# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Paper link:https://arxiv.org/pdf/2412.04455
Project link:https://zhoues.github.io/Code-as-Monitor/
Author:Enshen Zhou, Qi Su, Cheng Chi, Zhizheng Zhang, Zhongyuan Wang, Tiejun Huang, Lu Sheng, He Wang
School of Software, Beihang University; School of Computer Science, Peking University; Beijing Academy of Artificial Intelligence; Galbot
第一作者目前在银河通用机器人Galbot担任研究实习生,曾在上海人工智能实验室实习,研究聚焦多模态大模型应用:模拟世界中使用具身智能体,如Minecraft;现实世界中的机器人操控。



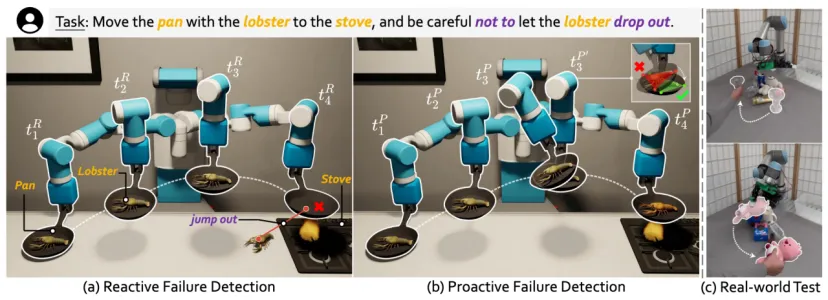
想象机器人端着一口装有龙虾的锅,正将它移动到灶台上方。突然,龙虾跳了出来,或者锅一歪,龙虾滑落了。现实中,机器人常面对不可预见的意外。如何快速发现已发生的事故?(被动检测Reactive Failure Detection)如何提前避免可预见的失败?(主动检测,Proactive Failure Detection)在开放世界中,这两种错误检测都具有挑战性,因为环境复杂且充满未知,错误类型无法完全预定义。
为了解决这个问题,银河通用提出了代码监控器(CaM),利用视觉语言模型(VLM)对开放场景进行Reactive和Proactive的故障检测。CaM将这两个任务表述为一组统一的时空约束满足模型,它可以被VLM精确地转换为可执行程序。这种可视化程序可以验证实体(例如机器人、对象、部件),在执行期间或之后是否达到所需的状态(即满足约束),从而立即进行故障检测。
CaM包含三部分:
约束生成器根据任务指令和已有信息,通过多个视角推导出下一个子目标和相关的文本约束。
Painter将这些约束转化为约束元素,并将它们映射到图像中,形成可视化的约束。
监控器根据这些图像生成监控器代码,并实时跟踪任务执行情况。如果任务执行过程中违反了某个约束,监控器会输出失败的原因并触发任务的重新规划。
研究者将图像中与约束相关的物体或部分提取为更简洁的几何元素(如点、线、面)。通过跟踪和评估这些几何元素在时空中的变化,可以有效地监控约束是否被满足。约束元素的检测和跟踪依赖于这篇工作提出的ConSeg模型和现有的跟踪模型,确保监控的速度和准确性,并能实现开放场景自适应。VLM通过文本约束、子目标的起始帧、相关约束元素的可视化提示生成代码执行监控,生成的监视代码可直接执行。通过跟踪约束元素,系统可实时检测故障,无需重新调用VLM。
这种简化的方法使得开放场景故障检测成为可能,尤其是在面对未知的物体和场景时(得益于约束元素结构化的关联性),并且依赖于VLM提供的丰富先验知识,保持了高效的检测精度和实时执行能力。研究者在三个模拟器(CLIPort、Omnigibson 和 RLBench)以及一个真实世界实验室环境中,进行了实验,涵盖了不同的任务(如挑选和放置、铰接物体、工具使用)、机器人平台(如UR5、Franka)及末端执行器(如吸盘、握把、灵巧手)。实验结果表明,CaM具有良好的可推广性,能够实时进行被动和主动的故障检测。在面临严重干扰的情况下,CaM的成功率提高了28.7%,而执行时间减少了31.8%。此外,CaM还可以与现有的开环控制策略结合,形成一个闭环系统,在充满动态变化和人为干扰的复杂场景中,执行长时间的任务。
对此,研究者提出以下问题:
CaM模型:是否能在不同的机器人、末端执行器和物体之间实现灵活的故障检测,既能反应已发生的失败(被动检测),又能预测未来的潜在失败(主动检测),并在模拟器和真实世界中都有效?
ConSeg模型:能否为机器人在不可见的场景中推断出多粒度的约束感知(例如不同层次的限制,如物体的表面、边界等)?
