

历时2年,华人团队力作,震撼开源生成式物理引擎Genesis,可模拟世界万物
历时2年,华人团队力作,震撼开源生成式物理引擎Genesis,可模拟世界万物这是生成式大模型的时代 —— 它们能生成文本、图像、音频、视频、3D 对象…… 而如果将所有这些组合到一起,我们可能会得到一个世界!
来自主题: AI技术研报
6826 点击 2024-12-19 15:26
这是生成式大模型的时代 —— 它们能生成文本、图像、音频、视频、3D 对象…… 而如果将所有这些组合到一起,我们可能会得到一个世界!

针对大语言模型的推理任务,近日,Meta田渊栋团队提出了一个新的范式:连续思维链,对比传统的CoT,性能更强,效率更高。

大语言模型(LLM)在自然语言处理领域取得了巨大突破,但在复杂推理任务上仍面临着显著挑战。现有的Chain-of-Thought(CoT)和Tree-of-Thought(ToT)等方法虽然通过分解问题或结构化提示来增强推理能力,但它们通常只进行单次推理过程,无法修正错误的推理路径,这严重限制了推理的准确性。
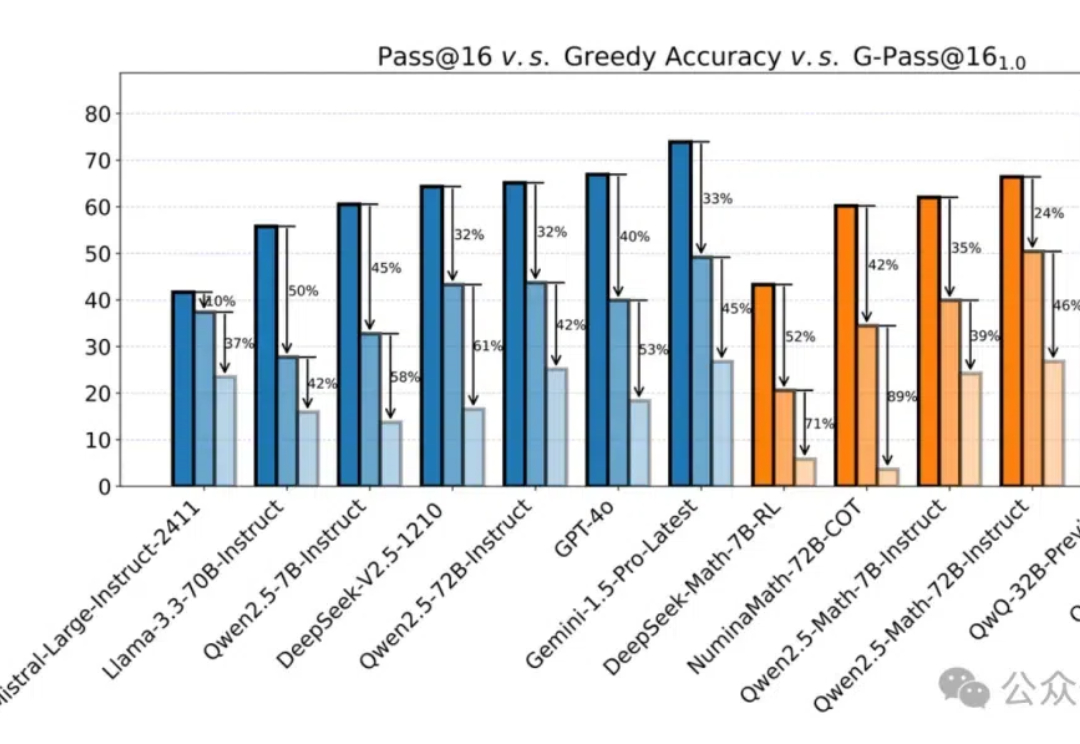
新模型在MATH上(以数学竞赛为主)动辄跑分80%甚至90%以上,却一用就废。
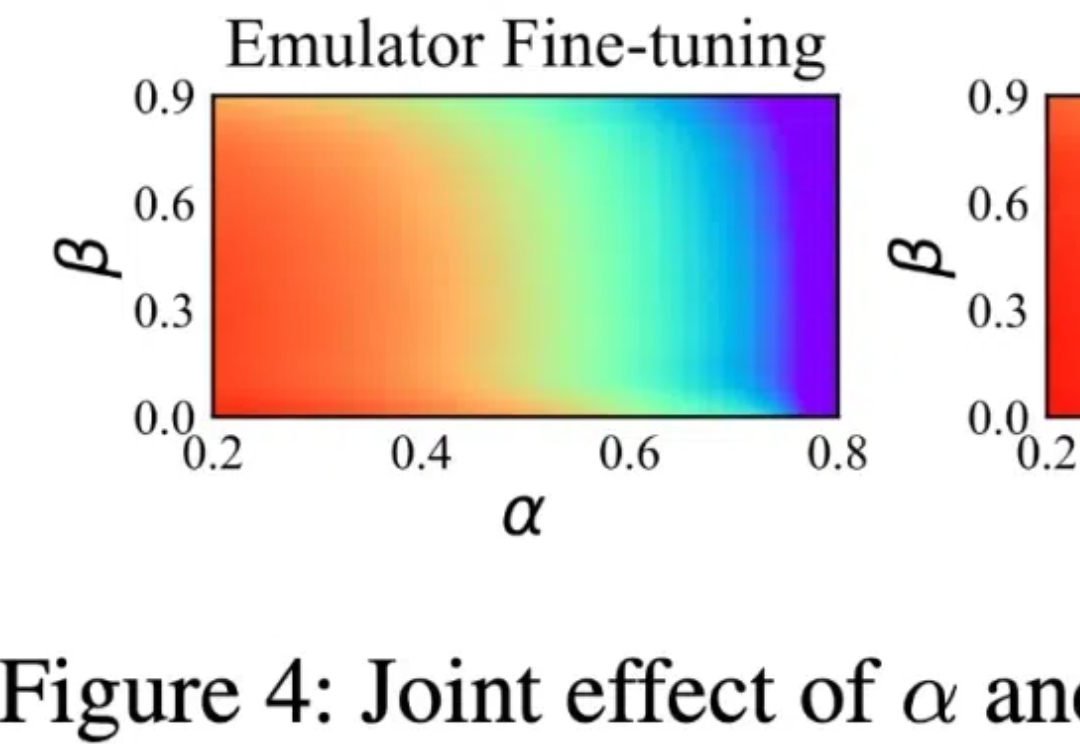
要让大模型适应各不一样的下游任务,微调必不可少。常规的中心化微调过程需要模型和数据存在于同一位置 —— 要么需要数据所有者上传数据(这会威胁到数据所有者的数据隐私),要么模型所有者需要共享模型权重(这又可能泄露自己花费大量资源训练的模型)。

AI真是助力科研的神器,不光能用大模型提升写作效率,跟AI技术沾边的论文中顶刊的概率也会增加,升职速度也会提升;但对于科学界来说,大家都一股脑去研究AI,那些不能用AI的领域受到了冷落,最终导致整体科研多样性下降。

