
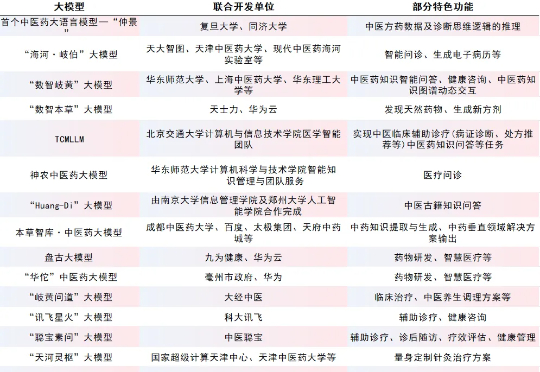
最新进展!国内医学AI领域迎来新突破,这些大模型你了解吗?
最新进展!国内医学AI领域迎来新突破,这些大模型你了解吗?肾病防治迈向智能化、精准化:北大第一医院发布“肾说”大模型,医疗科技的不断创新,正在为患者提供更加高效、便捷的医疗服务。
来自主题: AI技术研报
7063 点击 2025-06-06 14:30
肾病防治迈向智能化、精准化:北大第一医院发布“肾说”大模型,医疗科技的不断创新,正在为患者提供更加高效、便捷的医疗服务。

AI模型用于工业异常检测,再次取得新SOTA!

这篇文章不只是关于 Coding Agent 的使用体验,也包括对相关关键技术,例如语言搜索、MCP 的探索和理解。Coding Agent 结合 MCP 是一种值得探索的新的自动化方式。
