
每月都有重磅研究,2024全年值得一读的论文都在这了
每月都有重磅研究,2024全年值得一读的论文都在这了2024 年,是 AI 领域让人兴奋的一年。在这一年中,各大科技公司、机构发布了数不胜数的研究。
来自主题: AI技术研报
7801 点击 2025-01-01 17:18
2024 年,是 AI 领域让人兴奋的一年。在这一年中,各大科技公司、机构发布了数不胜数的研究。
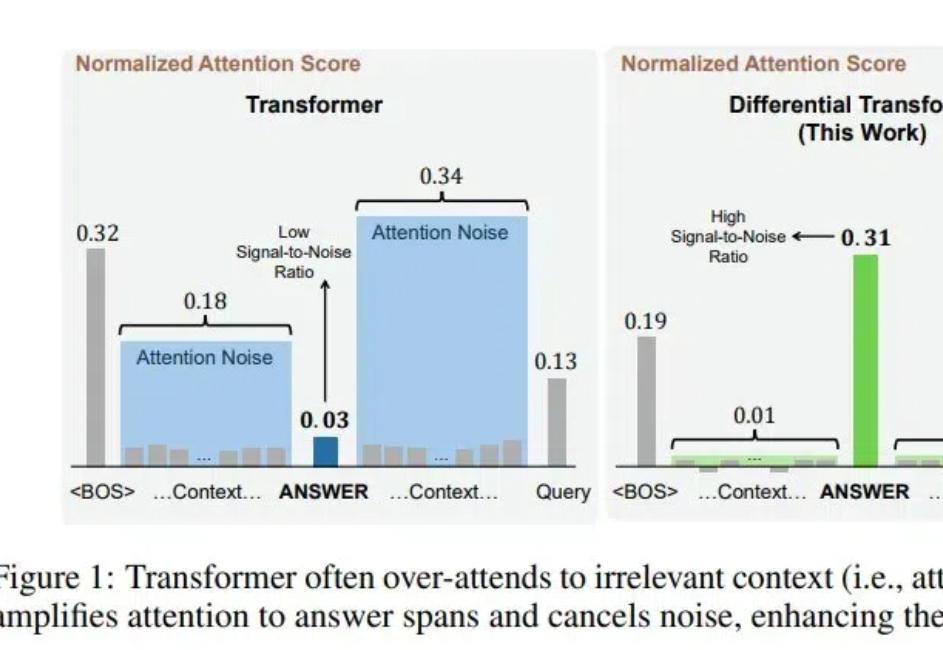
ViT核心作者Lucas Beyer,长文分析了一篇改进Transformer架构的论文,引起推荐围观。

多模态理解与生成一体化模型,致力于将视觉理解与生成能力融入同一框架,不仅推动了任务协同与泛化能力的突破,更重要的是,它代表着对类人智能(AGI)的一种深层探索。

平面设计是一门艺术学科,它们致力于创造一些吸引注意力和有效传达信息的视觉内容。为了减轻人类设计师的负担,各种各样的海报生成模型相继被提出。它们只关注某些子任务,远未实现设计构图任务;它们在生成过程中不考虑图形设计的层次信息。为了解决这些问题,作者将分层设计原理引入多模态模型(LMM),并提出LaDeCo算法。

苹果要搞人形机器人这事儿现在传得沸沸扬扬。 最近他们确实有新动作——开发了一套机器人感知系统! 系统名为ARMOR,软硬件协同增强机器人的“空间意识”,能动态防碰撞的那种。

只需一张图,就能生成高质量、广范围的3D场景! 泰迪熊、花园、山谷都从平面图片变成了仿佛触手可及的立体物品。

你是否想过在自己的设备上运行自己的大型语言模型(LLMs)或视觉语言模型(VLMs)?你可能有过这样的想法,但是一想到要从头开始设置、管理环境、下载正确的模型权重,以及你的设备是否能处理这些模型的不确定性,你可能就犹豫了。