清华大学与国家蛋白质科学中心的最新成果,结合了稳定学习的理论,提出了一个面向多中心、大队列异质数据的「稳定」生存分析方法。
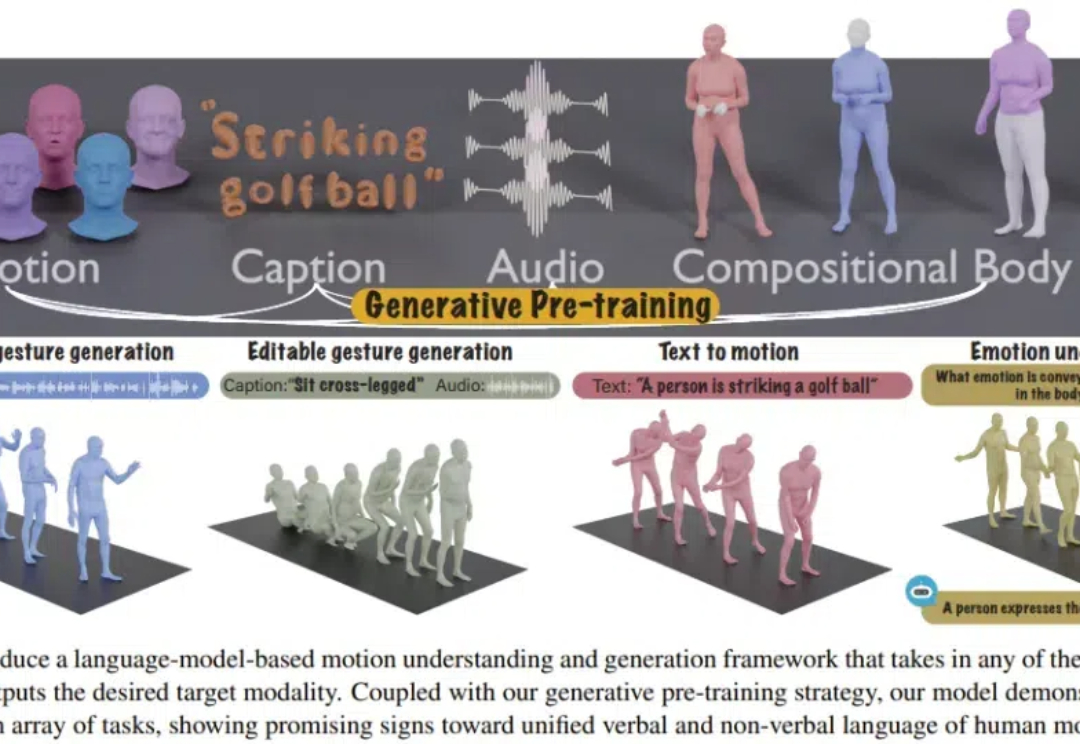
人类的沟通交流充满了多模态的信息。为了与他人进行有效沟通,我们既使用言语语言,也使用身体语言,比如手势、面部表情、身体姿势和情绪表达。
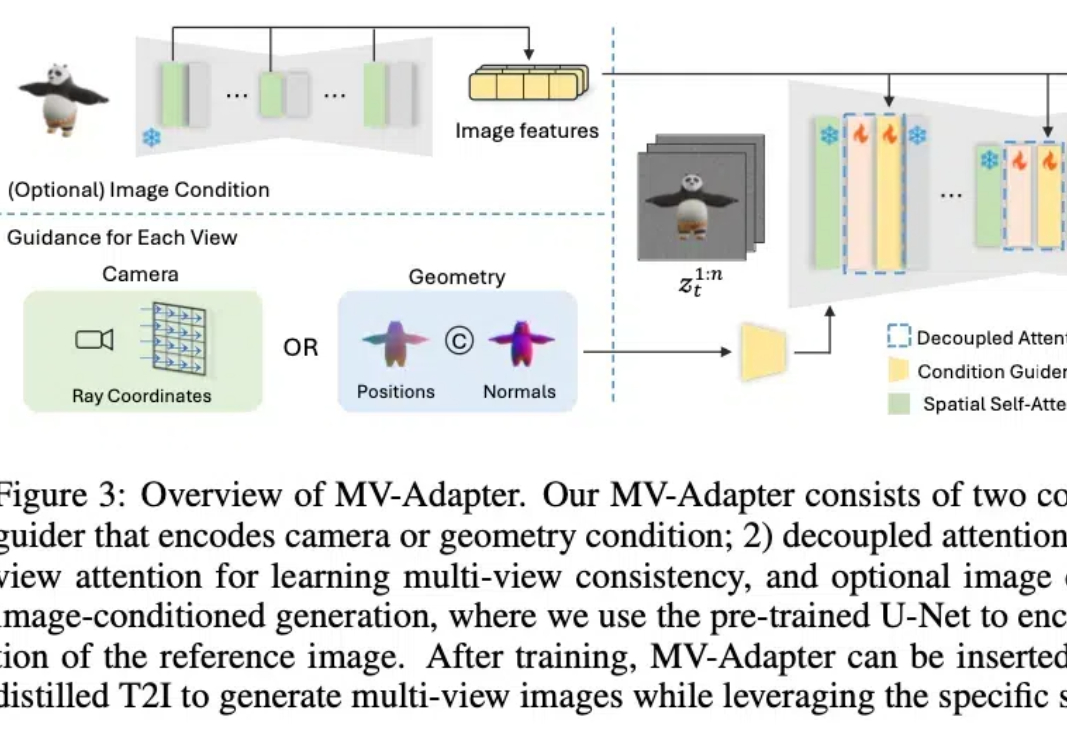
最近,2D/3D 内容创作、世界模型(World Models)似乎成为 AI 领域的热门关键词。作为计算机视觉的基础任务之一,多视角图像生成是上述热点方向的技术基础,在 3D 场景生成、虚拟现实、具身感知与仿真、自动驾驶等领域展现了广泛的应用潜力。
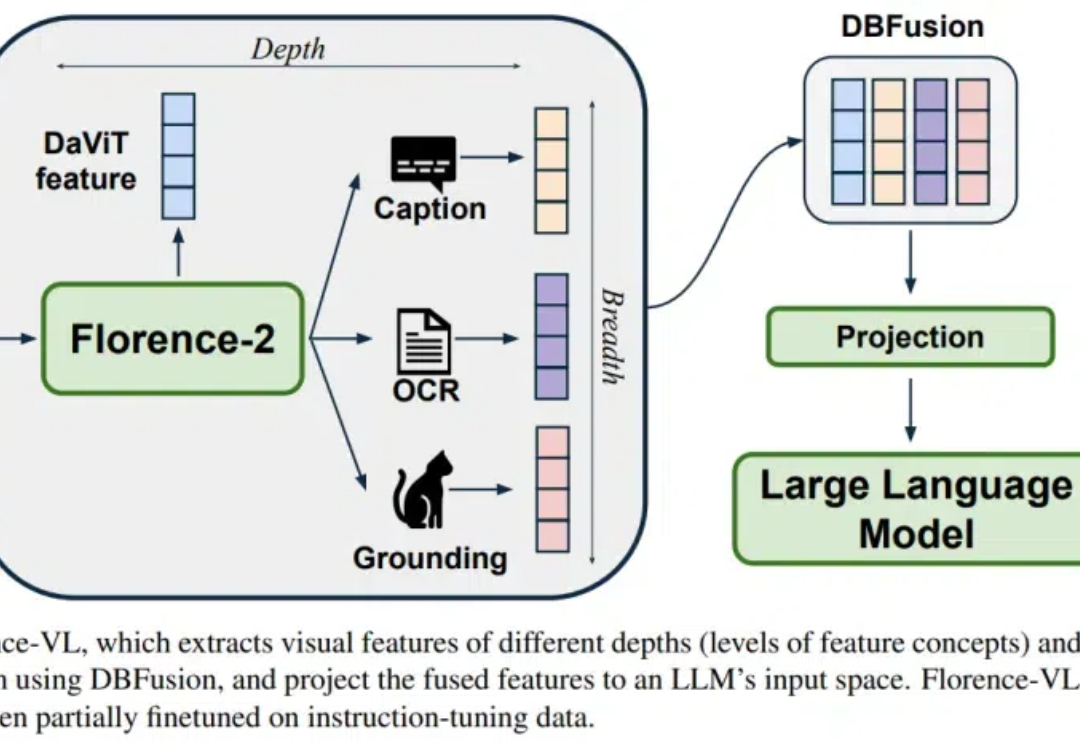
Florence-VL 提出了使用生成式视觉编码器 Florence-2 作为多模态模型的视觉信息输入,克服了传统视觉编码器(如 CLIP)仅提供单一视觉表征而往往忽略图片中关键的局部信息。