在所有图像中,CaM使用独特的颜色和数字标签来标注约束元素,这些图像随后作为Visual Prompt,输入到GPT-4o模型中生成监控代码。生成的监控代码会接受元素的三维位置作为输入并进行计算(如使用numpy进行算术运算),以评估执行过程中的时空约束是否被满足。如果计算结果偏离预设公差(如允许15°以内的误差),代码会返回一个标识预测会失败或已经失败的布尔值False,并附带一个字符串说明失败的原因。为了提高效率,研究者使用CoTracker来追踪这些元素的位置,从而实现实时故障检测,而无需频繁地调用VLM(视觉语言模型),减少了计算开销。
通过监测元素的当前位置和历史轨迹,CaM能够有效处理高精度的任务(如要求移动2厘米或旋转180°的任务)。通过代码中约束元素的结构化关联(如计算平面表面元素与z轴之间的夹角来判断平移是否为水平),以及VLM丰富的先验知识,这一方法的泛化性很强。对于长时间操作任务,例如“用面包把锅移到炉子上,小心不要让面包掉出来”,也能够适用。
具体来讲,CaM包括三个主要模块:约束生成器(Generator)、Painter和监视器(Monitor)。机器人通过摄像头从两个角度(前方和顶部)获取环境信息(记作O)。系统的输入包括:
RGB图像(O):来自摄像头的实时环境数据;
任务指令(Lglogal):描述整个任务的目标和要求;
子目标(lpre):任务执行过程中的中间步骤;
失败反馈(fpre):来自监视器的反馈,说明之前子目标是否成功完成以及失败的原因。
这些输入会被传入约束生成器,它根据这些信息生成下一个子目标(lnext)和相关的文本约束(c),指导机器人执行下一步任务。这个过程通过不断反馈和调整任务中的子目标与约束,帮助机器人在执行过程中保持目标的正确性和高效性。
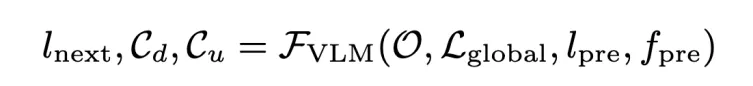
Cd表示子目标执行期间必须保持的约束(如必须抓住锅柄,面包必须留在锅内,锅在转移期间应保持水平),Cu表示子目标完成时必须满足的约束(如锅应直接在炉子上方),通过结合这两类约束,CaM将主动检测和被动检测统一为特定于任务的、情境感知的约束满意度问题。
在Painter中,每个文本约束(如Cd或Cu中的约束c)都生成相应的约束元素。这些元素由三维点组成,可以更简洁地表示与约束相关的实体或它们的部分。例如,面包和锅上的绿点之间的恒定距离决定了面包是否会保持在锅中。接下来,研究者将这些生成的元素汇总到一个最终集合中,并在所有视图中进行数值标注,最终生成视觉提示图像O。
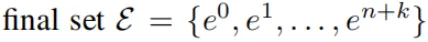
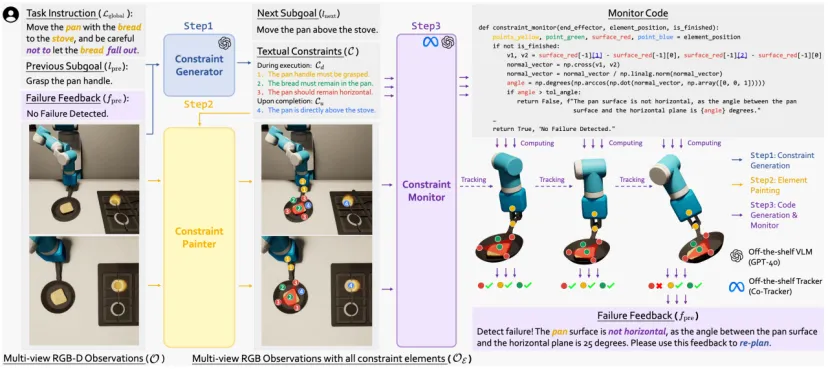
在监控器中,研究者将下一个子目标(lnext)、文本约束(C)和观察结果提供给GPT-4o。这些输入帮助进行约束感知的可视化编程,从而生成监控器代码。代码的工作内容为:
接收元素的三维位置并进行算术运算,然后判断任务是否失败。
如果任务失败,代码返回一个布尔值(True/False)来表示失败,并给出失败的原因(字符串描述)。