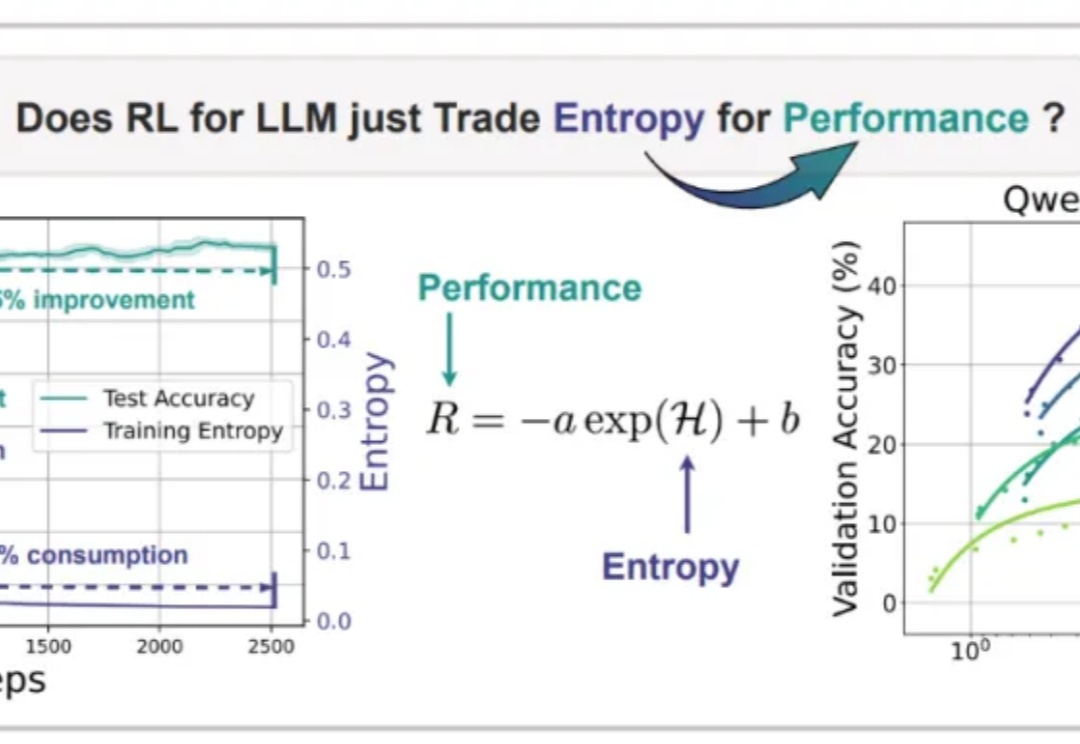
Nature never undertakes any change unless her interests are served by an increase in entropy. 自然界的任何变化,唯有在熵增符合其利益时方会发生——Max Planck
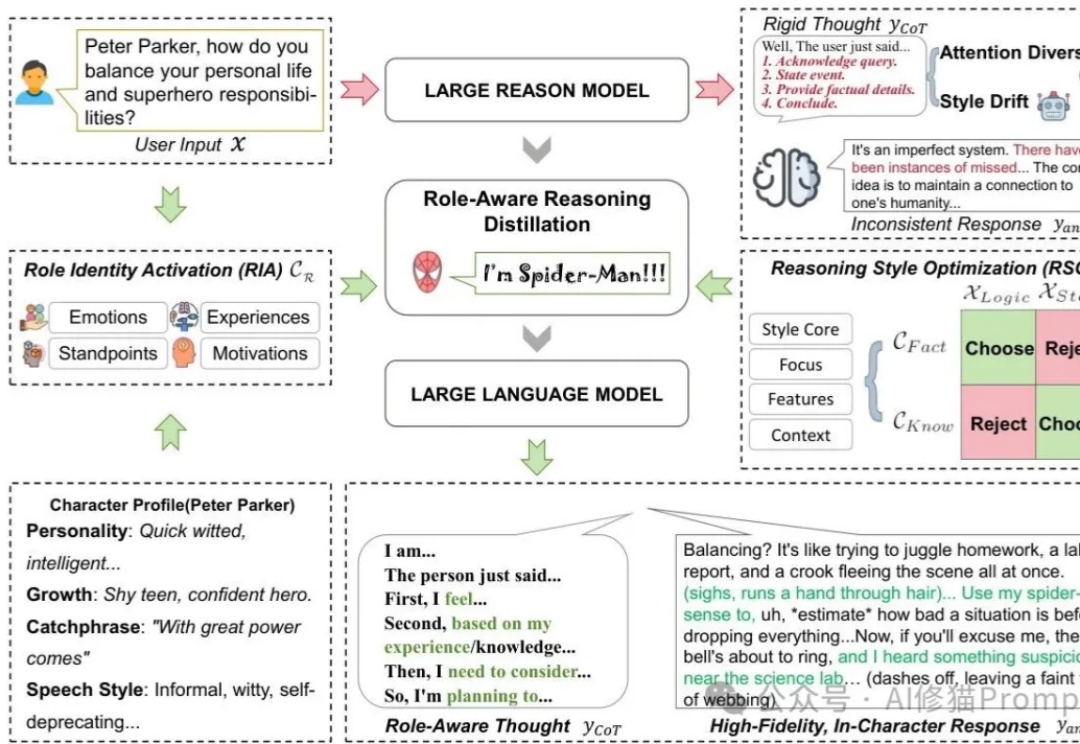
您有没有发现,现在市面上的AI角色扮演的Agent总有种「隔靴搔痒」的感觉?用户和AI聊天时,AI虽然能说出符合角色设定的话,但总觉得缺了点什么——就像演员在背台词,而不是真的在思考。感觉很假,也很奇怪。
近年来,AI的迅猛发展也使科研范式发生了根本性变革。

