# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在讨论了 RAG 的 chunking、embedding、评估指标、评估流程等技术后,我们进一步探讨 RAG 系统的实际应用。在实际项目中,RAG(Retrieval-Augmented Generation)系统的检索阶段往往是影响生成效果的核心环节。RAG 系统的工作流程包括数据摄取(Data Ingestion)和数据查询(Data Querying),其中检索是至关重要的一步。本文介绍了在一个案例中,团队如何通过2个关键技巧把 RAG 检索准确率从 50% 提高到 95 %
RAG 检索准确率(Recall)是衡量检索系统能否找到与用户查询相关的所有文档的指标。它在 RAG 系统中尤为重要,因为如果检索阶段无法提供足够的上下文,即使生成模型再强大,也难以输出高质量结果。高检索准确率是确保生成内容相关性的基础。
检索准确率(Recall)公式如下:

示例:
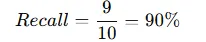
在这个案例中,我们通过两个关键改进,使系统的检索准确率从 50-60% 提升至 95% 以上。此项目的背景是为客户服务团队构建一个内部聊天机器人,以帮助客服人员更快地访问信息。
项目初始阶段包括:
数据包括有关地点(如水疗中心和健身房)和专家(如按摩治疗师和私人教练)的信息。数据通过将文本字段(描述、城市、地区)合并为一个内容字段,并为向量搜索创建 embeddings 来准备。
最初的搜索查询要么作为向量搜索,要么作为全文 BM25 搜索对内容字段运行。然而,系统仅在 50-60% 的时间内检索到正确的文档。
向量搜索不适合这个应用,因为它优先考虑模糊匹配和语义相似性,而我们的应用需要精确匹配。BM25 搜索也不够,因为它基于术语频率,导致包含更多匹配查询术语的文档优先显示,而不是匹配相关术语的文档。BM25 还存在芬兰语词形变化的问题,稍微的词形变化会阻止文档检索。
系统采用了向量搜索 和BM25 全文搜索 的组合,然而:
这些问题导致检索结果相关性不足,严重影响了用户体验。
通过以下两项关键改进,系统的检索准确率得以显著提升:
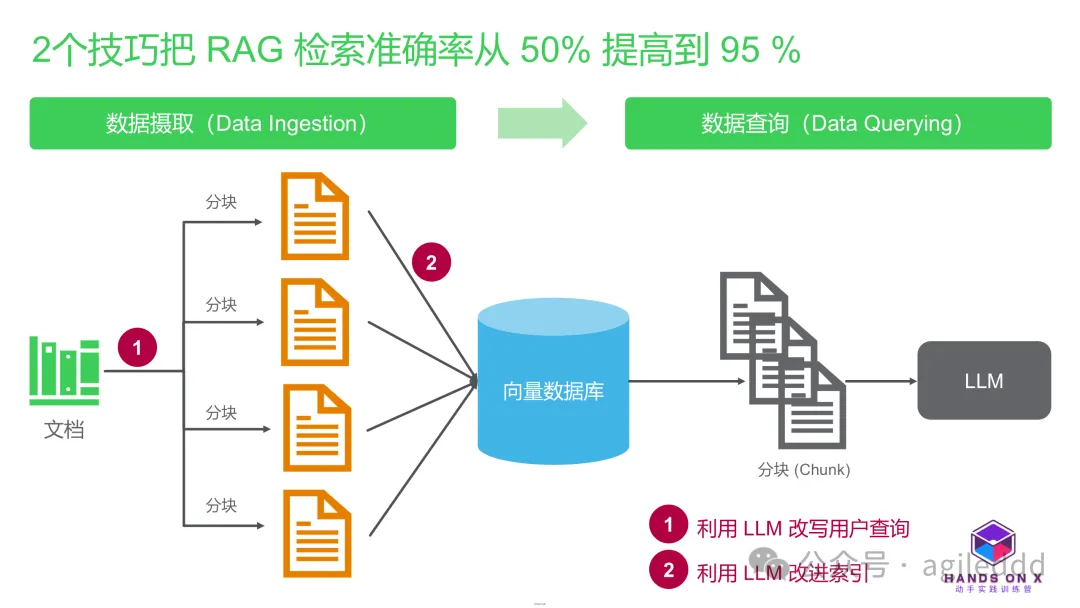
2个技巧把 RAG 检索准确率从 50% 提高到 95 %
本案例的关键收获如下:
高效的检索不仅为生成阶段提供了坚实基础,也证明了技术优化应聚焦于用户需求,避免盲目追求复杂性。
文章来自于微信公众号“非架构”,作者“非架构”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
