# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
上周发出《AI时代写Prompt应该用APPL:为Prompt工程打造的编程语言,来自清华姚班的博士》之后,文章中实现了一个Google DeepMind的OPRO简单版本的优化方法,这让很多读者非常着迷。OPRO是一个非常基础的Prompt迭代方法,之前也有文章介绍过《谷歌DeepMind重磅:提示工程师必须掌握OPRO,用LLM就能自动优化Prompt|ICLR2024》。
很多朋友询问用APPL是否能够实现复杂一些的优化方法,应广大读者的要求,董博士熬夜(北京时间下午4点,多伦多时间已经是凌晨3点了)为大家写了一个reppl,用APPL复现了上个月大厂之间很火的Pormpt优化框架ERM,《北航、字节和浙大最新发布Prompt Optimization优化框架ERM,让你的提示词优化更高效准确》原论文只给出了部分Prompt,现在用APPL复现了该算法。以下是微信中Github原文Blog的中文版,除.cursorrules处提示、知识库设置和原论文图片外均为原文,建议大家看下原文有更多链接。同时上周询问过的朋友Git最新版本文件包括.cursorrules。以及pip install -U applang

本博客文章展示了如何利用AI辅助快速实现复杂算法,使用APPL(一种提示编程语言)。我们将通过重新实现基于范例引导的反思记忆机制(ERM)算法,在Big-Bench-Hard的navigate任务上达到99.3%的准确率,展示APPL和AI辅助如何加速算法实现。
APPL旨在将LLM无缝集成到程序中。更多详情,请查看APPL文档。以下是使ERM等提示优化算法实现变得简单的APPL关键特性:
APPL可以通过Python代码动态增长提示,同时保持提示的文本外观,如下例所示:
@ppl
def optimize_prompt(prompt: str, error_samples: List[Dict], feedbacks: List[str]):
# other codes ...
"The current prompt is:"
prompt
"But this prompt gets the following examples wrong:"
for sample in error_samples:
f"text: {sample['input']}"
f"label: {sample['target']}"
# other codes ...
response = gen("large") # 使用配置的“大”模型来计算
在使用AI助手时,建议使用显式模式以便于注意力机制,其中使用显式的grow()函数来增长提示,如grow(f"text: {sample['input']}")。
APPL的默认异步设计使得多个提示候选的评估变得高效:
@ppl
def evaluate_prompt(prompt: str, data: str) -> float:
grow(prompt.format(input=data))
return gen("small") # 使用配置的“小”模型来计算
# 并行得获得responses
responses = [evaluate_prompt(prompt, d) for d in data]
# 根据responses计算结果
results = [get_metric(str(response), d) for response, d in zip(responses, data)]
如示例所示,APPL为不同任务提供了三个可配置的默认模型:default、large和small。因此,开发者只需为任务指定默认模型,它们就可以根据用户的偏好配置为不同的模型。
在提示优化示例中,优化器模型通常需要更强大,因此使用large模型。另一方面,评估器模型通常需要更高效和更低成本,因此使用small模型。
例如,你可以在appl.yaml中(https://github.com/appl-team/reppl/blob/main/appl.yaml)配置默认服务器:
default_servers:
small: "gpt-4o-mini"
large: "gpt-4o"
让我们来看看如何使用AI辅助实现ERM。该过程包含几个关键步骤:
首先,我们将论文下载到resources文件夹(https://github.com/appl-team/reppl/tree/main/prompt-optimization/resources/)并将PDF转换为markdown格式以便更好地访问:
pip install markitdown
markitdown resources/erm.pdf > resources/erm.md
这使我们在实现时可以轻松参考算法细节。
如ERM论文中使用的,我们从GPO处理的BBH数据集(https://github.com/txy77/GPO/tree/main/data/BIG-Bench-Hard)获取`navigate`任务的数据到[`data`](https://github.com/appl-team/reppl/tree/main/prompt-optimization/data/bbh/navigate/)目录下
mkdir -p data/bbh/navigate
cd data/bbh/navigate
curl -o train.jsonl https://raw.githubusercontent.com/RUCAIBox/GPO/refs/heads/main/data/reasoning/GSM8K/train.jsonl
curl -o eval.jsonl https://raw.githubusercontent.com/RUCAIBox/GPO/refs/heads/main/data/reasoning/GSM8K/eval.jsonl
curl -o test.jsonl https://raw.githubusercontent.com/RUCAIBox/GPO/refs/heads/main/data/reasoning/GSM8K/test.jsonl
# curl -o few_shot_examples.jsonl https://raw.githubusercontent.com/RUCAIBox/GPO/refs/heads/main/data/reasoning/GSM8K/few_shot_examples.jsonl
# curl -o format.jsonl https://raw.githubusercontent.com/RUCAIBox/GPO/refs/heads/main/data/reasoning/GSM8K/format.jsonl
cd ../../..