在执行子目标时,监控器会持续跟踪这些元素,评估它们的时空变化。如果代码返回False(表示任务失败),机器人立即停止执行,并将失败原因反馈给规划系统,进行重新规划。如果返回True,则认为任务已成功完成。这个过程会不断循环。研究者使用了三个模拟器和一个真实世界的设置来评估CaM:
CLIPort:使用UR5臂和吸盘工具,配合预训练策略执行任务。
Omnigibson:使用抓取机器人控制任务。
RLBench:使用带抓手的Franka臂进行任务控制。
真实世界:使用带Leap Hand的UR5臂,通过开环策略(DexGraspNet 2.0)控制。
为了评估模型的表现,研究者在不同的环境中引入了干扰,导致任务失败,并根据影响的约束进行分类,如点、线、面等。研究主要评估了任务的成功率、执行时间和Token使用情况。(实验没有评估故障判断的准确率,因为监控代码是实时运行的,无法用传统的“成功率”来衡量。)研究者使用DoReMi(DRM)作为所有Setting的Baseline,它通过视觉问答(VQA)频繁查询来检测任务中的中间故障。此外,在CLIPort环境中还包括了Inner Monologue,该Baseline仅在每个子目标完成时检测是否失败。
研究者在CLIPort中评估两个任务,按顺序堆叠和扫描一半的块,成功率和执行时间都有显著提高。
按顺序堆叠,成功的定义为在70秒内正确堆叠块。机器人必须按指定的顺序堆叠块,包括两个点级干扰:(a)每步概率为p,吸盘可能释放一个块,导致其下降;(b)放置位置被[0,q]cm的均匀噪声干扰,可能导致塔倒塌。
扫描一半的块:预训练训练策略中机器人有扫描所有块的倾向,机器人必须确定何时停止,在30秒内将一半的块(±10%)扫描到指定的颜色区域。只有达到这些标准,才能取得成功。
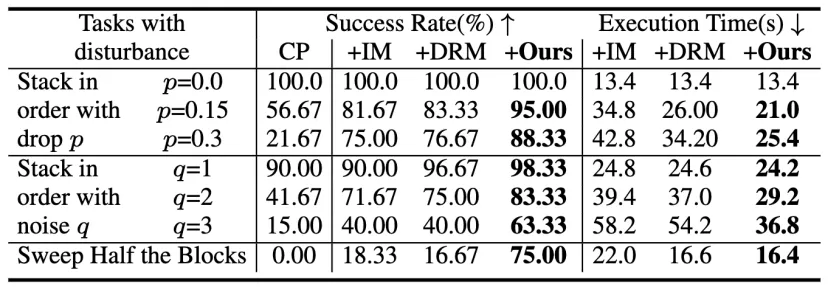
代码可以更好地监控3D空间关系,在“有序堆叠”中最严重的干扰(p=0.3,q=3)下,CaM的成功率比DoReMi高17.5%;带有元素的代码可以使得计数更准确,在“扫描一半的方块”中,CaM的平均成功率比DoReMi高出4.5×。计算指定曲面区域中的块点比直接使用VLM进行计数可以提供更准确的结果,从而能够更精确地停止策略以完成任务。
在Omnigibson的实验中,研究者设计了三个任务,每个任务包括一个无干扰试验和三个特定干扰试验:
插笔(点干扰):将笔插入支架
笔在抓取过程中移动 - 笔在运输过程中放下插入 - 支架移动
放书(线干扰):将书垂直放在书架上
在抓取过程中书随机旋转 - 端执行器关节随机驱动改变书的姿态 - 书放置后水平重定向
倒茶(面干扰):从茶壶倒入茶杯,遇到表面干扰
茶壶在移动时向前/向后倾斜 - 端执行器接头在移动时引起茶壶横向倾斜 - 茶壶在浇筑过程中返回到水平位置
实验结果表明,与频繁调用 VLM 的Baseline(DoReMi)相比:
能够检测更复杂的错误类型:只有Code-as-Monitor能够检测出“端茶倒水”任务中的面级别干扰错误
时间和计算开销更低:执行时间减少了34.8%,token数量减少了52.2%

