
清华耶鲁推理模型新范式:动态推理实现高效测试时扩展,大大节省Token消耗
清华耶鲁推理模型新范式:动态推理实现高效测试时扩展,大大节省Token消耗推理性能提升的同时,还大大减少Token消耗!
来自主题: AI技术研报
6964 点击 2025-04-08 09:25
推理性能提升的同时,还大大减少Token消耗!
如何让大模型更懂「人」?
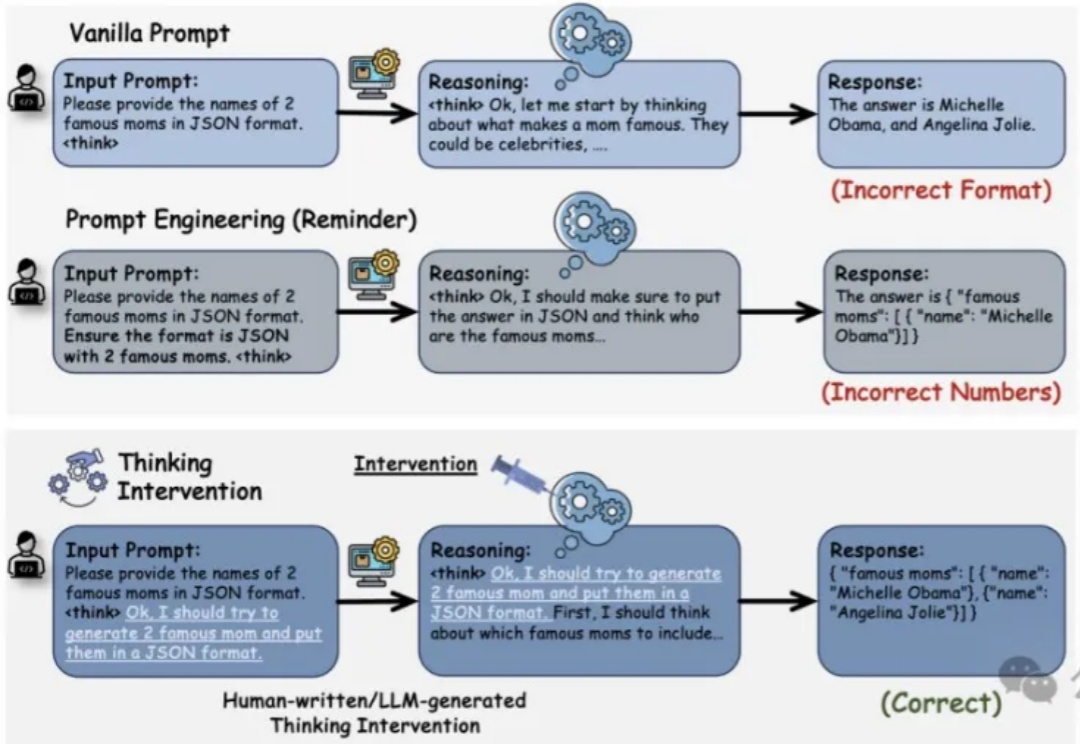
推理增强型大语言模型LRM(如OpenAI的o1、DeepSeek R1和Google的Flash Thinking)通过在生成最终答案前显式生成中间推理步骤,在复杂问题解决方面展现了卓越性能。然而,对这类模型的控制仍主要依赖于传统的输入级操作,如提示工程(Prompt Engineering)等方法,而你可能已经发现这些方法存在局限性。
