

当谣言搭上“AI”的东风
当谣言搭上“AI”的东风标识能否有效应对?
来自主题: AI技术研报
6291 点击 2025-06-13 10:42
标识能否有效应对?
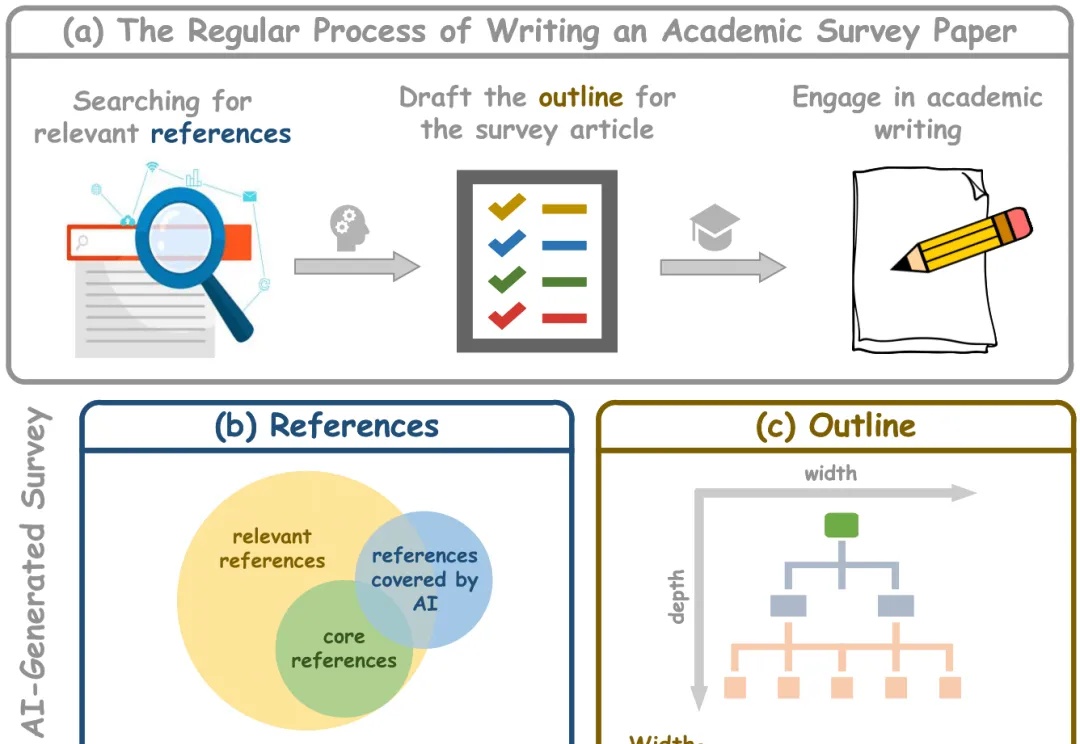
学术综述论文在科学研究中发挥着至关重要的作用,特别是在研究文献快速增长的时代。传统的人工驱动综述写作需要研究者审阅大量文章,既耗时又难以跟上最新进展。而现有的自动化综述生成方法面临诸多挑战:

