use_tool|>[get_current_weather(location="Boston")]
<|im_end|>
5.带推理过程的函数调用:
<|use_tool|>The user wants to get the weather in Boston. The available tool 'get_current_weather' can be used to retrieve this information. The 'get_current_weather' tool can be used by specifying the city as 'Boston'.
[get_current_weather(location="Boston")]
<|im_end|>

研究中最令人惊讶的发现之一是指令跟随(Instruction Following)数据对函数调用能力的显著提升作用。研究者在训练数据中加入了11万条指令跟随数据,结果发现这不仅没有削弱模型的函数调用能力,反而带来了全面的性能提升:
这一发现颠覆了"专注于函数调用数据才能提升函数调用能力"的传统认知。研究者分析认为,指令跟随数据帮助模型建立了更好的语义理解能力,这种基础能力的提升反过来增强了模型理解和使用函数接口的能力。同时,指令数据中包含的大量非函数调用场景,也帮助模型更好地识别什么时候应该直接回答而不是调用函数。
为了进一步提升模型的相关性检测能力,研究者提出了一个创新的Decision Token机制。这一机制的核心思想是在生成响应之前,先让模型做出一个明确的二元决策:是直接回答还是调用函数。
具体实现上,研究者引入了两个特殊token:
这种设计将原本隐含在生成过程中的决策明确化,强制模型在生成具体回答或函数调用之前,先对查询的性质做出判断。实验结果表明,当结合合成的非函数调用数据使用时,这一机制能将相关性检测准确率提升到65.42%。
更重要的是,Decision Token机制还简化了非函数调用数据的生成过程。研究者可以通过移除原始数据中被调用的函数,轻松创建对应的函数调用训练样本。这解决了获取高质量非函数调用训练数据的难题。
在全球化背景下,如何让函数调用能力突破语言障碍是一个关键挑战。研究者设计了一个专门的翻译管道来解决这个问题。这个管道的独特之处在于它采用了细粒度的翻译策略:
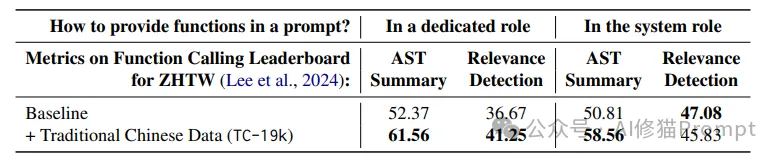
以中文为例,研究者使用这个管道生成了1.9万条中文函数调用数据。实验结果显示,即使只使用这些翻译数据进行微调,模型在中文(繁体)函数调用基准测试上的表现就有显著提升:
这一结果证明,只要采用合适的翻译策略,函数调用能力是可以有效地迁移到其他语言的。
研究团队开发的翻译pipeline采用了精细的处理策略,主要包括以下步骤:

1.预处理阶段:
2.翻译处理:
3.后处理阶段:
以下是一个实际的翻译示例:
原始数据:
{
"conversations": [
{"role": "user", "content": "What's the weather like in Taipei?"},
{"role": "assistant", "content": "Let me check the weather for you."},
{"tool_calls": [{"name": "get_current_weather", "arguments": {"location": "Taipei"}}]}
]
}
翻译后数据:
{
"conversations": [
{"role": "user", "content": "台北的天氣如何?"},
{"role": "assistant", "content": "讓我幫您查看天氣。"},
{"tool_calls": [{"name": "get_current_weather", "arguments": {"location": "Taipei"}}]}
]
}
注意函数名和location参数值保持不变,只翻译对话内容。这种精细的翻译策略确保了函数调用的正确性。
实验结果显示,这种翻译策略在多个语言上都取得了显著效果:
语言原始AST Summary翻译后AST Summary提升中文52.37%61.56%+9.19%日语51.25%59.83%+8.58%韩语50.94%58.71%+7.77%
这些结果证明了该翻译pipeline的有效性和可扩展性。
基于这项研究的发现,我们可以为正在开发基于LLM函数调用功能的工程师提供以下具体建议:
1.提示格式设计
2.训练数据构建
3.多语言支持实现
4.评估和优化
通过这些持续的优化和创新,LLM的函数调用能力变得更加强大和实用,为AI应用开发带来更多可能性。
文章来自微信公众号“AI修猫Prompt”,作者“AI修猫Prompt”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