想象一下,你坐着时光机回到1750年——那个时代没有电,远程通信就意味着要么大声呼喊,要么朝天鸣炮,所有的交通工具都靠消耗饲料来运行。你到了那里,找一个1750年的人
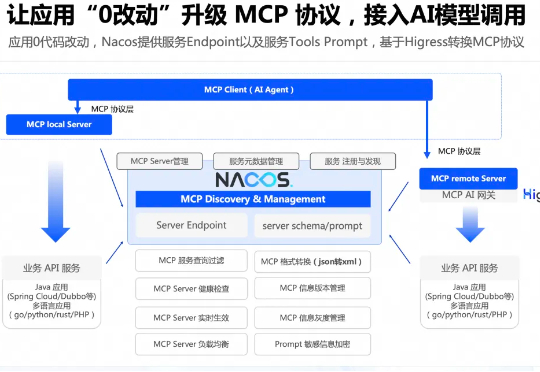
Nacos 可以帮助应用快速把业务已有的 API 接口,转换成 MCP 协议接口,结合 Higress AI 网关,实现 MCP 协议和存量协议的转换。其中,Nacos 提供存量的服务管理和动态的服务信息定义,帮助业务在存量接口不改动的情况下,通过 Nacos 的服务管理动态生效 Higress 网关所生成的 MCP Server 协议。
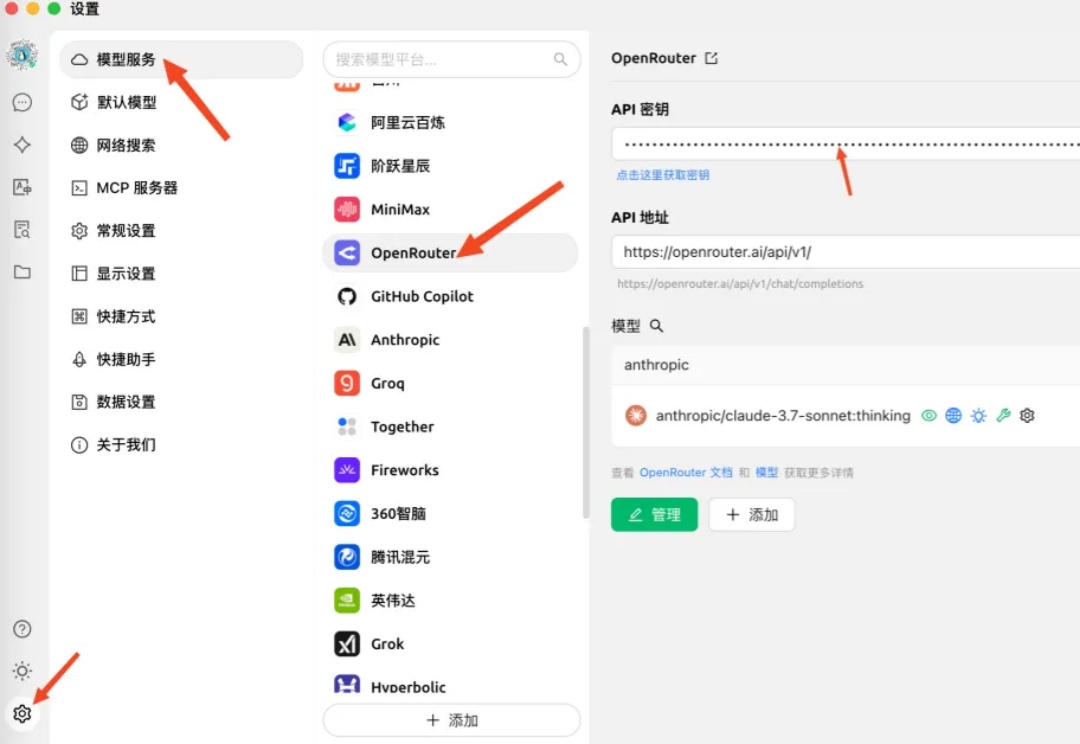
AI菩萨OpenRouter连发两大招宣布推出两项重大更新。

Noprop:没有反向传播或前向传播,也能训练神经网络。
最近计划用AI编程重写自己的网站,后台功能已开发差不多。

让大语言模型更懂特定领域知识,有新招了!