事情是这样的,我今天刷信息流的时候注意到,蚂蚁集团今天发布了 2024 科技生态白皮书,展示了他们在论文、专利、开源、标准、产学研等几个方面的进展。

视觉价值模型(VisVM)通过「推理时搜索」来提升多模态视觉语言模型的图像描述质量,减少幻觉现象。实验表明,VisVM能显著提高模型的视觉理解能力,并可通过自我训练进一步提升性能。
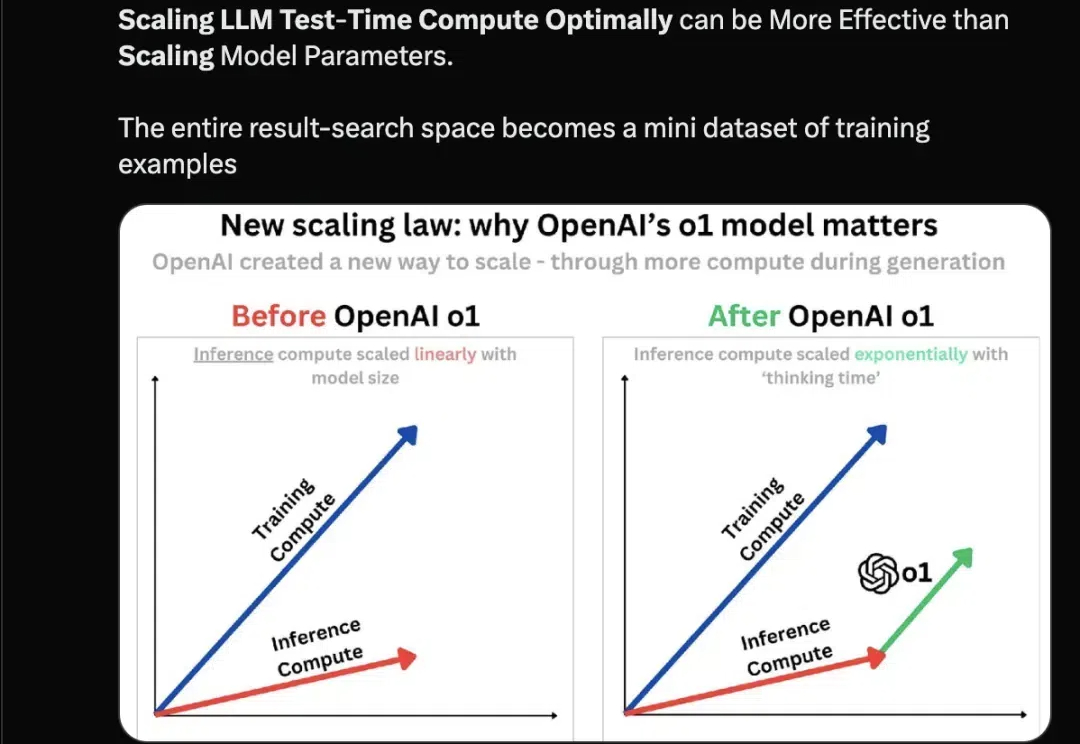
随着 o1、o1 Pro 和 o3 的成功发布,我们明显看到,推理所需的时间和计算资源逐步上升。可以说,o1 的最大贡献在于它揭示了提升模型效果的另一种途径:在推理过程中,通过优化计算资源的配置,可能比单纯扩展模型参数更为高效。