如果你面前有两个AI助手:一个能力超强却总爱“离经叛道”,另一个规规矩矩却经常“答非所问”,你会怎么选?
近期arxiv最热门论文,Qwen&清华LeapLab团队最新成果: 在强化学习训练大模型推理能力时,仅仅20%的高熵token就能撑起整个训练效果,甚至比用全部token训练还要好。

科学家用AI重构《死海古卷》时间线,震撼圈内!最新研究显示,《但以理书》《传道书》部分古卷实际成书更早,甚至揭示了圣经作者线索。AI模型Enoch结合碳14定年与笔迹分析,首创AI定年方法,大幅超越传统古文字学。
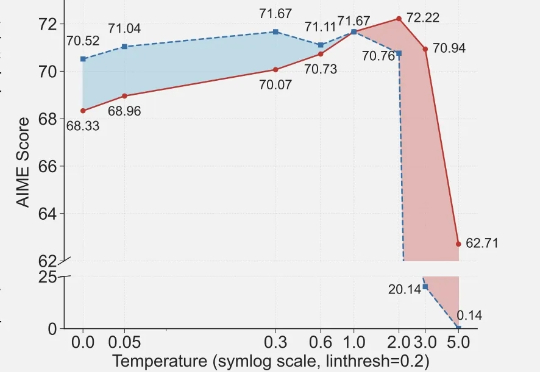
大模型推理,无疑是当下最受热议的科技话题之一。
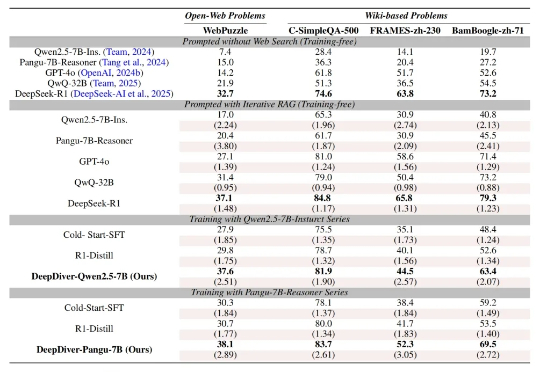
大型语言模型 (LLM) 的发展日新月异,但实时「内化」与时俱进的知识仍然是一项挑战。如何让模型在面对复杂的知识密集型问题时,能够自主决策获取外部知识的策略?