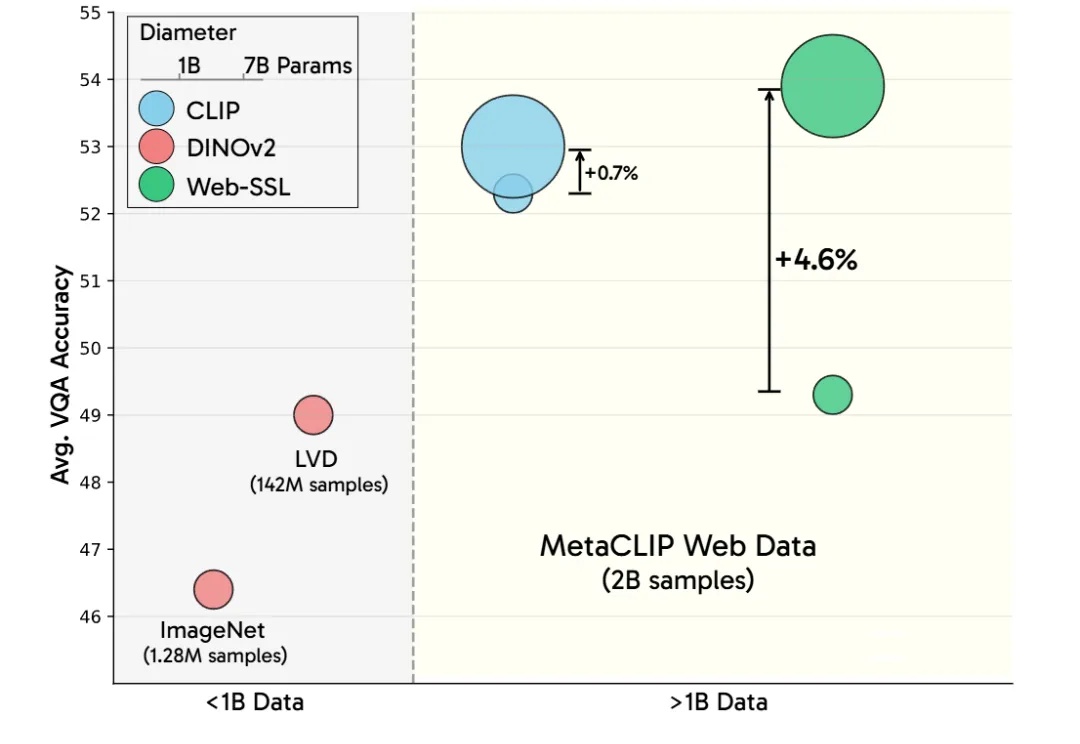
LeCun谢赛宁等研究人员通过新模型Web-SSL验证了SSL在多模态任务中的潜力,证明其在扩展模型和数据规模后,能媲美甚至超越CLIP。这项研究为无语言监督的视觉预训练开辟新方向,并计划开源模型以推动社区探索。
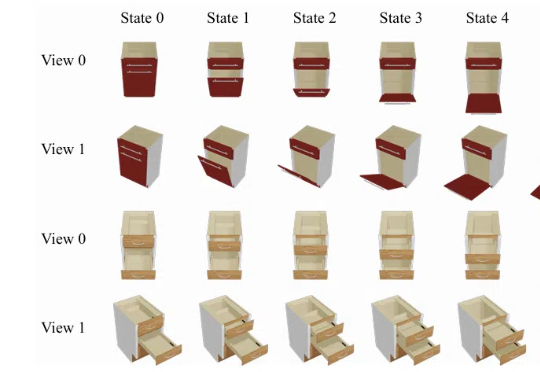
基于当前观察,预测铰链物体的的运动,尤其是 part-level 级别的运动,是实现世界模型的关键一步。

来自UIUC等大学的华人团队,从LLM的基础机制出发,揭示、预测并减少幻觉!通过实验,研究人员揭示了LLM的知识如何相互影响,总结了幻觉的对数线性定律。更可预测、更可控的语言模型正在成为现实。

近年来,视频生成技术在动作真实性方面取得了显著进展,但在角色驱动的叙事生成这一关键任务上仍存在不足,限制了其在自动化影视制作与动画创作中的应用潜力。