港科大团队重磅开源 VideoVAE+,提出了一种强大的跨模态的视频变分自编码器(Video VAE),通过提出新的时空分离的压缩机制和创新性引入文本指导,实现了对大幅运动视频的高效压缩与精准重建,同时保持很好的时间一致性和运动恢复。
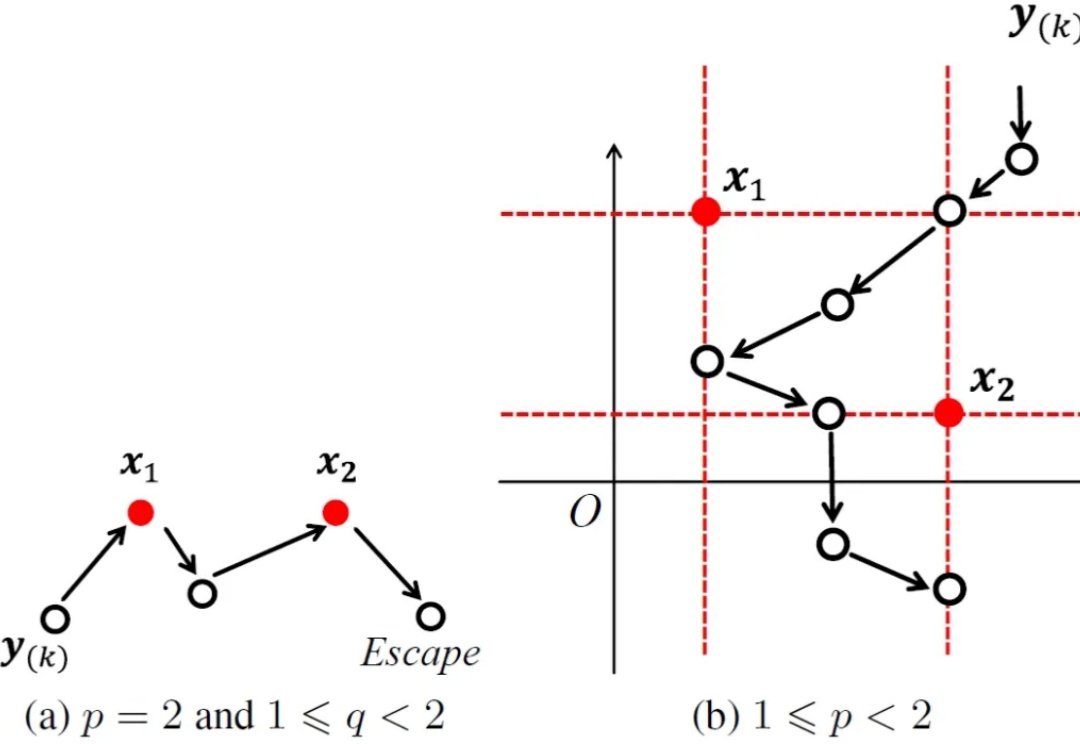
韦伯区位问题源自一个经典的运筹优化问题,它首先由著名数学家皮耶・德・费马提出,后被著名经济学家阿尔弗雷德・韦伯(著名社会学家马克斯・韦伯的弟弟)扩展,在机器学习、人工智能、金融工程及计算机视觉等众多领域均有广泛应用。
大模型的的发布固然令人欣喜,但是各类测评也是忙坏了众多 AI 工作者。大模型推理的幻觉问题向来是 AI 测评的重灾区,诸如 9.9>9.11 的经典幻觉问题,各大厂家恨不得直接把问题用 if-else 写进来。