带有元素的代码可以检测到更丰富的故障,且计算成本较低。与DoReMi相比,只有CaM可以检测到“倒茶”中表面干扰引起的故障。原因是茶壶的螺距和滚动角度的变化很难通过VQA(VLM查询)来检测到,这导致DoReMi在此任务中的成功率为0%;同时,由于VLM对单个图像的时空理解有限,DoReMi的成功率有时低于单独的ReKep。另外,与DoReMi相比,CaM的执行时间减少了34.8%,token计数减少了52.2%。这种改进源于主动故障检测,它可以实时防止提前发生更严重的故障,以便及时重新规划,同时对每个子目标只生成一次代码。
研究者在真实世界中评估了两个任务:
简单的拾取与放置任务:机器人有70秒的时间来拾取物体并将其放到指定位置。任务中有两个干扰因素:
在抓取时,物体会被移动;
在移动过程中,物体可能从机器人的手中掉落。
评估了四种不同类型的物体(例如,可变形物体、透明物体等),每种物体类型选择了3个样本,每个样本进行了10次试验。
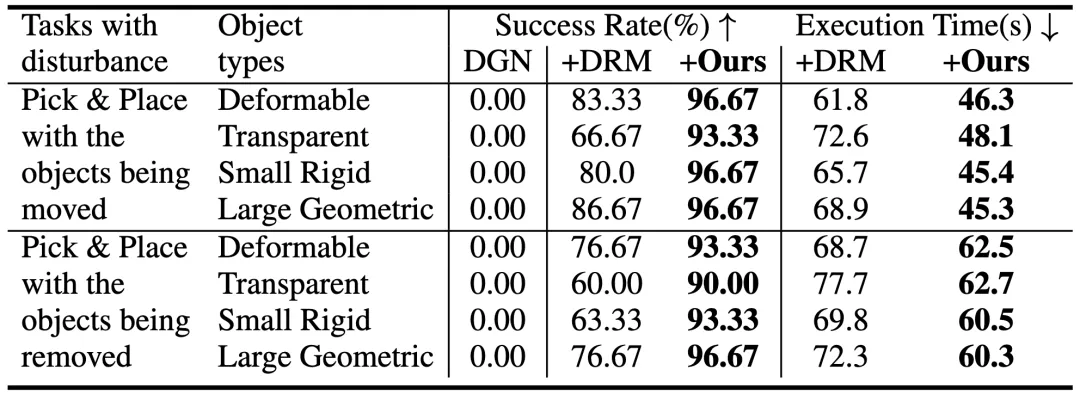

推理选择与放置任务:在同样的干扰条件下,机器人执行较长时间的任务,任务中包含一些模糊的术语(例如,“水果”、“动物”)。研究者在杂乱的场景中测试了两个长期任务,每个任务执行了10次试验。
元素通常指的是抽象的约束条件和与之相关的实体。在简单的挑选和放置任务中,CaM比DoReMi的成功率提高了20.4%。研究者发现,通过抽象化和约束相关的实体或部分,去除了不必要的视觉细节,这使得系统能够更好地适应看不见的场景中的不同物体类型,这种方法使得任务跟踪和代码评估变得更加容易。
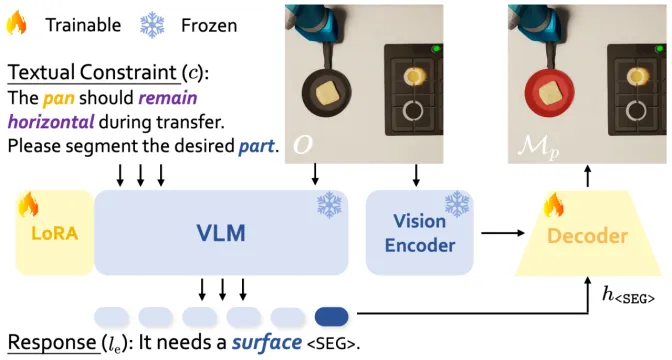
为了简化约束的监控,研究者将复杂的实体或部分转化为更简洁的几何元素(如点、线),并通过这些约束元素去除不相关的视觉细节,使得它们更容易追踪和应用到新场景中。由于约束并未明确指出哪些实体或部件是相关的,需要一个能够进行逻辑推理并具备一定开放集自适应能力的模型,来实现精确的约束感知实例和部分级分割。研究者提出了ConSeg,该模型基于LISA进行改进,包含一个VLM (LLaVA)、SAM的视觉编码器(Fenc)和解码器(Fdec)。
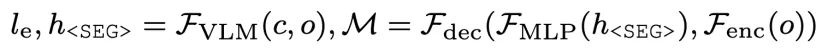
整个流程(包括额外的LoRA参数)是端到端优化的,在优化过程中,VLM和Vision Encoder的参数保持冻结。
主动和被动故障检测与开环策略相结合,形成一个闭环系统,只有CaM能够在混乱的场景中成功地处理长期任务。这些任务是具有挑战性的,因为机器人是由一个开环策略控制的,它不能以闭环的方式处理环境动力学和人类干扰。通过将被动和主动故障检测与开环策略相结合,机器人可以实时动态调整其目标对象。例如,当人类在任务中移动马或梨时,机器人通过抓住最接近水果的动物来适应,有效地形成一个闭环系统。

红色边框显示当前的抓取目标,可能会由于环境变化而改变。CaM可以实时监控和适应这些变化,从而产生一个具有开环策略的闭环系统.