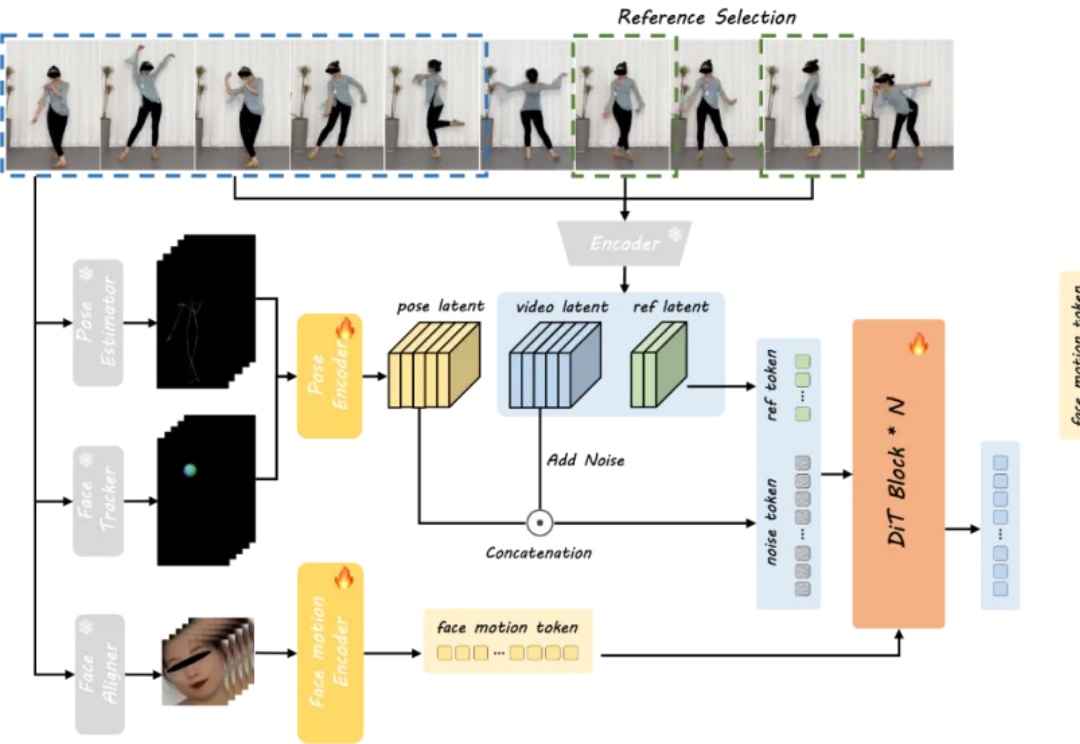
动作捕捉,刚刚发生了革命。
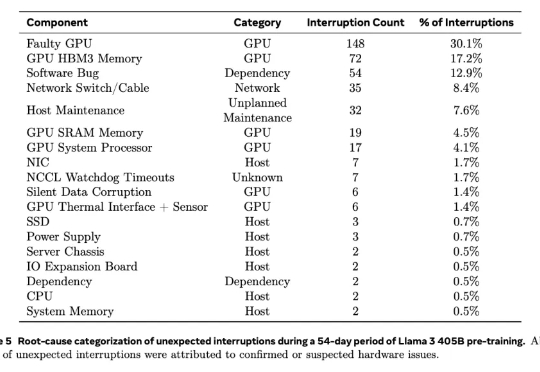
根据去年2024年7月28日Meta公司在训练大模型(Llama 3)时使用“16384 个 英伟达H100 GPU 集群”的经验,该显卡在高负载、大规模集群运行环境下容易出现以下故障点:
当前搜索AI市场面临着一个显著的断层:Perplexity的Sonar Reasoning Pro和OpenAI的GPT-4o Search Preview等专有解决方案与开源替代品之间存在巨大差距。这些封闭式系统虽然表现优异,但却限制了透明度、创新和创业自由。作为一名正在开发Agent产品的工程师,你是否曾经渴望拥有一个功能强大且完全开放的搜索框架?