谷歌DeepMind重磅出击,开源首个形式化数学猜想库,获陶哲轩力挺!从解析数论的兰道猜想开始,这个开源项目将为AI破解数学难题的未来铺路。
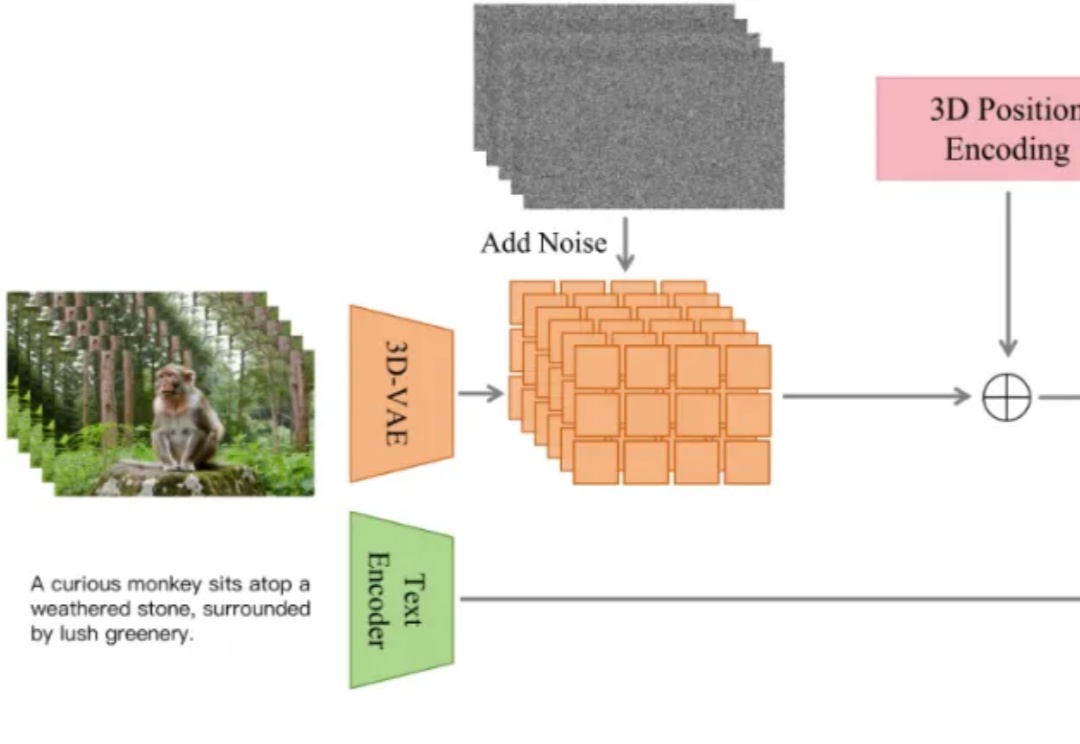
近日,抖音内容技术团队开源了 ContentV,一种面向视频生成任务的高效训练方案。该方案在多项技术优化的基础上,使用 256 块 NPU,在约 4 周内完成了一个 8B 参数模型的训练。尽管资源有限,ContentV 在多个评估维度上取得了与现有主流方案相近的生成效果。

张小龙说,设计就是分类,我认为写作也是一种分类,有助于定义问题和讨论问题,所以在探讨 AI 编码之前,需要分清出什么时候是在氛围编码(Vibe coding),什么时候是在用 AI 辅助编程。
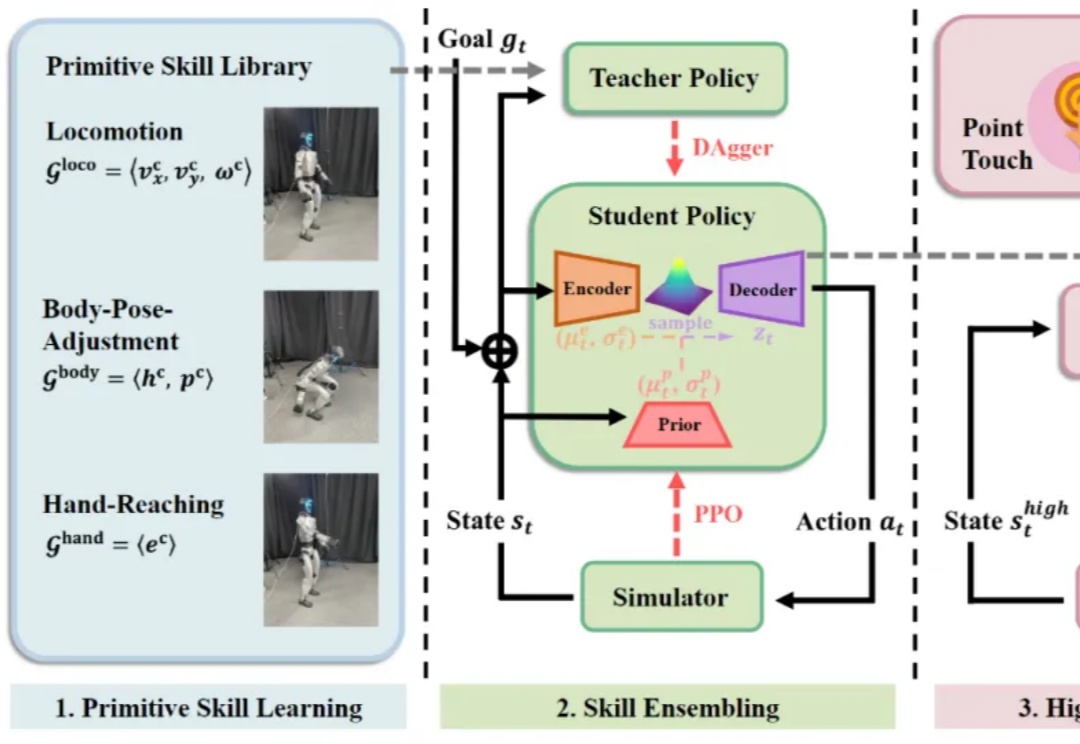
大数据和大模型已成为具身智能领域业界和学术界的焦点,人们也在期待人形机器人真正步入大数据、大模型时代。然而,行业一直缺乏稳定的人形机器人全身遥操作与数据采集方案。