然后我们需要设置.cursorrules来告诉Cursor Composer(https://github.com/appl-team/appl/blob/main/.cursorrules)
关于APPL及其规则。我们还需要用APPL文档(https://appl-team.github.io/appl/docs)设置Docs Index来帮助Cursor Composer理解APPL。(https://docs.cursor.com/context/@-symbols/@-docs)
Cursor settings下的Features点击Add new doc即可添加知识库。
注意:.cursorrules已完成更新,应该添加到你的项目根目录下。
在composer中,我们用以下Prompt直接询问(我们在这里展开文本中的@以便更好地阅读,它们实际上是composer中的符号):
根据转换后的markdown文件[@erm.md](./erm.md)(从原始pdf转换)实现erm算法。你应该使用图2中的流程和图4和5中相同的提示。使用`../../data/bbh/navigate/`文件夹中的数据进行训练和测试。参考[@APPL](https://appl-team.github.io/appl/docs)。
我们可以得到代码的初始版本。
然后我们提出后续问题(一个接一个)来帮助进一步完善代码:
- 解释反馈和范例是如何被选择、更新和遗忘的?
- 你能将反馈和工厂的共享部分合并到一个基类中吗?
- 论文中优先级分数是如何更新的,如何实现?
然后我们手动编辑代码并运行测试(参见文件编辑历史)(https://github.com/appl-team/reppl/commits/main/prompt-optimization/algo/erm/erm.py))。在Cursor代码补全的帮助下,编辑工作并不繁重。
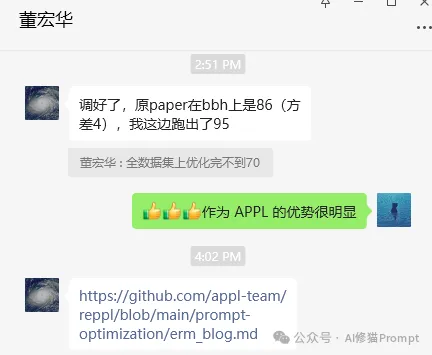
下图是原论文BBH上86.1%的准确率Table。

在bbh/navigate上的最终结果是:
初始提示:测试集上72.2%的准确率。
## Task
If you follow these instructions, do you return to the starting point?
## Output format
Answer Yes or No as labels.
## Prediction
Text: {input}\n
Label:
经过五轮(第一轮和最后一轮有相同的验证准确率):
最终提示:测试集上99.3%的准确率。
## Task
Determine if a series of movements and rotations described in the text results in returning to the starting point. Consider movements in terms of forward/backward and left/right actions, and account for rotations.
## Instructions
1. Begin at the starting point facing forward.
2. Translate each instruction into a movement on a coordinate plane:
- Steps backward and forward affect the y-axis.
- Steps left and right affect the x-axis.
3. Recognize rotations (e.g., "Turn right," "Turn around") and adjust the movement axes accordingly:
- Turning right changes the forward direction to the right.
- Turning around changes the forward direction to the opposite direction.