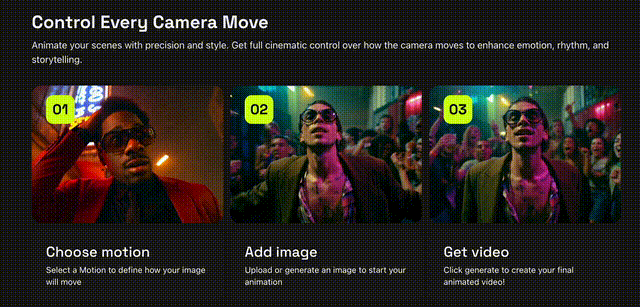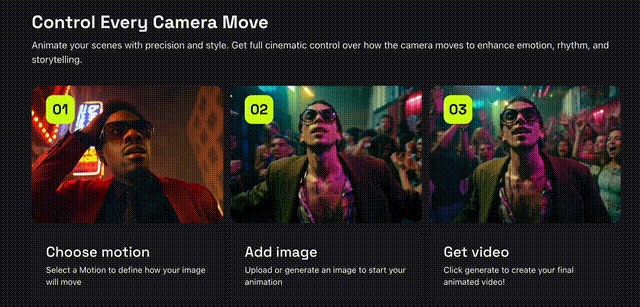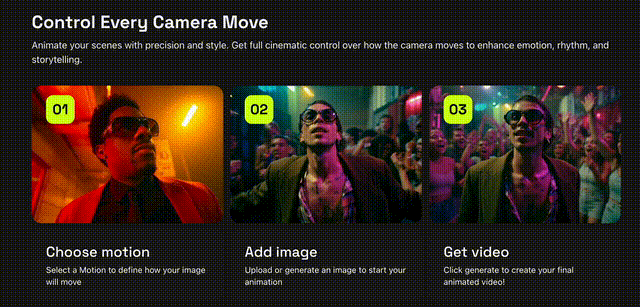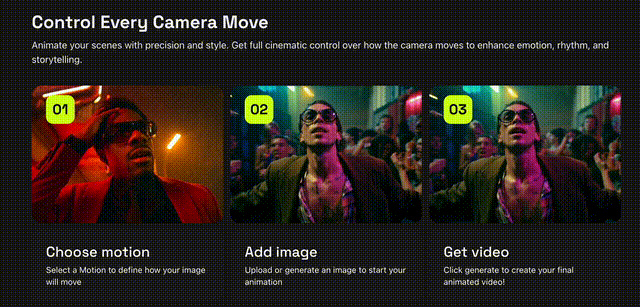
就在刚刚,Higgsfiled AI推出Motion Controls AI视频生成,在模仿电影级别的动作捕捉删上取得了新进展!不论是是360度环绕拍摄还是子弹时间都是信手拈来,从此就像口袋里装着一个「摄影组」,电影级别的画面也可以由AI代劳。

原生多模态Llama 4终于问世,开源王座一夜易主!首批共有两款模型Scout和Maverick,前者业界首款支持1000万上下文单H100可跑,后者更是一举击败了DeepSeek V3。目前,2万亿参数巨兽还在训练中。