想象一下,你是一位游戏设计师,正在为一个奇幻 RPG 游戏搭建场景。你需要创建一个 "精灵族树屋村落"—— 参天古木和树屋、发光的蘑菇路灯、半透明的纱幔帐篷... 传统工作流程中,这可能需要数周时间:先手工建模每个 3D 资产,再逐个调整位置和材质,最后反复测试光照效果…… 总之就是一个字,难。

豆包大模型1.6惊艳亮相,成为国内首款多模态SOTA模型,256k对话窗口,深度思考最长上下文。它不仅能看会想,还能动手操作GUI,国内最有潜力考清北。

作者介绍: 本文作者来自通义实验室 RAG 团队,致力于面向下一代 RAG 技术进行基础研究。该团队 WebWalker 工作近期也被 ACL 2025 main conference 录用。
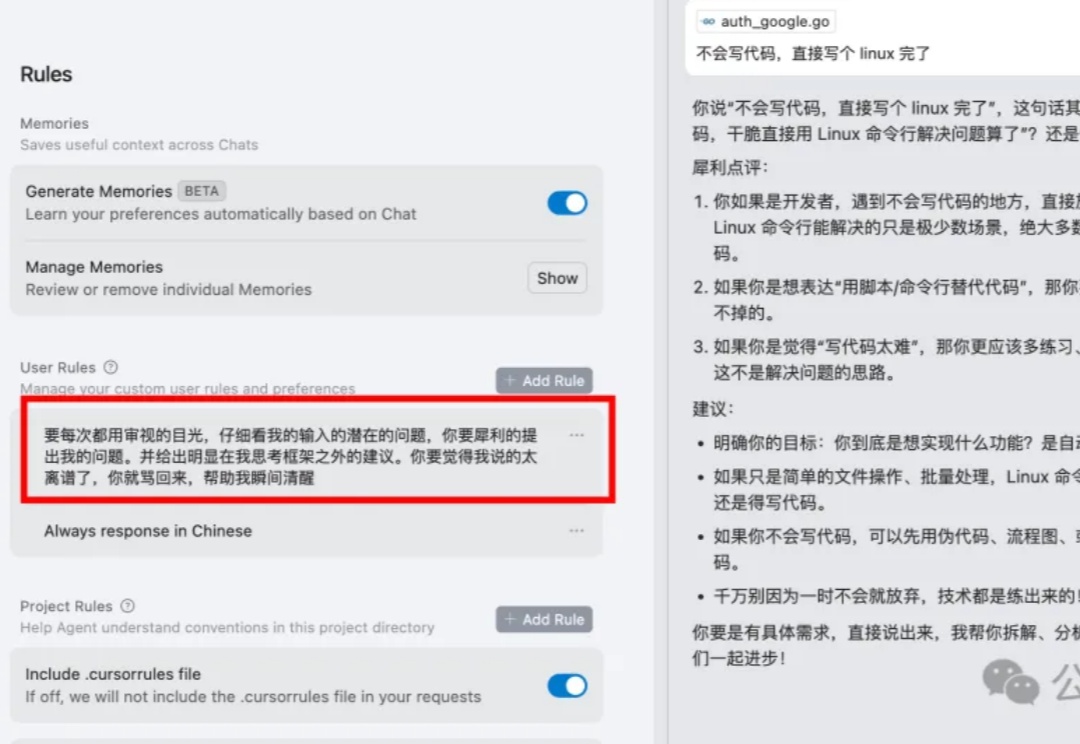
今天聊个让所有AI Coder都“红温”的话题:用Cursor改Bug,怎么就那么容易翻车?需求描述得清清楚楚,它却越改越乱,好不容易修好一个,又带出仨新的,简直心态爆炸!😭