清华与蚂蚁联合开源AReaL-boba²,实现全异步强化学习训练系统,有效解耦模型生成与训练流程,GPU利用率大幅提升。14B模型在多个代码基准测试中达到SOTA,性能接近235B模型。异步RL训练上大分!
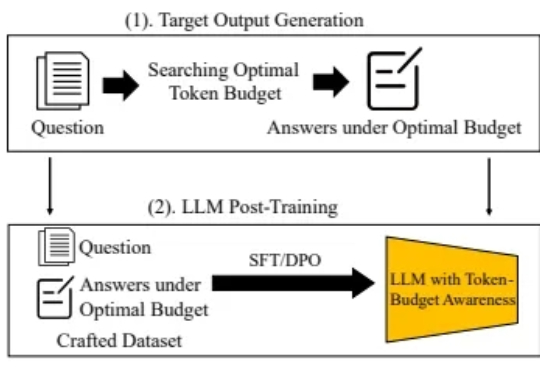
随着大型语言模型(LLM)技术的不断发展,Chain-of-Thought(CoT) 等推理增强方法被提出,以期提升模型在数学题解、逻辑问答等复杂任务中的表现,并通过引导模型逐步思考,有效提高了模型准确率。

1、深度研究实际场景 2、深度研究是什么,它用了什么能力? 3、在深度研究上,AI 为啥比人强这么多? 4、哪些问题,值得用深度研究方式来做? 5、怎样用好深度研究,保持结果的稳定性? 6、各类深度研究产品的特点以及使用技巧?

本研究由广州趣丸科技团队完成,团队长期致力于 AI 驱动的虚拟人生成与交互技术,相关成果已应用于游戏、影视及社交场景

数学家出手反击AI!对AlphaEvolve在“集合和差问题”上的成果进一步改进。
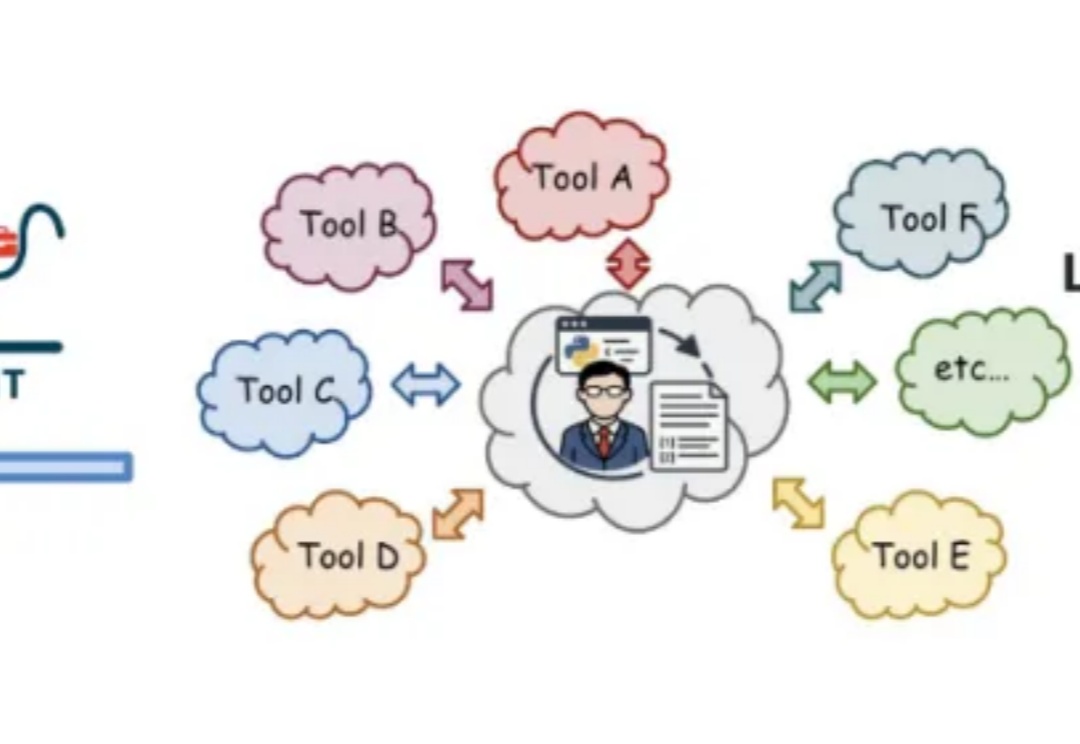
智能体技术日益发展,但现有的许多通用智能体仍然高度依赖于人工预定义好的工具库和工作流,这极大限制了其创造力、可扩展性与泛化能力。