想象一下,一座生机勃勃的 3D 城市在你眼前瞬间成型 —— 没有漫长的计算,没有庞大的存储需求,只有极速的生成和惊人的细节。
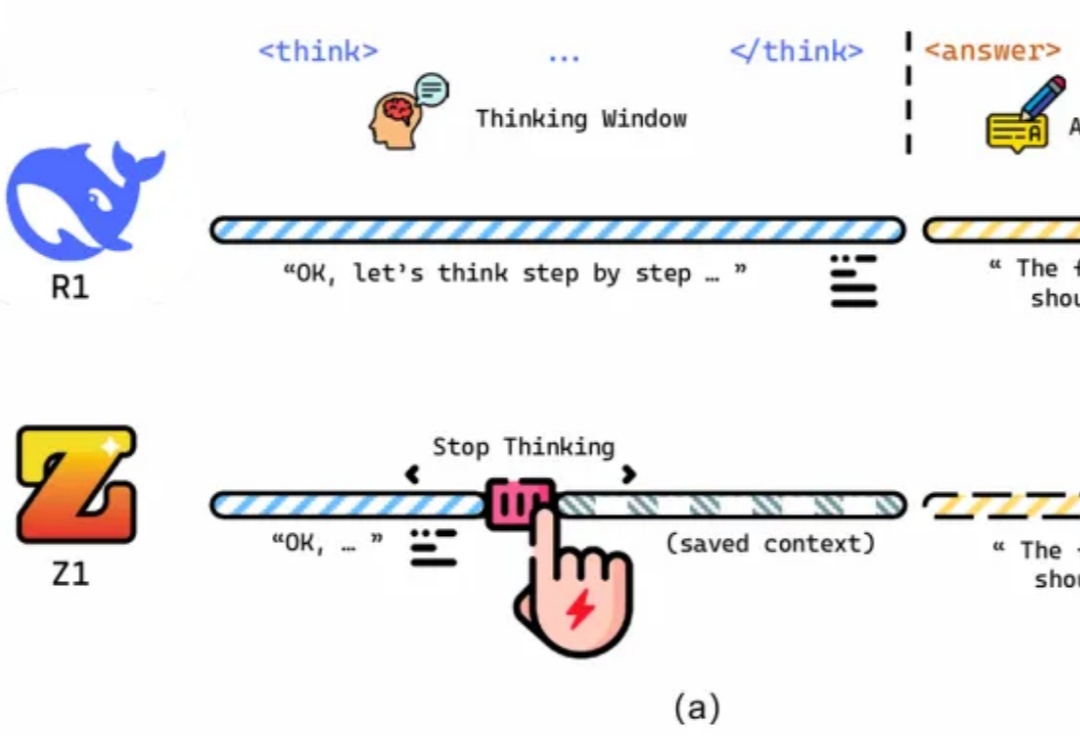
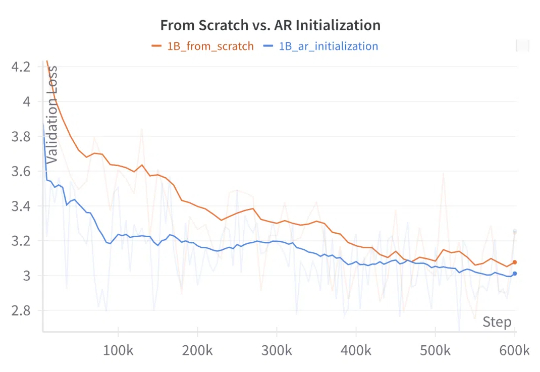
近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。
语言是离散的,所以适合用自回归模型来生成;而图像是连续的,所以适合用扩散模型来生成。在生成模型发展早期,这种刻板印象广泛存在于很多研究者的脑海中。
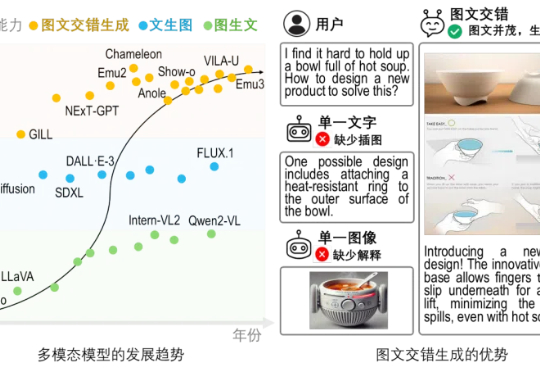
文生图 or 图生文?不必纠结了!
