# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型(LLM)在自然语言处理领域取得了令人瞩目的成就,但在需要多步推理的复杂任务中仍面临严峻挑战。这一问题的核心在于,虽然LLM能够处理海量文本数据并生成流畅的回答,但在需要逻辑推理、因果分析和多步骤问题解决时往往表现不佳。这种局限性严重制约了LLM在金融分析、医疗诊断、法律推理等高要求场景的应用。
来自土耳其伊兹密尔理工大学(Izmir Institute of Technology)电气与电子工程系的研究者为多跳推理问题研究出了一个少样本的自动化推理框架。


研究评价:这是一项具有重要创新意义的研究工作。研究团队提出的AutoReason框架巧妙地解决了当前LLM在复杂推理任务中的关键痛点,具有以下突出优势:
虽然在计算资源消耗等方面还有优化空间,但这项研究为增强LLM的推理能力提供了一个富有启发性的思路,值得深入研究和实践应用。
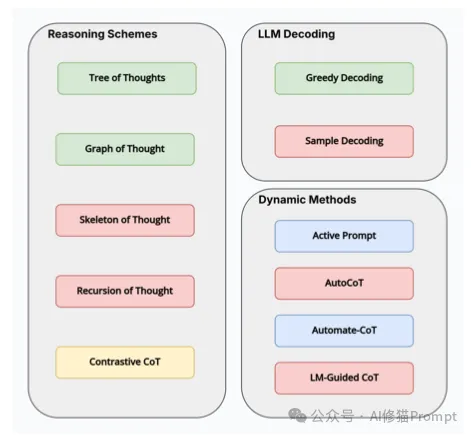
在解决LLM推理能力不足的问题上,研究界已经发展出了一系列基于思维链(Chain of Thought,CoT)的方法。这些方法大致可以分为三大类:
1.推理方案(Reasoning Schemes):
2.LLM解码策略:
3.动态方法:
然而,传统的CoT方法存在两个关键缺陷:首先,它需要人工精心设计示例,这不仅耗时耗力,还需要领域专家的参与;其次,这些固定的示例无法根据不同查询的特点动态调整,导致推理效果不够理想。正是在这样的背景下,AutoReason框架应运而生。

为了更好地理解AutoReason的创新,让我们通过一个具体的例子来说明不同推理方法的差异:
假设有这样一个问题:"一个书架有6个相同大小的层。第一层有14本推理小说,第二层比第一层多5本科幻小说,第三层有3本奇幻小说,第四层的言情小说比第五层的非虚构类书籍少2本,第五层有10本非虚构类书籍,第六层有10本漫画书。书架上总共有多少本书?"
1.直接推理(Zero-shot):
2.零样本思维链:
3.AutoReason方法:
这个例子清晰地展示了AutoReason如何通过分解推理步骤来提高准确性。
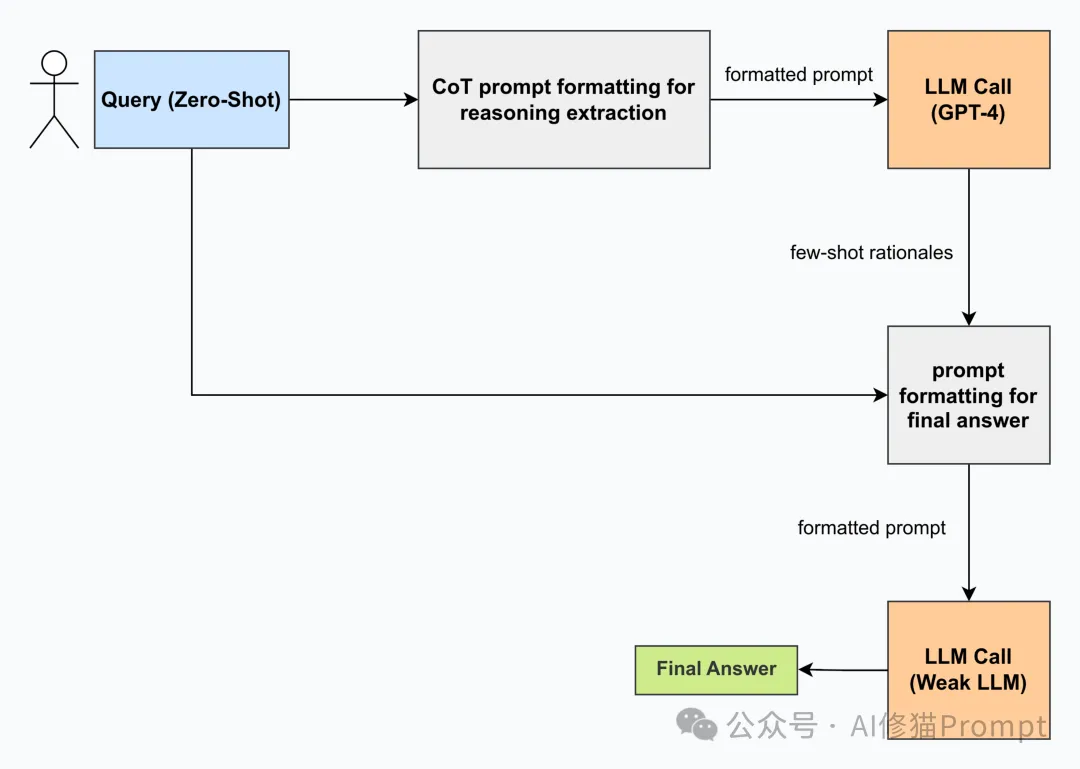
AutoReason采用了精心设计的两阶段处理流程,其完整工作流程如下:

