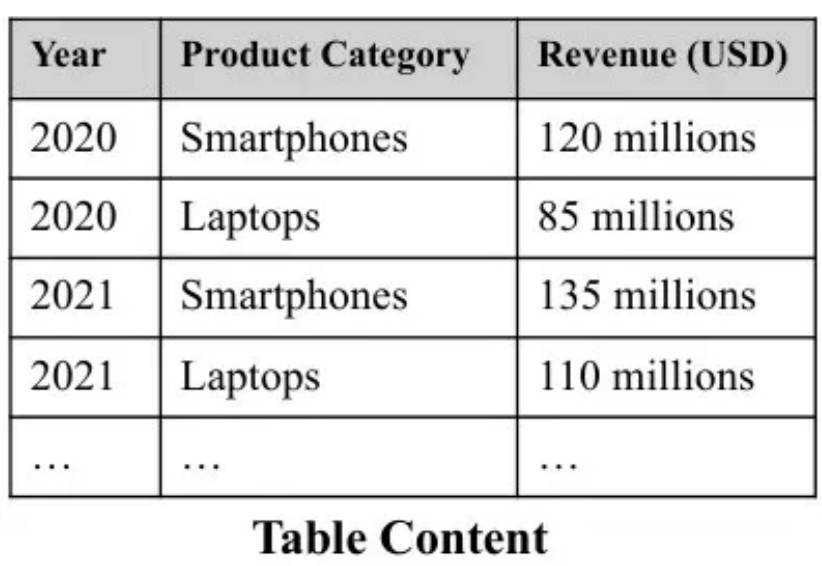
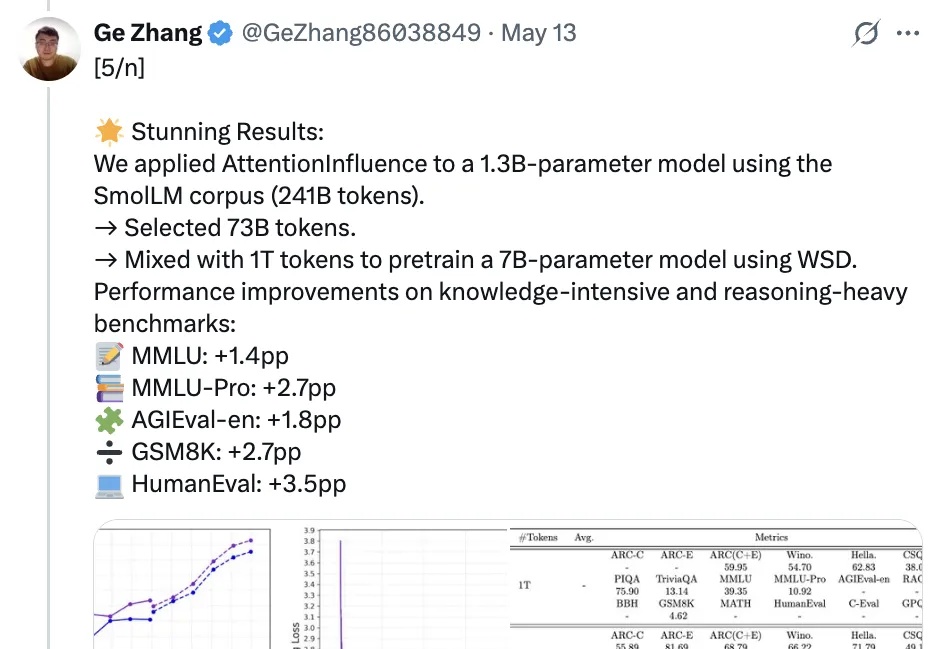
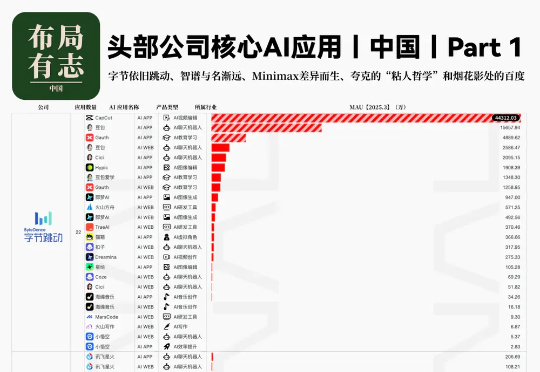
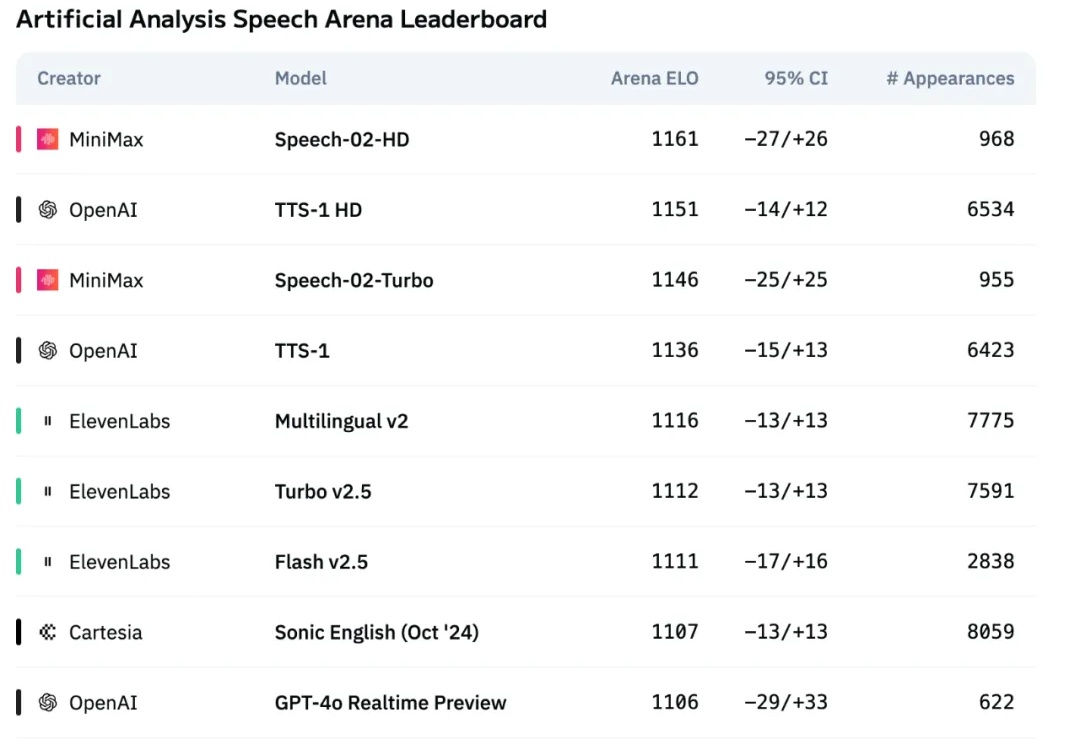
1篇长文 = N张小红书爆款图?!Gemini 2.5 Pro 这效率,我跪了!
1篇长文 = N张小红书爆款图?!Gemini 2.5 Pro 这效率,我跪了!你有没有这样的烦恼:辛辛苦苦写完一篇公众号文章,想转发到小红书,却要再花大量时间制作3:4比例的精美图片?作为一个小红书小号拥有者(小1万粉丝呢,虽然躺在那吃灰有点可惜),我深知这种痛苦。每次想着要做几张图片就头大,甚至因此放弃了不少内容的二次分发。
来自主题: AI技术研报
8187 点击 2025-05-19 11:06