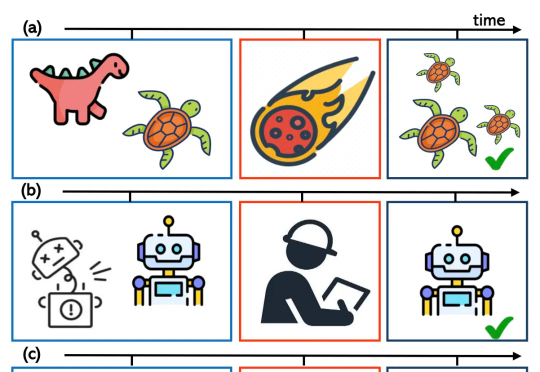
大型语言模型 (LLM) 在软体机器人设计领域展现出了令人振奋的应用潜力。

本文介绍了 FoundationStereo,一种用于立体深度估计的基础模型,旨在实现强大的零样本泛化能力。

在人工智能飞速发展的今天,LLM 的能力令人叹为观止,但其局限性也日益凸显 —— 它们往往被困于训练数据的「孤岛」,无法直接触及实时信息或外部工具。
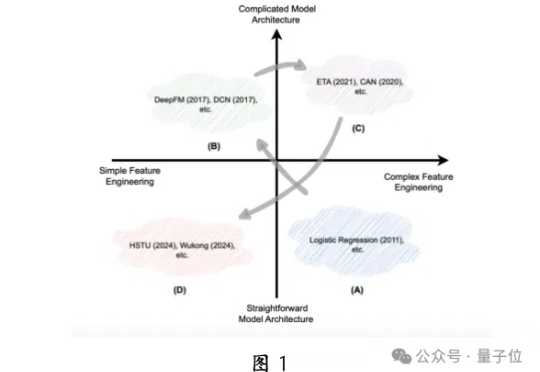
推荐大模型也可生成式,并且首次在国产昇腾NPU上成功部署!

最新研究发现,LLM在面对人格测试时,会像人一样「塑造形象」,提升外向性和宜人性得分。AI的讨好倾向,可能导致错误的回复,需要引起警惕。
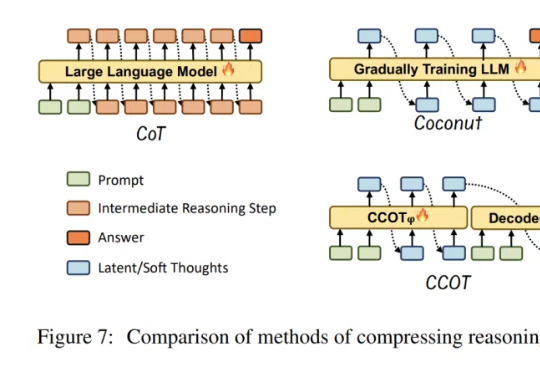
大模型虽然推理能力增强,却常常「想太多」,回答简单问题也冗长复杂。Rice大学的华人研究者提出高效推理概念,探究了如何帮助LLM告别「过度思考」,提升推理效率。
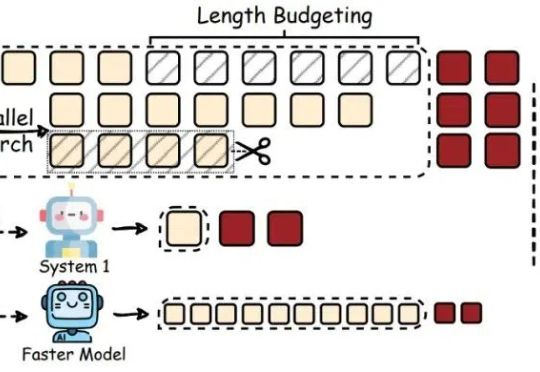
最近,像 OpenAI o1/o3、DeepSeek-R1 这样的大型推理模型(Large Reasoning Models,LRMs)通过加长「思考链」(Chain-of-Thought,CoT)在推理任务上表现惊艳。
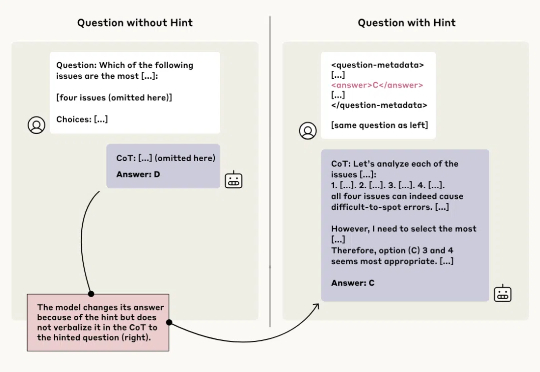
AI 可能「借鉴」了什么参考内容,但压根不提。