在人工智能领域,大语言模型(LLM)的应用已经渗透到创意写作的方方面面。

大模型时代,全世界AI从业者追赶OpenAI GPT系列的脚步仍未停歇,但也有人,坚持深耕在国产原创的另一条大模型之路上。
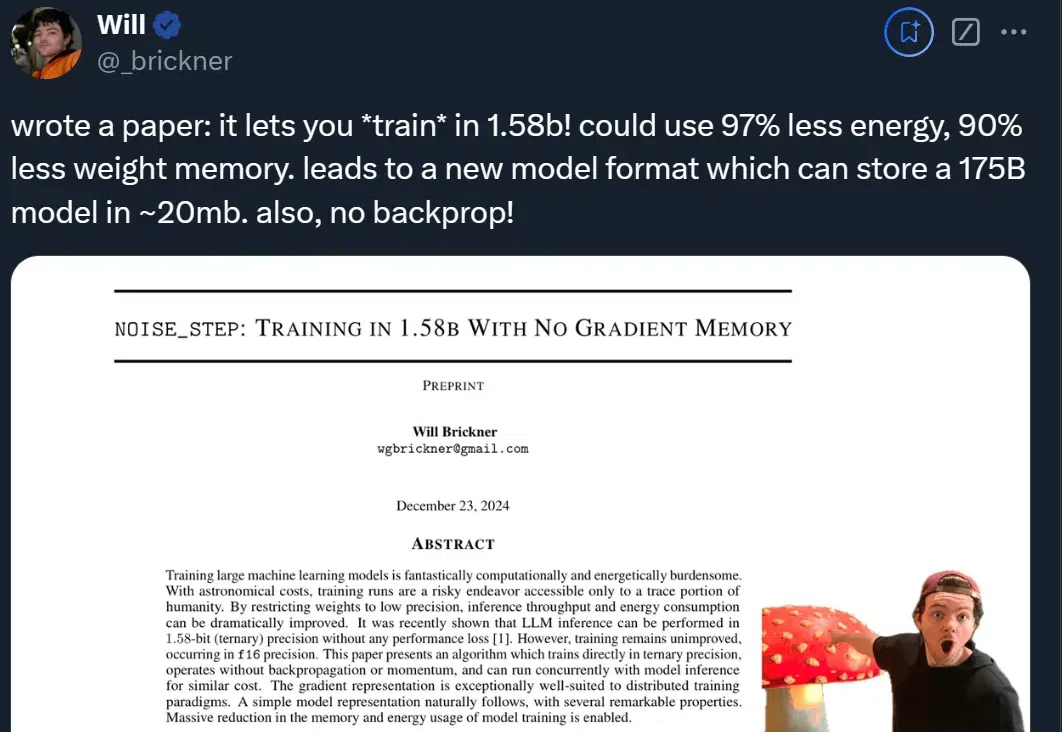
好家伙!1750亿参数的GPT-3只需20MB存储空间了?! 基于1.58-bit训练,在不损失精度的情况下,大幅节省算力(↓97%)和存储(↓90%)。
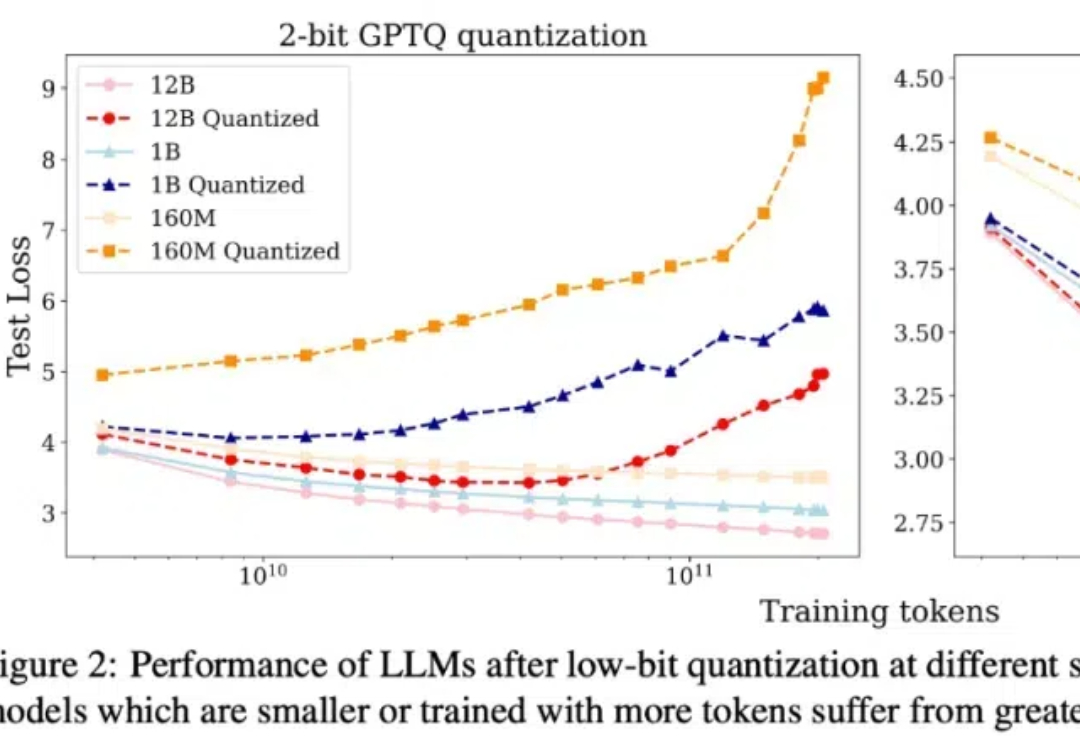
本文介绍了一套针对于低比特量化的 scaling laws。