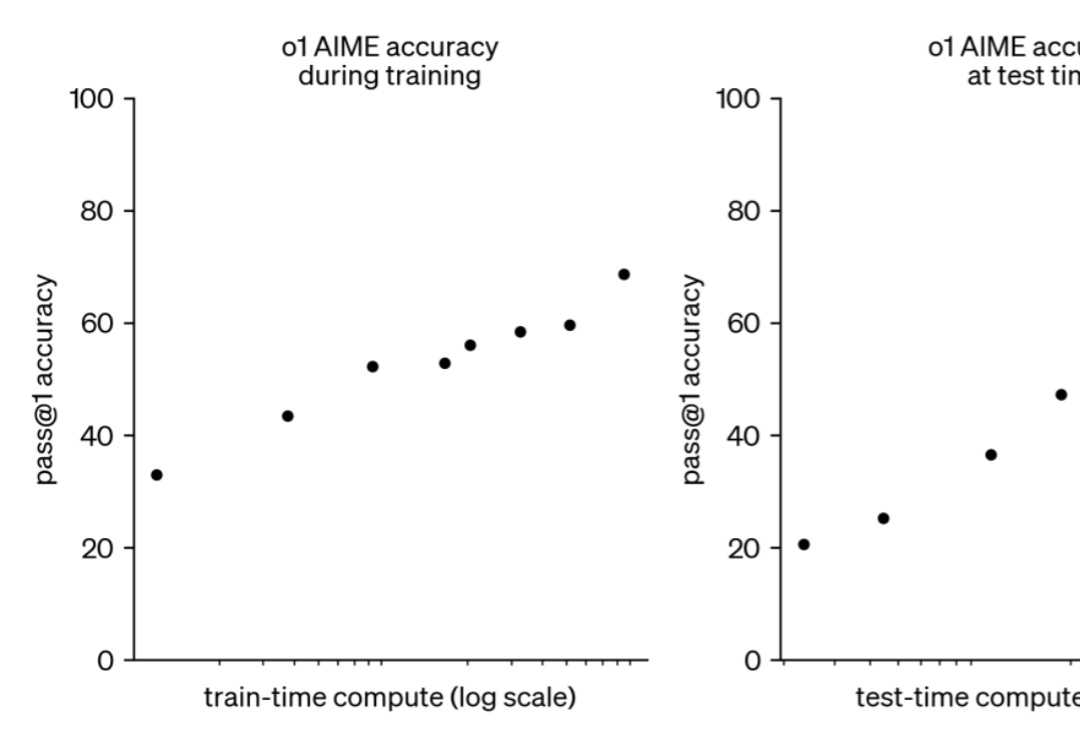
如果给小模型更长的思考时间,它们性能可以超越更大规模的模型。

现如今,以 GPT 为代表的大语言模型正深刻影响人们的生产与生活,但在处理很多专业性和复杂程度较高的问题时仍然面临挑战。在诸如药物发现、自动驾驶等复杂场景中,AI 的自主决策能力是解决问题的关键,而如何进行决策大模型的高效训练目前仍然是开放性的难题。

LLM 强大的语言能力,使其被广泛部署于 LLM 应用系统(LLM-integrated applications)中。此时,LLM 需要访问外部数据(如文件,网页,API 返回值)来完成任务。
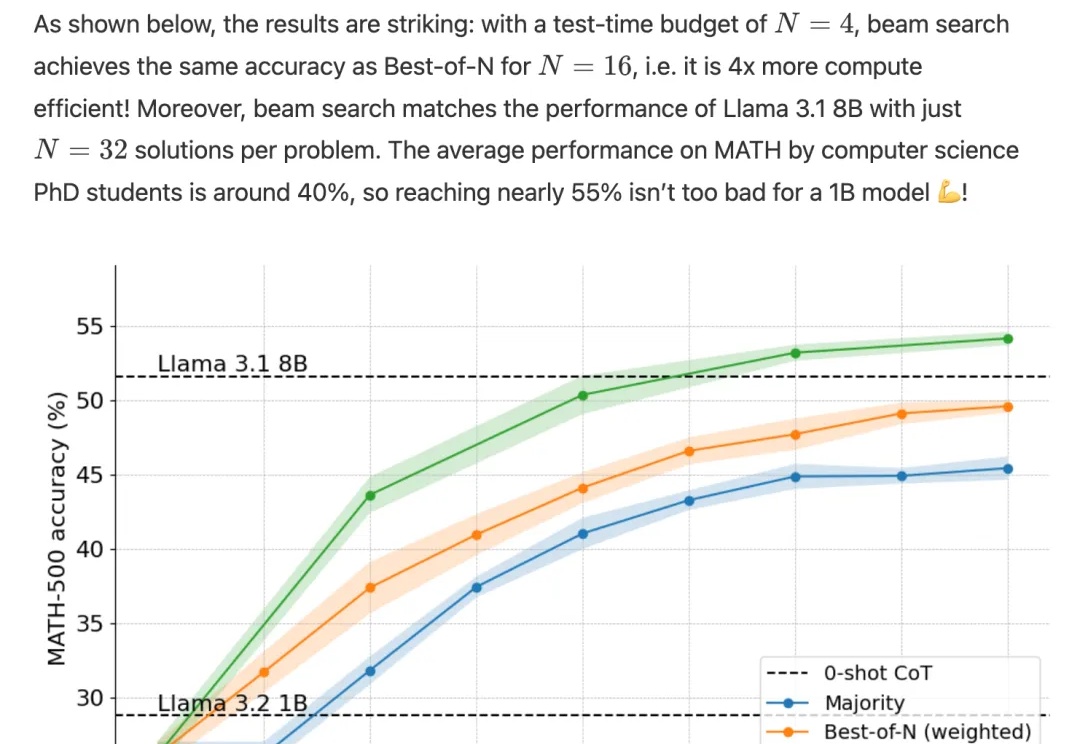
o1完整版公开仅10天,Scaling Law新范式就被逆向工程复现了!