4. Determine if the final position on the coordinate plane is the same as the starting point.
## Output Format
Predict "Yes" if the final position is the starting point, otherwise predict "No".
## Prediction
Text: {input}
Label:
作为参考,Big-Bench-Hard中的导航任务是询问文本中描述的一系列移动和旋转是否会返回起点。以下是输入示例:
If you follow these instructions, do you return to the starting point? Always face forward. Take 1 step backward. Take 9 steps left. Take 2 steps backward. Take 6 steps forward. Take 4 steps forward. Take 4 steps backward. Take 3 steps right.
Options:
- Yes
- No
APPL提供了一种方便的方式来可视化过程。我们已经为你提供了ERM算法的跟踪记录(https://github.com/appl-team/reppl/blob/main/prompt-optimization/traces/erm_trace.pkl)以复现过程。你可以为APPL设置Langfuse(https://appl-team.github.io/appl/setup/#langfuse-recommended)
然后运行:
appltrace ./traces/erm_trace.pkl
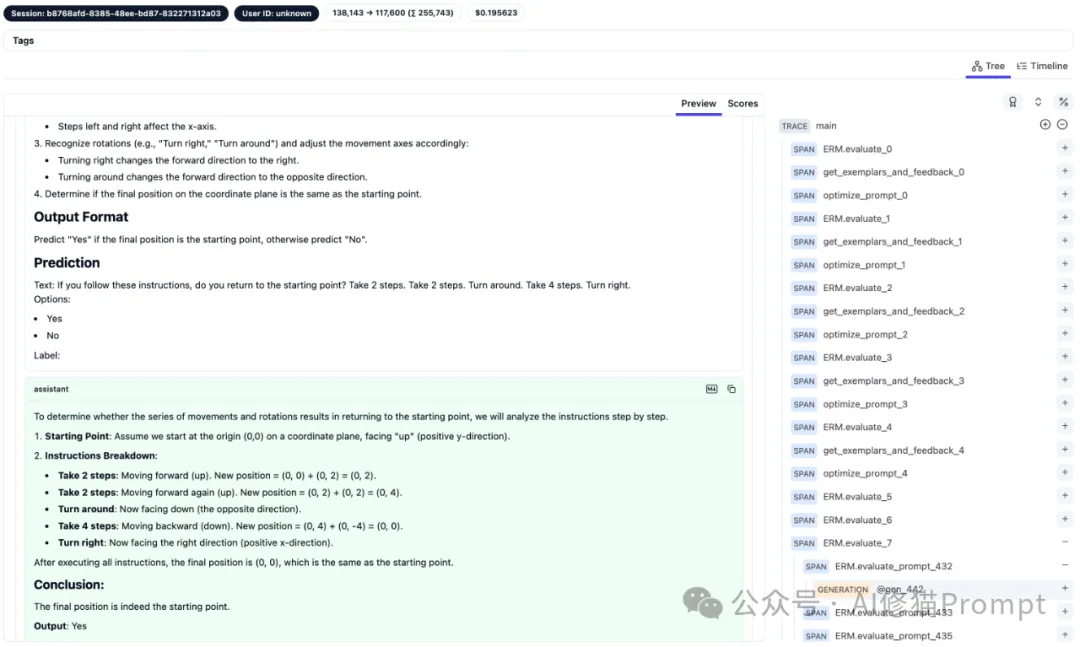
要复现结果,你可以运行:
pip install -U applang
APPL_RESUME_TRACE=./traces/erm_trace.pkl python algo/erm/erm.py
通过利用APPL和通过Cursor提供的AI辅助,我们能够快速实现ERM算法,同时保持代码质量。实现过程展示了现代工具如何加速算法开发:
完整实现请查看此仓库。关于APPL的另一个重新实现示例,请参见思维树实现。
[代码仓库](https://github.com/appl-team/reppl/tree/main/prompt-optimization/)
[思维树实现](https://github.com/appl-team/reppl/tree/main/tree-of-thoughts/README.md)
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