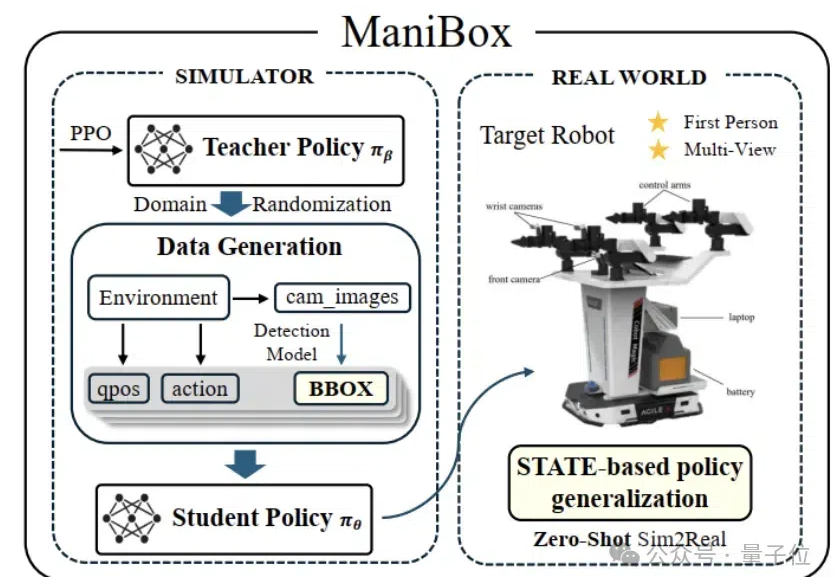
在机器人空间泛化领域,原来也有一套Scaling Law! 来自清华和新加坡国立大学的团队,发现了空间智能的泛化性规律。 在此基础上,他们提出了一套新颖的算法框架——ManiBox,让机器人能够在真实世界中应对多样化的物体位置和复杂的场景布置。
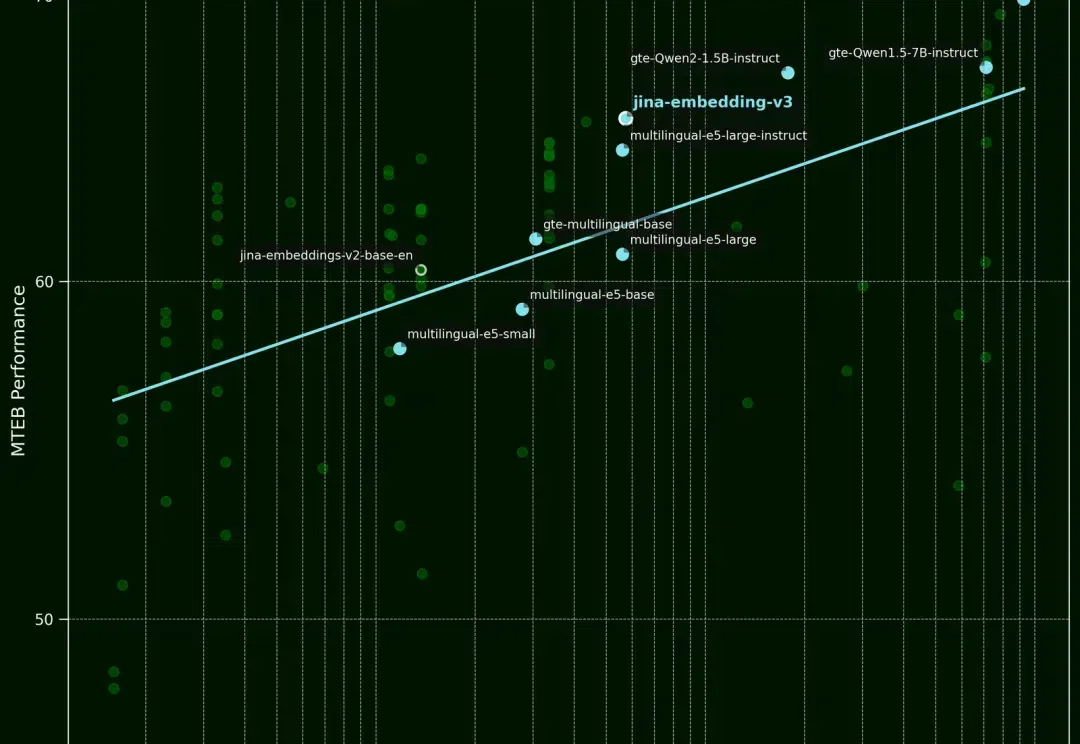
最近,LAION AI 的创始人 Christoph Schuhmann 分享了一个有趣的发现,他指出,文本向量模型似乎存在一个问题:即使句子词序被打乱,模型输出的向量与原句仍然高度相似。