BLT 在许多基准测试中超越了基于 token 的架构。
多模态大模型内嵌语言模型总是出现灾难性遗忘怎么办?
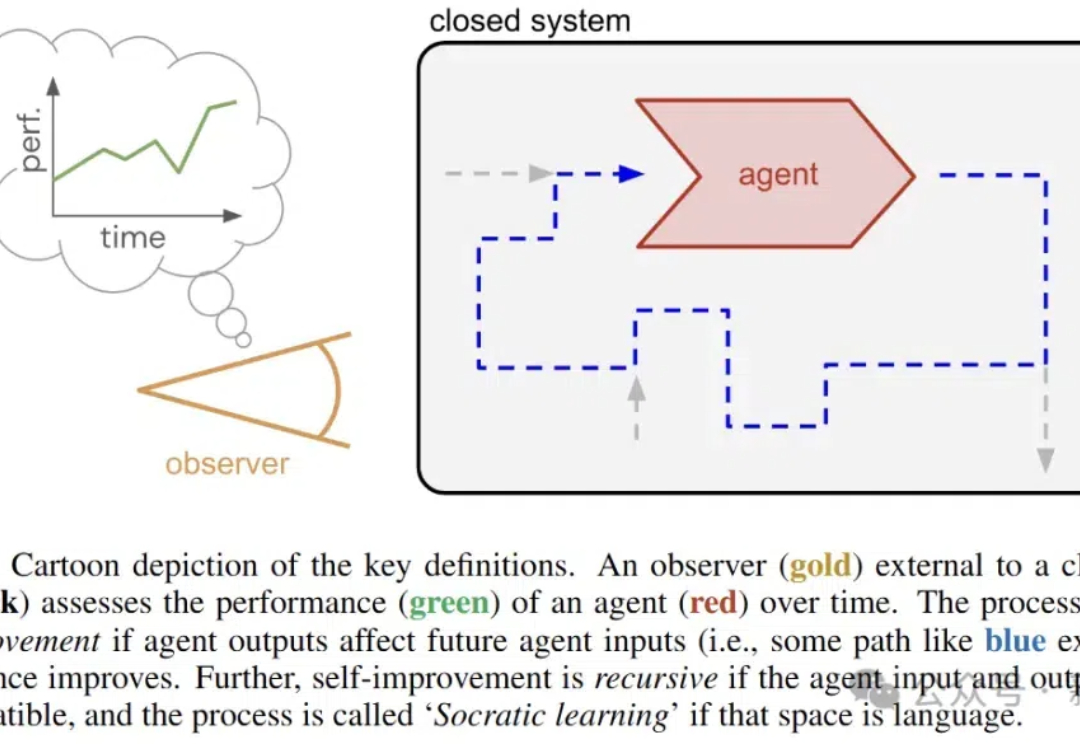
近日,谷歌DeepMind的研究人员推出了苏格拉底式学习,在没有外部数据的情况下,让AI通过语言游戏不断变强。
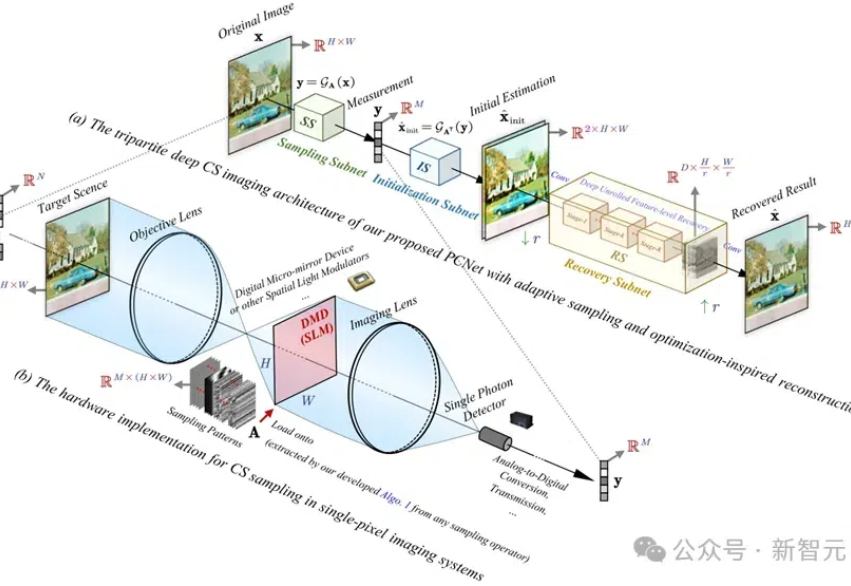
PCNet网络具有创新的协同采样算子和优化的重建网络,实验结果证明,其在图像重建精度、计算效率和任务扩展性方面均优于现有方法,为高分辨率图像的压缩感知提供了新的解决方案。
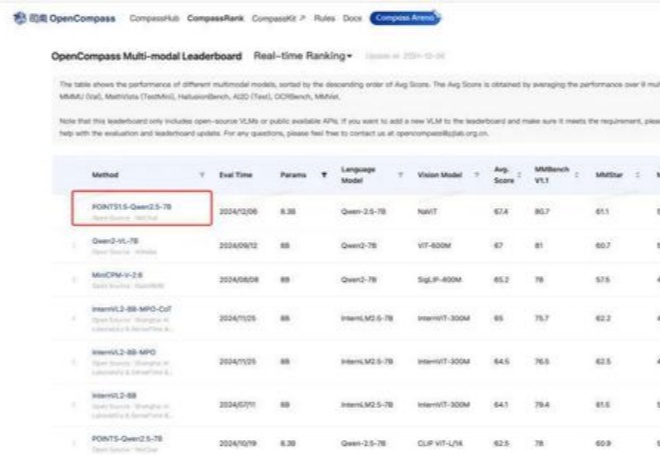
距离 POINT1.0 的发布已经过去两个月时间来,在这段时间业界不断涌现出一系列优秀的模型。我们通过不断紧跟前沿技术,并结合过去开发多模态模型沉淀下来的经验,对 POINTS1.0 进行了一系列更新,推出了 POINTS1.5。