无监督的熵最小化(EM)方法仅需一条未标注数据和约10步优化,就能显著提升大模型在推理任务上的表现,甚至超越依赖大量数据和复杂奖励机制的强化学习(RL)。EM通过优化模型的预测分布,增强其对正确答案的置信度,为大模型后训练提供了一种更高效简洁的新思路。
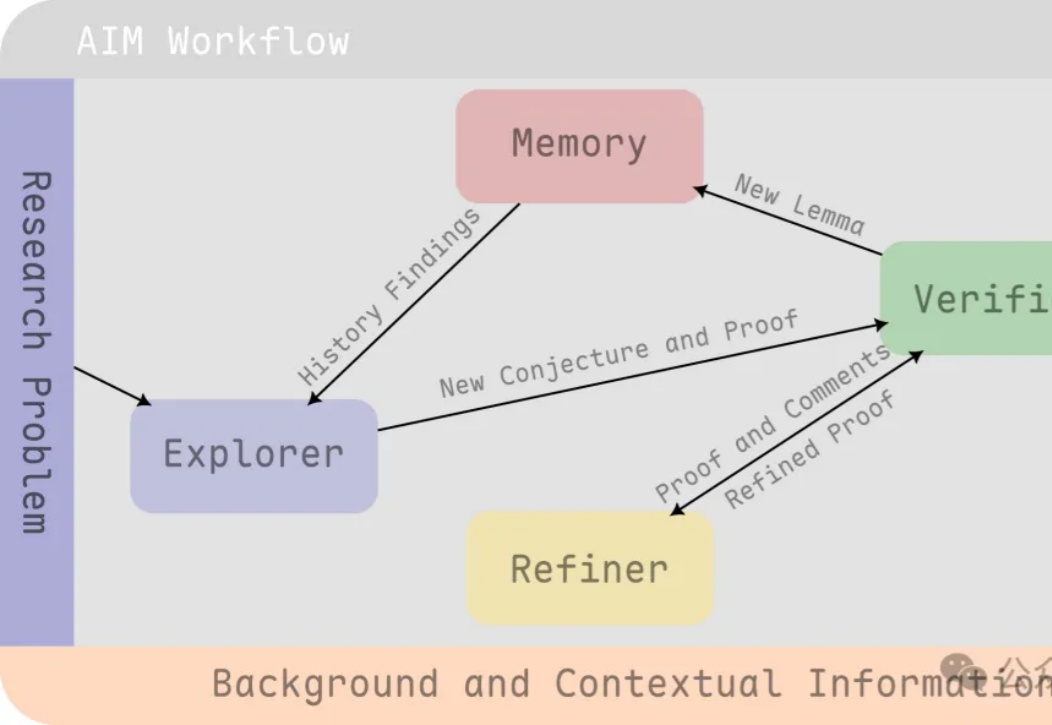
AI数学家来了!清华团队出品—— 他们推出AI Mathematician(AIM)框架,推理模型也能求解前沿理论研究,并且证明完成度很高。
最近一个很火的话题是“AI寒门”,最初由北京大学教育学院副教授林小英提出,指的是父母由于认知局限,不善用甚至排斥AI,导致孩子错失AI浪潮下优化教育资源的机会。
如果你正在开发Agent产品,一定听过或用过Mixture-of-Agents(MoA)架构。这个让多个AI模型协作解决复杂问题的框架,理论上能够集众家之长,实际使用中却让人又爱又恨:
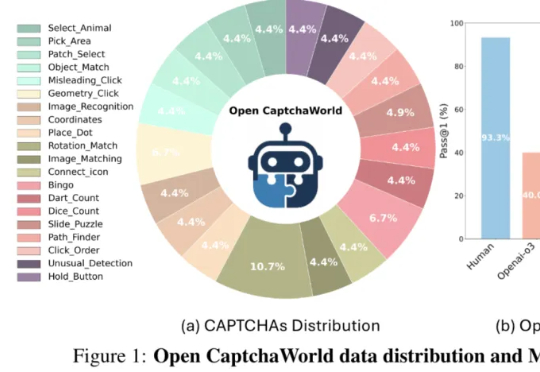
当前最强多模态Agent连验证码都解不了?
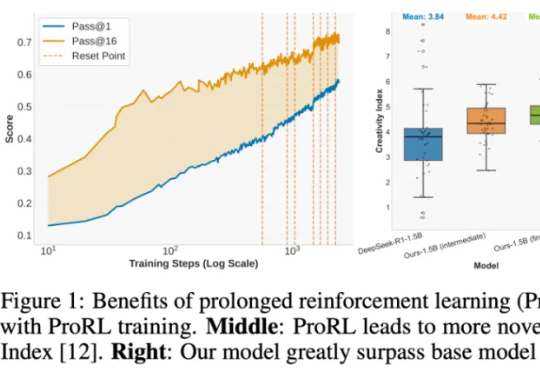
强化学习(RL)到底是语言模型能力进化的「发动机」,还是只是更努力地背题、换个方式答题?这个问题,学界争论已久:RL 真能让模型学会新的推理技能吗,还是只是提高了已有知识的调用效率?
仅听几秒人声,即可完成逼真复刻,而且是对话式语音。

