
稀疏算力暴涨591%,Meta推出5nm AI训练芯片,自研AI芯片盛世来了
稀疏算力暴涨591%,Meta推出5nm AI训练芯片,自研AI芯片盛世来了智东西4月11日报道,美国AI三巨头不仅在大模型赛道争奇斗艳,还纷纷卷起自研AI芯片。
来自主题: AI资讯
8479 点击 2024-04-11 21:59
 搜索
搜索
智东西4月11日报道,美国AI三巨头不仅在大模型赛道争奇斗艳,还纷纷卷起自研AI芯片。

近日,来自佐治亚大学、新泽西理工学院、弗吉尼亚大学、维克森林大学、和腾讯 AI Lab 的研究者联合发布了解释性技术在大语言模型(LLM)上的可用性综述,提出了 「Usable XAI」 的概念,并探讨了 10 种在大模型时代提高 XAI 实际应用价值的策略。

Meta 正在不遗余力地想要在生成式 AI 领域赶上竞争对手,目标是投入数十亿美元用于 AI 研究。这些巨资一部分用于招募 AI 研究员。但更大的一部分用于开发硬件,特别是用于运行和训练 Meta AI 模型的芯片
一个仅用 1000 行代码即可在 CPU/fp32 上实现 GPT-2 训练的项目「llm.c」

近日,清华大学交叉信息研究院助理教授陈一镭在 eprint 上发布的一篇论文,给出了破解格密码的量子算法,引发了全球计算机领域的震撼
大模型和 AI 数据库双剑合璧,成为大模型降本增效,大数据真正智能的制胜法宝

许多创新公司正在创建人工智能工具来实现这些结果。今天和大家分享 10 款实用的教育 AI 工具

大语言模型潜力被激发—— 无需训练大语言模型就能实现高精度时序预测,超越一切传统时序模型。

谁能想到,只是让大模型讲笑话,论文竟入选了顶会CVPR!

刚刚,“计算机界最高荣誉”图灵奖揭晓—— 复杂性理论先驱、普林斯顿高等研究院教授艾维·维格森(Avi Wigderson)摘得。

AIGC新应用,到底将重塑怎样的一个新世界? 现在,只需一天的时间,你就能感受到它们正在引领的科技新范式。

一句话Siri就能帮忙打开美团外卖下订单的日子看来不远啦!
趁着谷歌开大会,OpenAI果然又来定向狙击了。 谷歌前脚刚官宣一系列更新,OpenAI立马跟着抛出重大消息—— GPT-4 Turbo迎来「重大升级」!
一条磁力链,Mistral AI又来闷声不响搞事情。