DeepMind的研究人员开发了一种视频分层新方法,可以无需假设背景静止或精确的相机姿态,就能将视频分解成包含物体及其效果(如阴影和反射)的多个层,提升了视频编辑的灵活性和效率。
基于昇腾算力的矩阵运算改进求解器框架,大幅提升Local Optimum跳出能力。
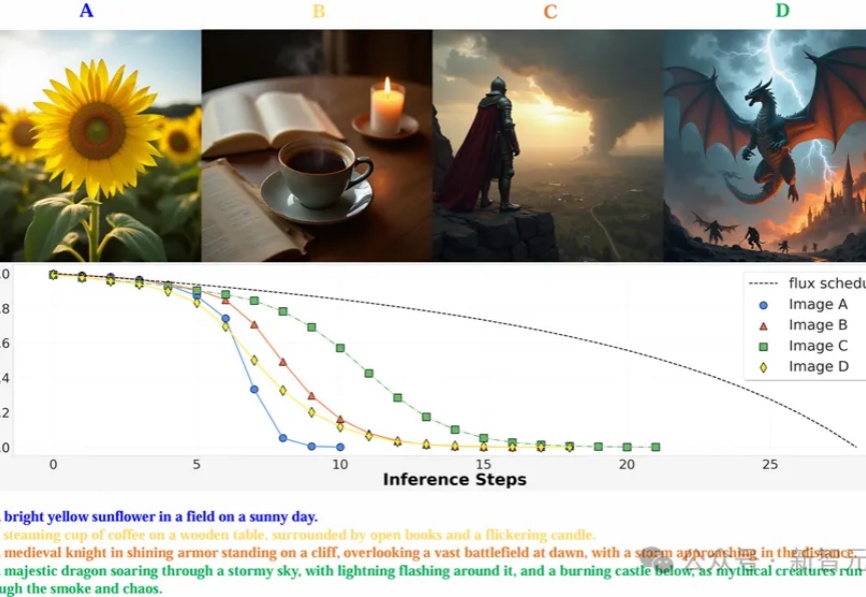
MAPLE实验室提出通过强化学习优化图像生成模型的去噪过程,使其能以更少的步骤生成高质量图像,在多个图像生成模型上实现了减少推理步骤,还能提高图像质量。

这几天,学术圈的小伙伴肯定都很关注正在加拿大温哥华举办的机器学习顶会——NeurIPS 2024。本届会议于今日落下帷幕,共接收 15671 篇有效论文投稿,比去年增长了 27%,最终接收率为 25.8%。