最近,华为在MoE训练系统方面,给出了MoE训练算子和内存优化新方案:三大核心算子全面提速,系统吞吐再提20%,Selective R/S实现内存节省70%。

GPT 系列模型的记忆容量约为每个参数 3.6 比特。
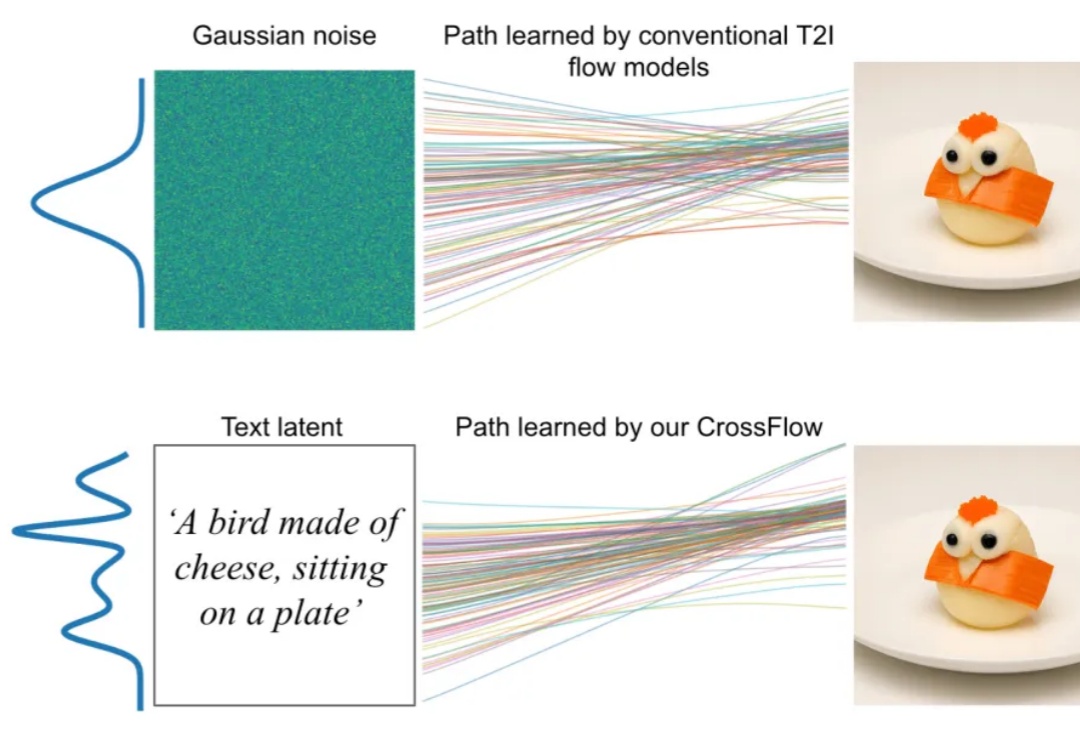
在人工智能领域,跨模态生成(如文本到图像、图像到文本)一直是技术发展的前沿方向。现有方法如扩散模型(Diffusion Models)和流匹配(Flow Matching)虽取得了显著进展,但仍面临依赖噪声分布、复杂条件机制等挑战。
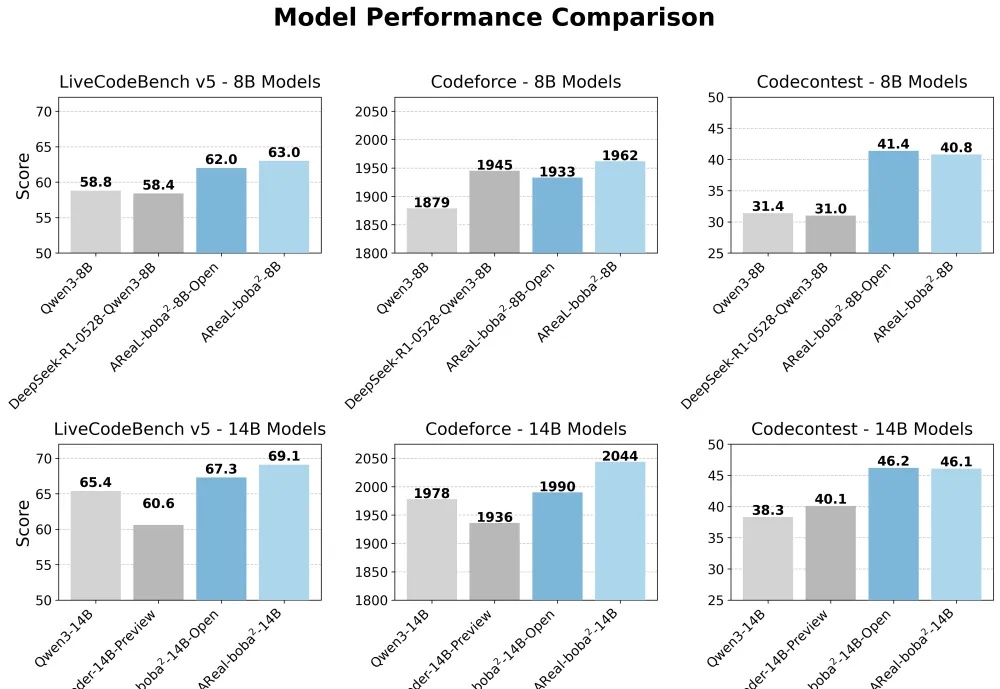
想训练属于自己的高性能推理模型,却被同步强化学习(RL)框架的低效率和高门槛劝退?AReaL 全面升级,更快,更强,更好用!
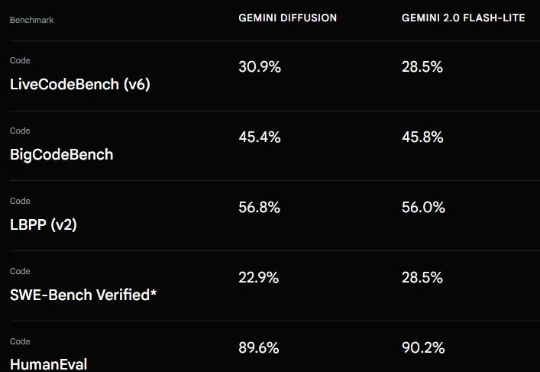
上个月 21 号,Google I/O 2025 开发者大会可说是吸睛无数,各种 AI 模型、技术、工具、服务、应用让人目不暇接。在这其中,Gemini Diffusion 绝对算是最让人兴奋的进步之一。从名字看得出来,这是一个采用了扩散模型的 AI 模型,而这个模型却并非我们通常看到的扩散式视觉生成模型,而是一个地地道道的语言模型!

LLM根本不会思考!LeCun团队新作直接戳破了大模型神话。最新实验揭示了,AI仅在粗糙分类任务表现优秀,却在精细任务中彻底失灵。