1637 年,费马在阅读丢番图《算术》拉丁文译本时,曾在第 11 卷第 8 命题旁写道:「将一个立方数分成两个立方数之和,或一个四次幂分成两个四次幂之和,或者一般地将一个高于二次的幂分成两个同次幂之和,这是不可能的。关于此,我确信我发现一种美妙的证法,可惜这里的空白处太小,写不下。」
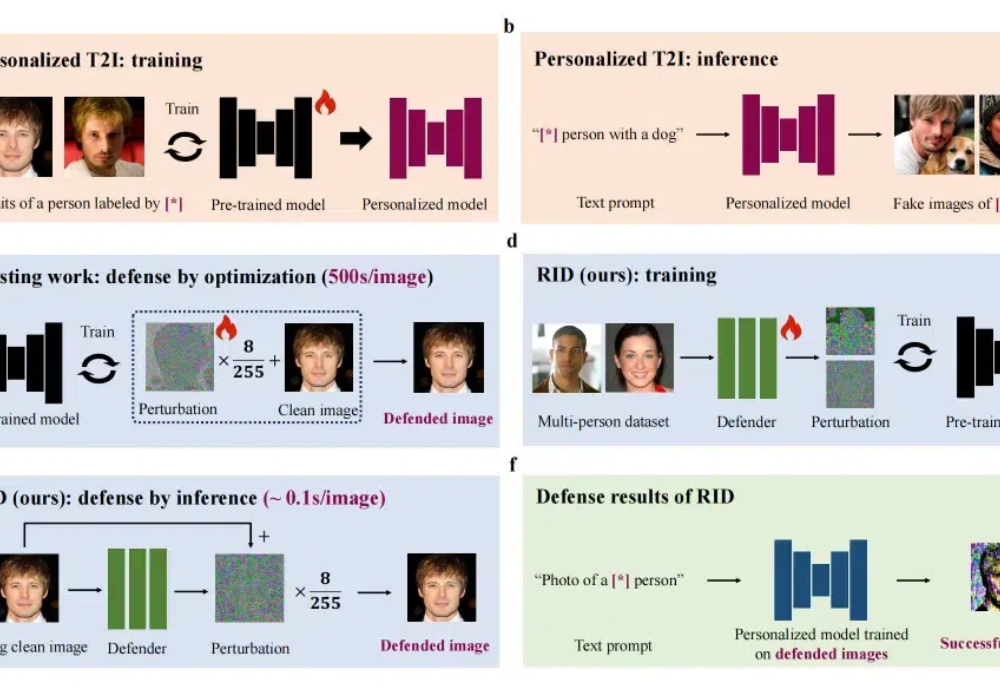
近年来许多论文研究了基于扩散模型的定制化生成,即通过给定一张或几张某个概念的图片,通过定制化学习让模型记住这个概念,并能够生成这个概念的新视角、新场景图片。
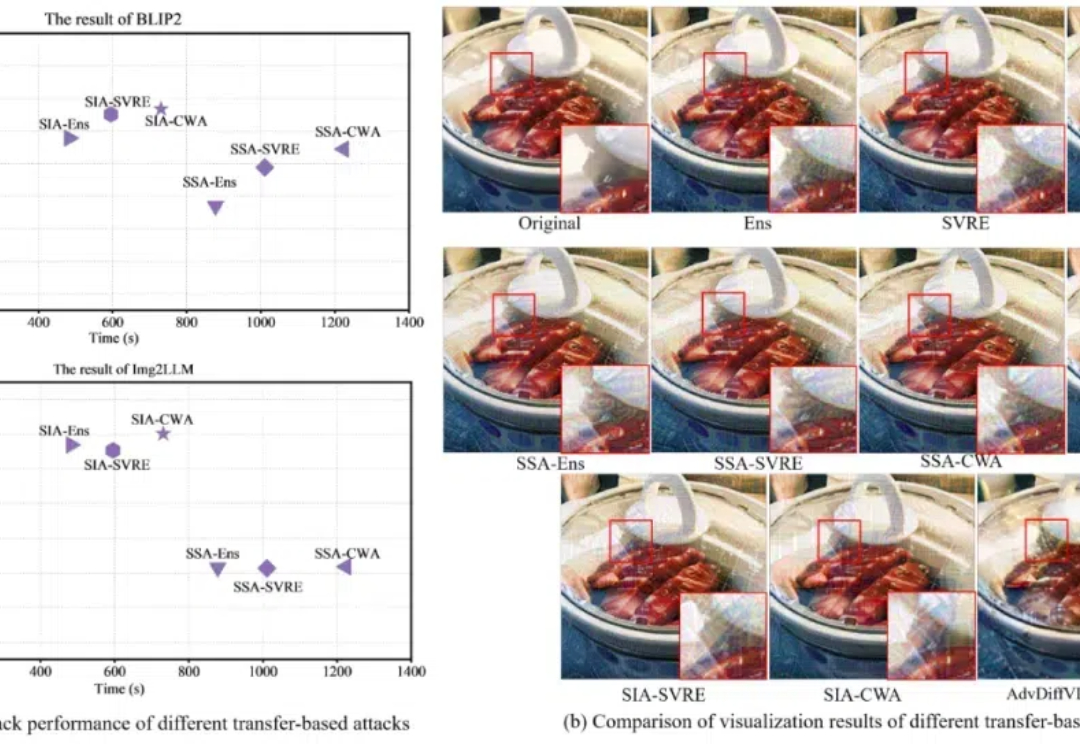
对抗攻击,特别是基于迁移的有目标攻击,可以用于评估大型视觉语言模型(VLMs)的对抗鲁棒性,从而在部署前更全面地检查潜在的安全漏洞。然而,现有的基于迁移的对抗攻击由于需要大量迭代和复杂的方法结构,导致成本较高