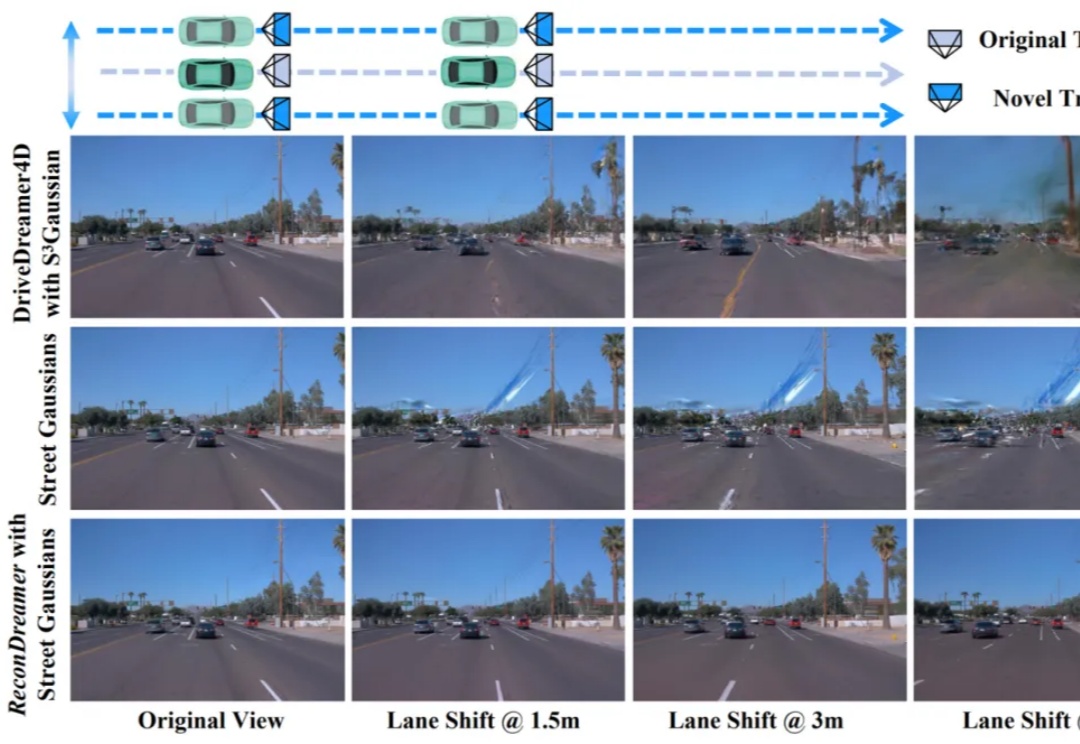
人工智能技术正以前所未有的速度改变着我们对世界的认知与构建方式。近期,李飞飞教授团队通过单张图片生成三维物理世界的研究,再次向世界展示了空间智能技术的巨大潜力。
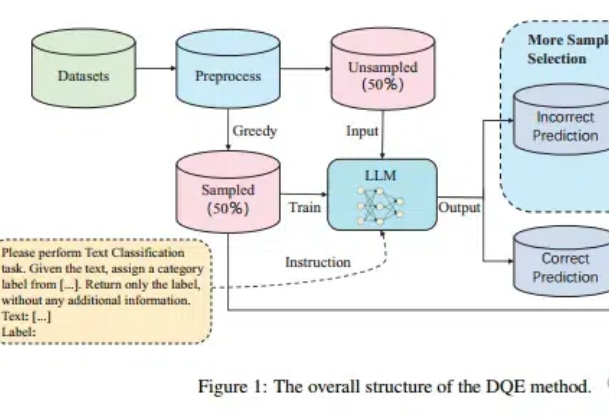
Scaling Law不仅在放缓,而且不一定总是适用! 尤其在文本分类任务中,扩大训练集的数据量可能会带来更严重的数据冲突和数据冗余。
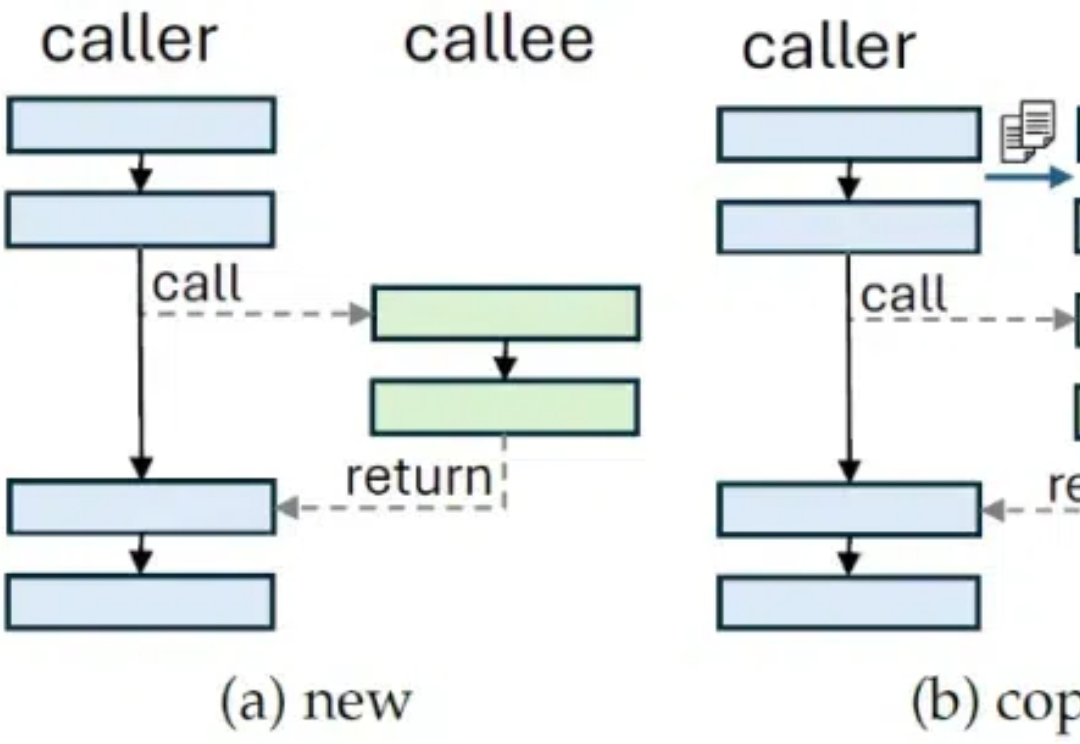
在人工智能快速发展的今天,大语言模型(LLM)已经成为改变世界的重要力量。然而,如何高效地编写、管理和维护提示词(Prompt)仍然是一个巨大的挑战。
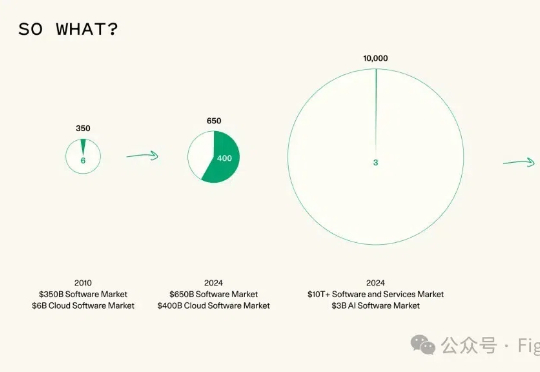