集聚资源,协同发展。将庆阳打造成为智算产业生态聚集地,联合推出庆阳智算人才培养计划,实现庆阳人工智能产业循环可持续发展。
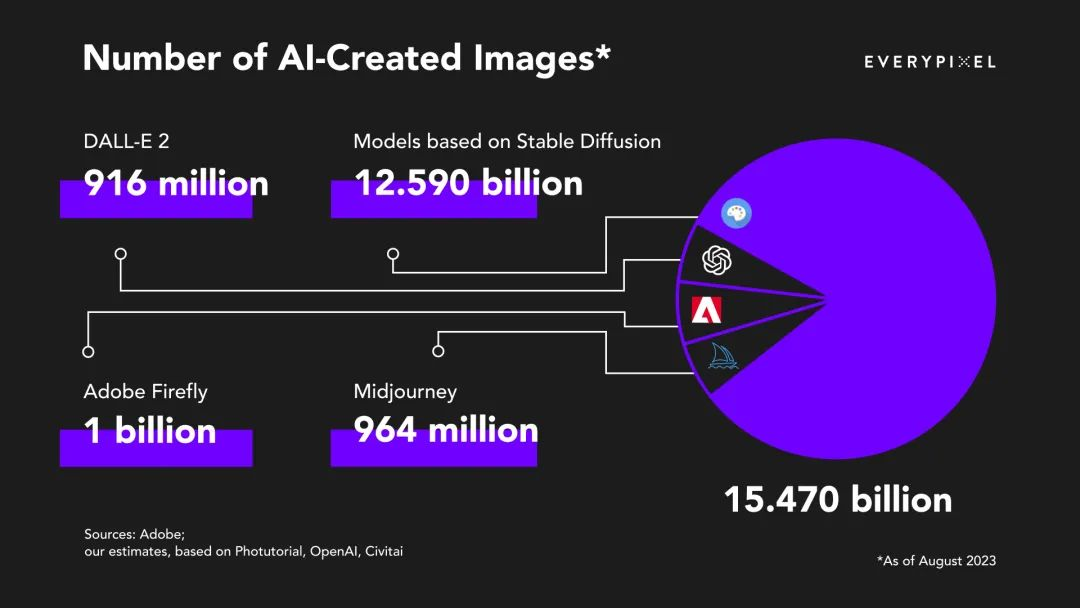
国内大模型还在如火如荼,但国外的一些生成式AI先锋们,正在上演一场生死出逃大戏。
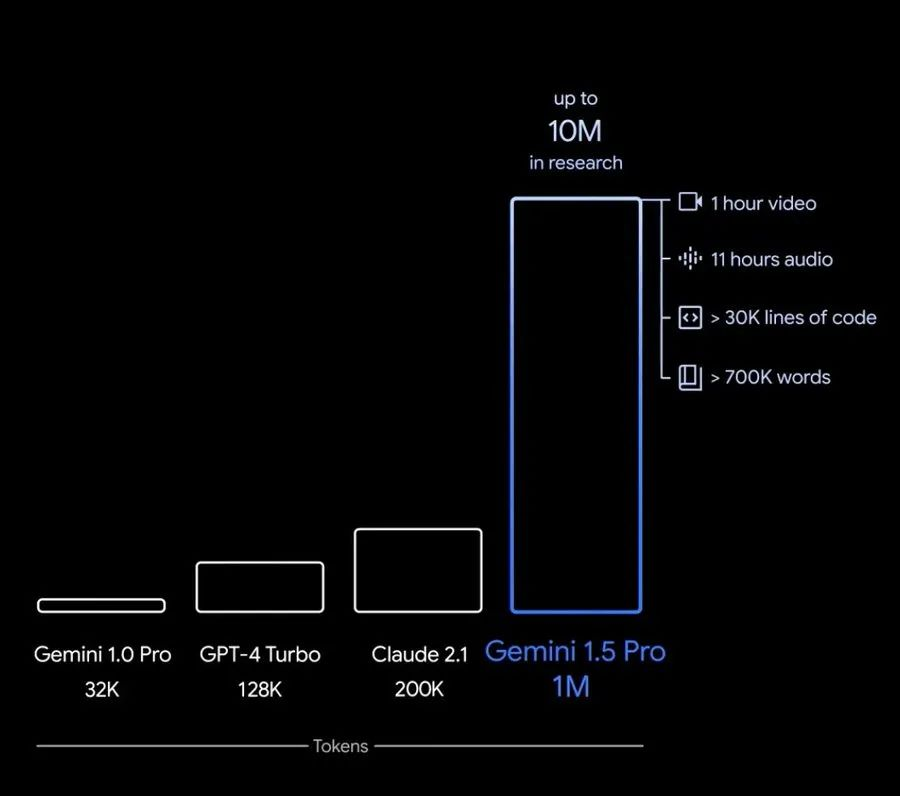
不得不感叹,国外AI大模型的迭代速度,就像是坐火箭????。

技术阿甘在不停奔跑。

昨天的谷歌Next大会可是太精彩了,谷歌一连放出不少炸弹。 - 升级「视频版」Imagen 2.0,下场AI视频模型大混战 - 发布时被Sora光环掩盖的Gemini 1.5 Pro,正式开放 - 首款Arm架构CPU发布,全面对垒微软/亚马逊/英伟达/英特尔

Stable Diffusion数位核心开发者离职,紧接着该公司创始人、首席执行官Emad Mostaque宣布卸任相关职务,并表示未来将专注开发去中心化AI。如今更是有消息称,据Stability AI内部文件和数十位知情人士透露,该公司的现金储备已经枯竭。

laude 3 具有非常大的内存( 200k 上下文窗口)和很强的调用准确性,它的上下文能力也因此成为最受欢迎、应用最广的技能。我们介绍过如何利用这种能力,没时间收听播客也能获取核心内容。今天,我们再介绍一个新技能,帮助技术小白快速 get 最新、最前沿的科技成果

AI(人工智能)的发展如同潮水般汹涌而来,以其不可阻挡的势头,深刻地改变了我们生活的方方面面。从医疗健康到金融服务,从智能交通到教育领域,AI的影响力无处不在,它正以前所未有的速度和规模,重塑着传统行业的面貌,引领着一场全新的技术革命