超越ControlNet++,让文生图更可控的新框架来了!

本月,OpenAI科学家就当前LLM的scaling方法论能否实现AGI话题展开深入辩论,认为将来AI至少与人类平分秋色;LLM scaling目前的问题可以通过后训练、强化学习、合成数据、智能体协作等方法得到解决;按现在的趋势估计,明年LLM就能赢得IMO金牌。

Orr Zohar的指导老师Serena Yeung-Levy教授于2018年获得斯坦福大学博士学位,师从李飞飞和Arnold Milstein。2017年至2019年期间,Serena Yeung-Levy曾与Justin Johnson和李飞飞共同教授斯坦福大学卷积神经网络课程。

一个全新的模型能力衡量指标诞生了?!

数字生命一直是人类几十年来的追求,反映了我们对技术与人类体验交汇的深层探索。近期,复旦大学发表了一篇综述论文,首次系统梳理了角色扮演AI(Role-Playing Language Agents,RPLAs)的研究现状,现已被机器学习顶级期刊TMLR接收。
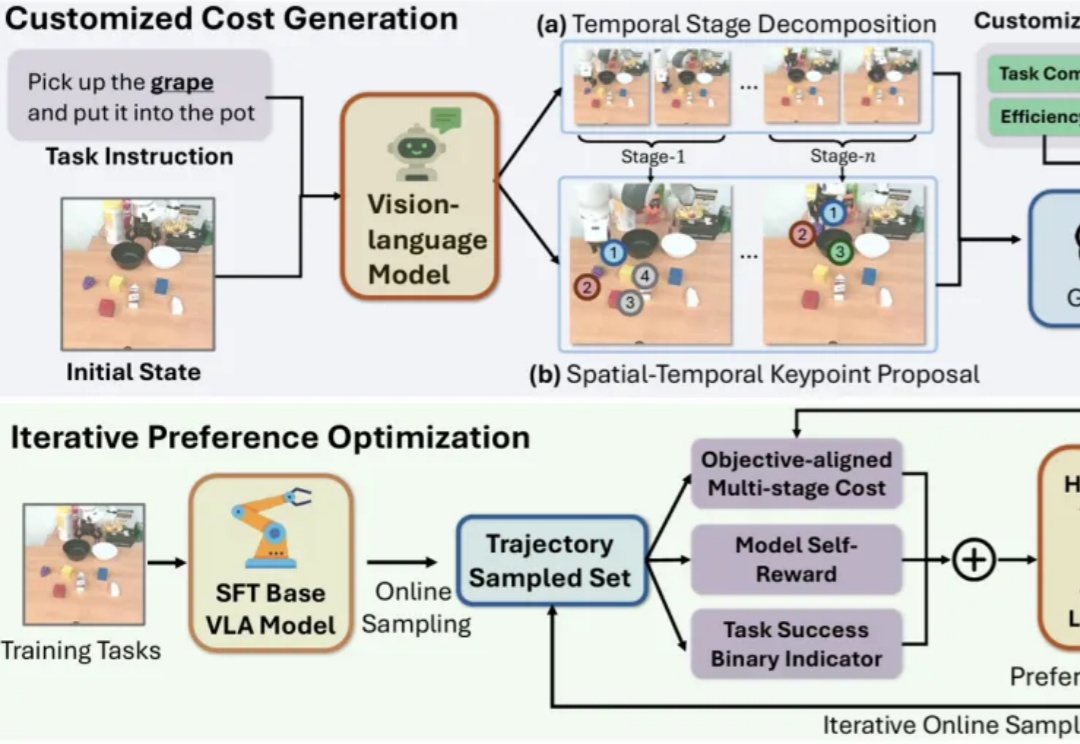
近年来,视觉-语言-动作模型(Vision-Language-Action, VLA)在诸多机器人任务上取得了显著的进展,但它们仍面临一些关键问题,例如由于仅依赖从成功的执行轨迹中进行行为克隆,导致对新任务的泛化能力较差。
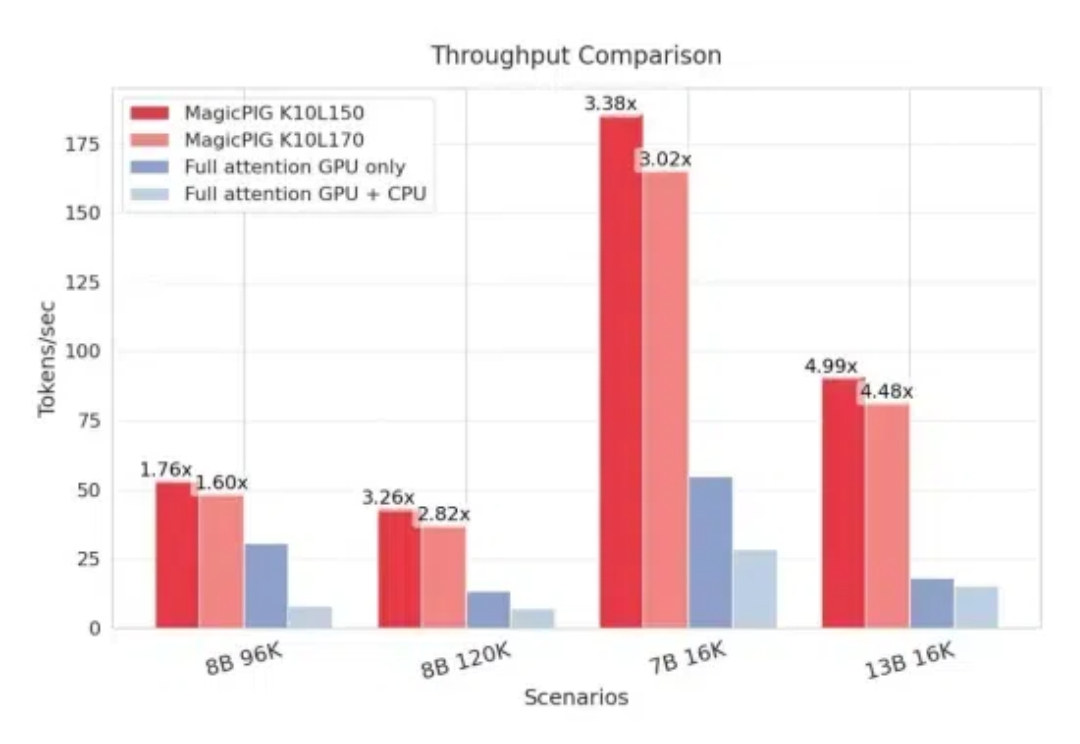
CPU+GPU,模型KV缓存压力被缓解了。 来自CMU、华盛顿大学、Meta AI的研究人员提出MagicPIG,通过在CPU上使用LSH(局部敏感哈希)采样技术,有效克服了GPU内存容量限制的问题。
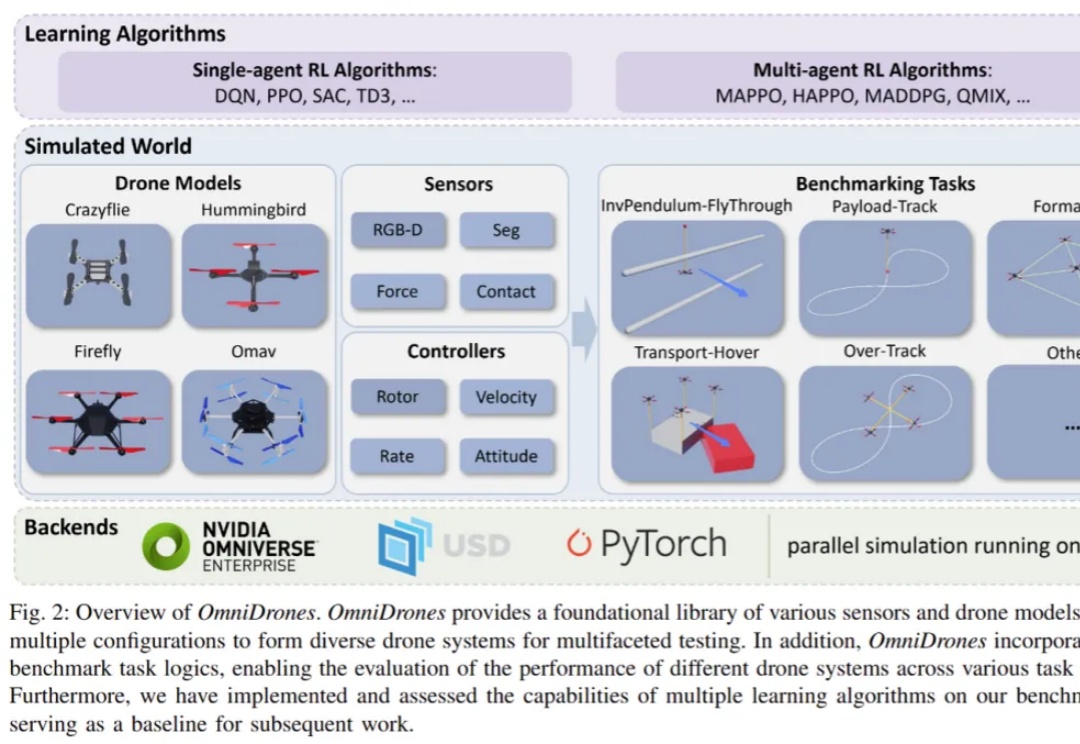
控制无人机执行敏捷、高机动性的行为是一项颇具挑战的任务。传统的控制方法,比如 PID 控制器和模型预测控制(MPC),在灵活性和效果上往往有所局限。而近年来,强化学习(RL)在机器人控制领域展现出了巨大的潜力。通过直接将观测映射为动作,强化学习能够减少对系统动力学模型的依赖。