1.查询预处理阶段:
2.推理轨迹生成阶段:
3.答案生成阶段:
4.评分验证阶段:
研究团队选择的两个数据集各具特色:
1.HotpotQA数据集示例:
{
"question": "Were Scott Derrickson and Ed Wood of the same nationality?",
"answer": "yes",
"type": "comparison"
}
{
"question": "What government position was held by the woman who portrayed Corliss Archer in the film Kiss and Tell?",
"answer": "Chief of Protocol",
"type": "bridge"
}
这类问题主要考察模型从多个事实中提取和关联信息的能力。
2.StrategyQA数据集示例:以"James Clark Maxwell与银行通知有什么联系?"为例:
研究团队采用了高度严谨的测试方法:
1.数据预处理:
2.样本抽取:
3.评分机制:
4.结果验证:
研究团队采用了严格的实验设计来验证AutoReason的效果:
1.数据集选择:
2.测试流程:
3.评估指标:

1.StrategyQA数据集上的表现:
2.HotpotQA数据集上的表现:

1.性能提升分析:
2.特殊现象解释:
1.环境准备:
2.提示模板配置:
export const autoReasonPrompt = ({ question }: { question: string }) => {
return 'You will formulate Chain of Thought (CoT) reasoning traces.
CoT is a prompting technique that helps you to think about a problem in a structured way.
It breaks down a problem into a series of logical reasoning traces.
...';
};
3.推理生成流程:
async function generateReasoning(query) {
const formattedQuery = formatQueryWithCoTPrompt(query);
const rationales = await generateRationalesWithGPT4(formattedQuery);
const finalPrompt = formatPromptForFinalAnswer(query, rationales);
return generateFinalAnswerWithWeakerLLM(finalPrompt);
}
1.推理分解技巧:
2.错误处理策略:
3.性能优化方法:
1.计算效率优化:
2.推理质量提升:
3.应用范围扩展:
1.理论方向:
2.应用方向:
AutoReason框架通过创新的自动推理生成方法,有效解决了LLM在复杂推理任务中的瓶颈问题。它不仅显著提升了模型的推理准确率,还为实现可靠的AI推理能力提供了新的思路。虽然在计算效率和应用范围等方面还有待改进,但AutoReason的成功无疑标志着LLM向着更智能、更可靠的方向迈出了重要一步。
对于Prompt工程师而言,AutoReason提供了一个强大的工具和全新的思路,有助于构建更智能、更可靠的AI应用。通过合理运用这一框架,我们可以更好地发挥LLM的潜力,为用户提供更优质的服务。
Sevinc, A., & Gumus, A. (2024). AUTOREASON: AUTOMATIC FEW-SHOT REASONING DECOMPOSITION. arXiv preprint.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., ... & Zhou, D. (2023). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.
Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., & Iwasawa, Y. (2023). Large Language Models are Zero-Shot Reasoners.
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W. W., Salakhutdinov, R., & Manning, C. D. (2018). HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering.
Geva, M., Khashabi, D., Segal, E., Khot, T., Roth, D., & Berant, J. (2021). Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies.
文章来自于微信公众号“AI修猫Prompt”,作者“AI修猫Prompt”



【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