ConSeg同时执行推理和多粒度约束感知分割。如表5中所示,ConSeg在Realseg上的表现与LISA和PixelLM相当,但在Constraintseg上明显超过了他们,在部分水平上实现了近40%的提升。图中的视觉比较进一步证明了ConSeg对看不见的物体、场景和任务的强泛化。

ConSeg和LISA在Instance-level和Part-level上的可视化比较,红色Mask为分割结果.
研究者使用训练过的ConSeg模型,对每个图像和约束执行两个步骤:
○生成实例级掩码(Mi):用来识别与约束相关的物体或部分。
○生成部分级掩码(Mp)和元素类型描述(le):详细描述物体的特征。
使用深度数据,研究者将这些掩码投影到三维空间,并将它们整合为一个点云。由于直接跟踪这些实体的动态变化较为复杂,研究者将它们转化为所需的约束元素。
体素化处理。研究者对点云进行体素化,将空间划分成多个小单元(例如,将表面划分为至少3个点并按2×2的体素格式进行处理)。然后,研究者在每个体素中选择一个代表性点,并根据元素类型描述(le)确定最终需要的3D点。
生成约束元素。通过聚类和筛选,研究者将每个实例级掩码中的点连接起来,形成与约束相关的约束元素。对于一些末端执行器(例如,手指或手掌的位置),可以直接从正向运动学中获取数据,跳过上述步骤。
为了提高效率,研究者在所有视图上并行运行ConSeg推理,从而加快获取最终的约束元素集及其在每个视图中的注释。这种简化的方法通过将复杂的物体和约束抽象为约束元素,使得它们更易于跟踪和应用于新场景。这种方法对于开放集故障检测尤为重要,因为它可以应对未见过的场景和物体。
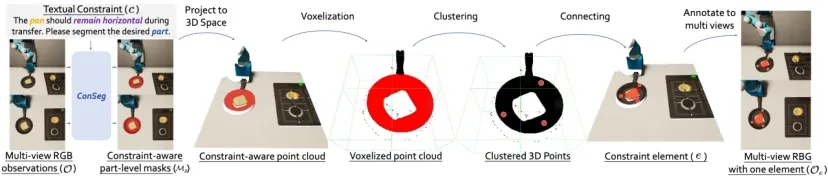
约束元素生成流程:给定一个约束条件,ConSeg模型会在多个视图中生成Instance-level和Part-level的mask,然后将这些mask投影到三维空间中。接着,通过一系列启发式方法生成所需的约束元素。一旦所有元素都生成完毕,它们就会被标注到原始的多视图图像中。图中展示的是一个元素的标注结果。
更多的实验结果、数据集构成、可视化展示(包括约束感知的分割结果)详见论文和主页。
第一作者目前在银河通用机器人Galbot担任研究实习生,曾在上海人工智能实验室实习,研究聚焦多模态大模型应用:模拟世界中使用具身智能体,如Minecraft;现实世界中的机器人操控。

银河通用,成立于2023年5月,背后是学术界的一位巨擘——王鹤教授。王鹤毕业于清华大学电子系,后赴斯坦福大学攻读博士学位,现任北京大学前沿计算研究中心的助理教授与博士生导师。在具身智能领域,王鹤教授凭借其深厚的科研积淀和技术突破,成为行业中的关键人物。最近,他荣获2024年度北京大学-中国光谷成果转化奖,在北大-银河通用具身智能联合实验室的支持下,成功实现了包括可泛化物体操作、3D寻物导航以及灵巧手数据集等多项技术成果的有效转化。银河通用的技术积累迅速落地,推出了全球首个可在现实环境中展示泛化技能的具身智能机器人——Galbot G1。这一突破标志着具身智能技术向产业化迈出了重要一步。
“除了服务千行百业外,我们的最终愿景是将人形机器人应用于家庭环境中,服务千家万户。”——王鹤
编辑:Luka Liu
原文:Code-as-Monitor: Constraint-aware Visual Programming for Reactive and Proactive Robotic Failure Detection
https://arxiv.org/pdf/2412.04455
Ref.
https://mp.weixin.qq.com/s/ug1BKMOQ-Ph6MUxJUnTTTQ
https://mp.weixin.qq.com/s/no4r3_o2LXyzDLrzqPgyDg
https://github.com/Zhoues
文章来自微信公众号“Z Potentials”,作者“Z Potentials”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