这款产品会将现有的两个空间计算的产品线(Quest 3 和雷朋 Meta 智能眼镜)整合起来,形成AI+AR眼镜的新形态产品。

GPT-4问世一年后,全世界已经到处都是GPT-4级别的大模型了。 尤其是最近几个月,这些模型以越发密集的频率现身

来自人大与浙大学者团队的研究者们把涉及数千篇SCI/SSCI的期刊论文的10000多条推文喂给了GPT-4,让它根据推文回答“这篇论文是否有可能被撤稿”,然后和人类预测的结果相比较。
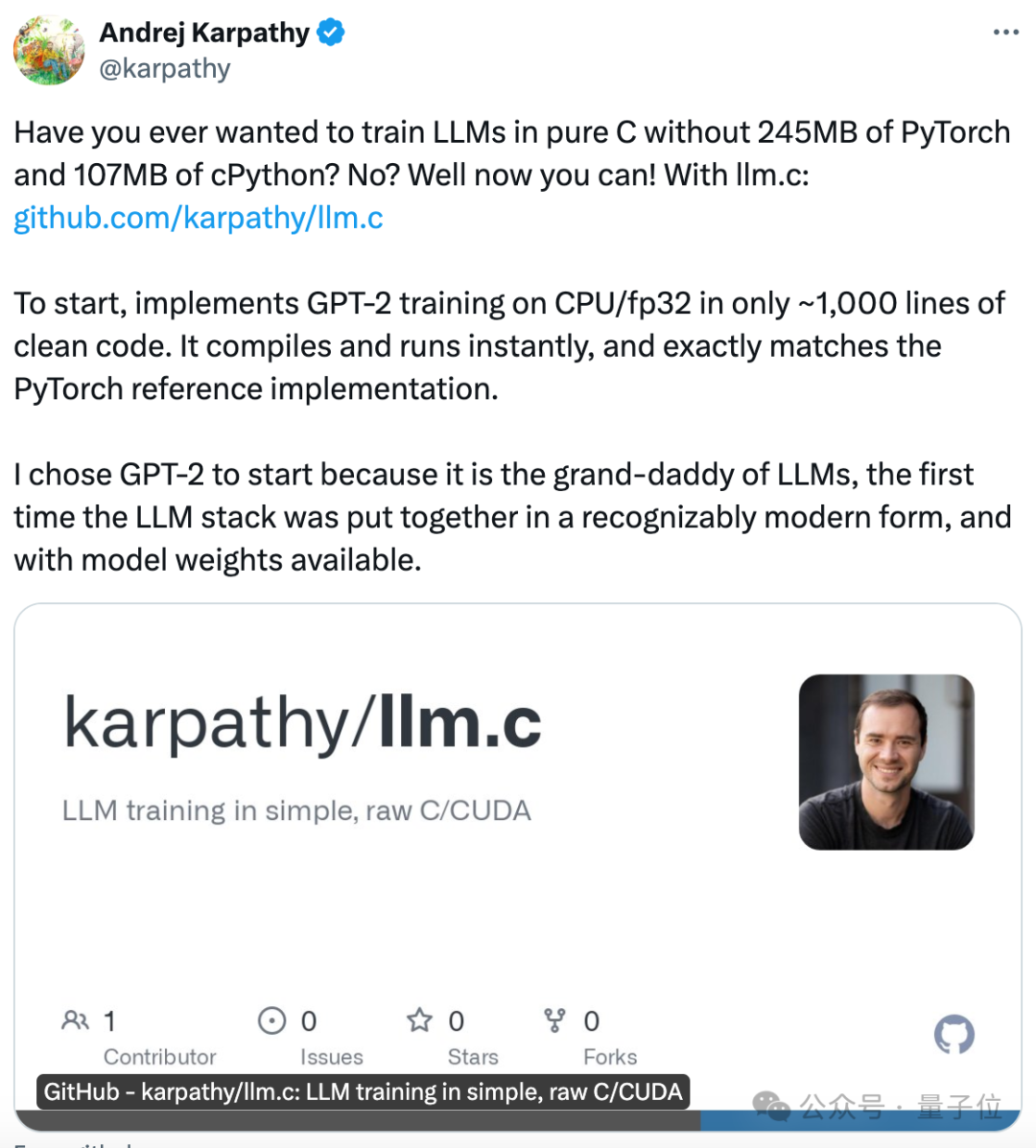
纯C语言训练GPT,1000行代码搞定!,不用现成的深度学习框架,纯手搓。 发布仅几个小时,已经揽星2.3k。