Sequoia Capital(红杉资本) 最近发表了一篇文章《AI in 2025: Building Blocks Firmly in Place》,对2025年的AI发展趋势做了三个预测,一定程度上反映了资本对于大模型方向一些定性判断。
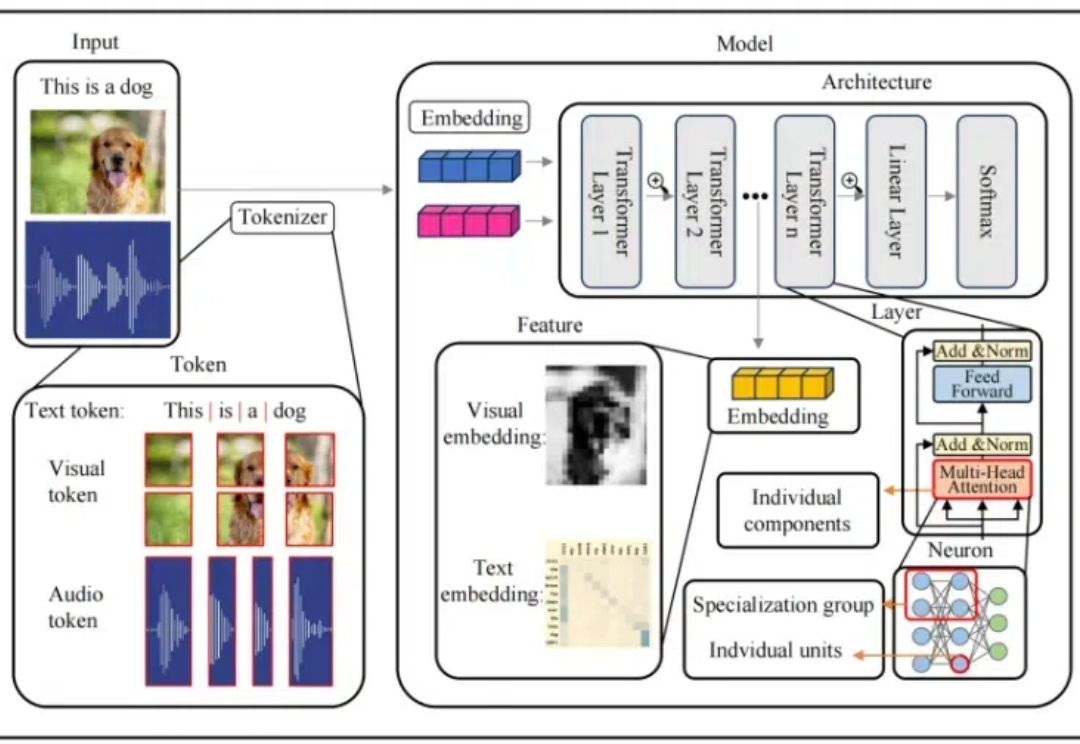
本文介绍了首个多模态大模型(MLLM)可解释性综述

全网独一份o1 pro架构爆料来了!首创自洽性机制打破推理极限,「草莓训练」系统首次揭秘。更令人震惊的是,OpenAI和Anthropic自留Orion、Claude 3.5超大杯,并不是内部失败了,而是它们成为数据生成的秘密武器。
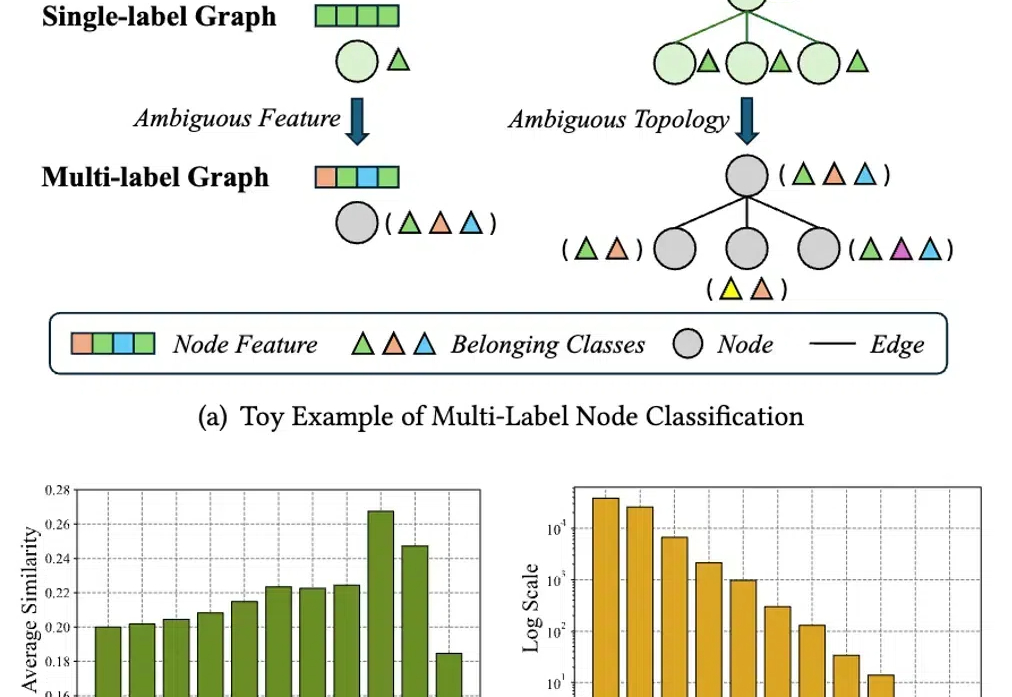
ACM SIGKDD(简称 KDD)始于 1989 年,是全球数据挖掘领域历史最悠久、规模最大的国际顶级学术会议。KDD 2025 将于 2025 年 8 月 3 日在加拿大多伦多举办。