香港也有大模型公司了。 Weitu AI,一家全力打造多模态Native产品的公司
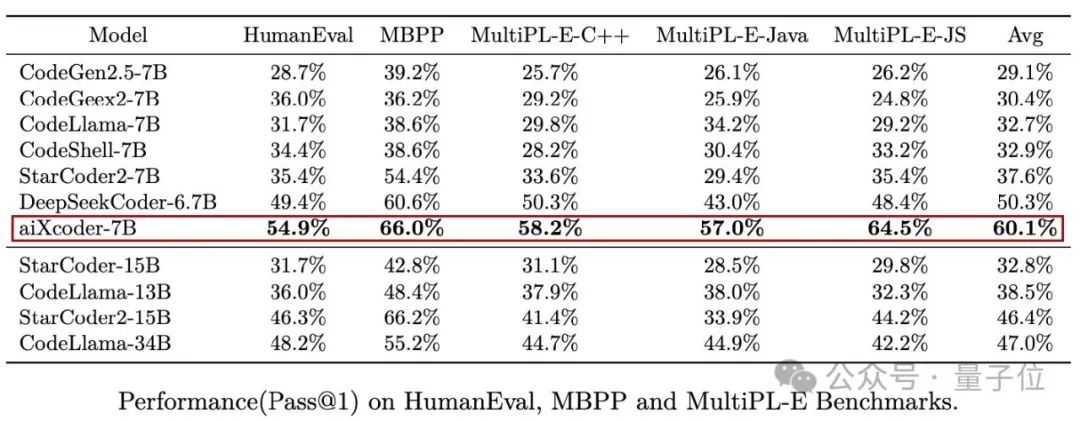
来自Meta、基于Llama2,可是开源界最先进的AI编程大模型之作
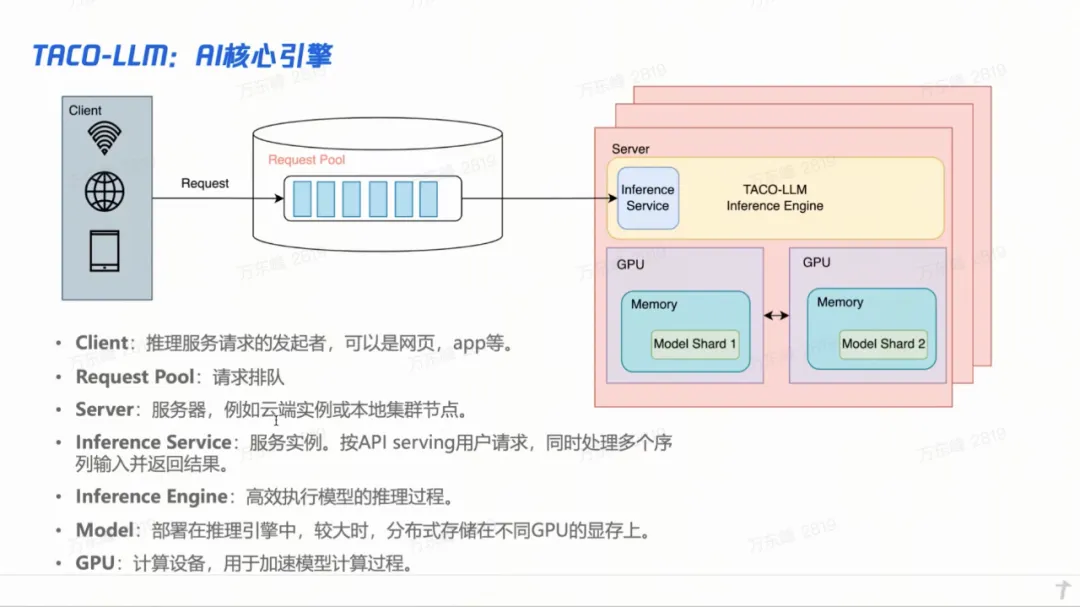
大模型在今年的落地,除了对用 AI 对已有业务进行改造和提效外,算力和推理的优化,可能是另外一项重要的实践了。这在腾讯的两个完全不同的业务上有着明显的体现。

近日,朱泽园 (Meta AI) 和李远志 (MBZUAI) 的最新研究《语言模型物理学 Part 3.3:知识的 Scaling Laws》用海量实验(50,000 条任务,总计 4,200,000 GPU 小时)总结了 12 条定律,为 LLM 在不同条件下的知识容量提供了较为精确的计量方法。