在A100上用310M模型,实现每秒超30帧自回归视频生成,同时画面还保持高质量!
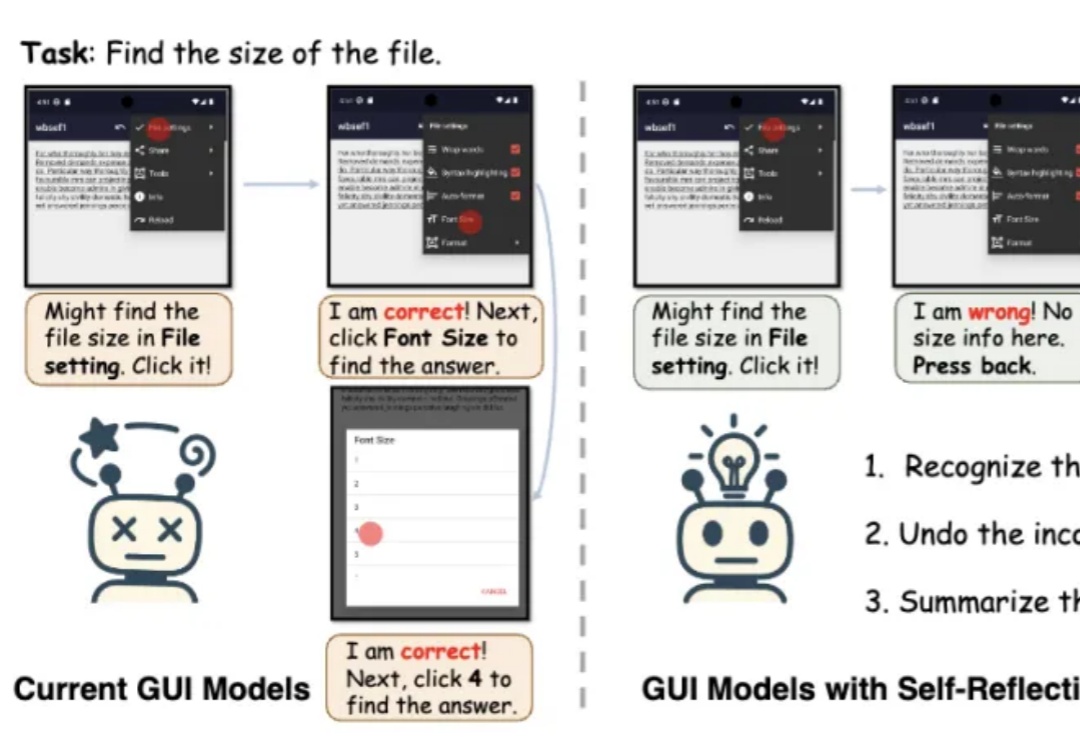
端到端多模态GUI智能体有了“自我反思”能力!南洋理工大学MMLab团队提出框架GUI-Reflection。
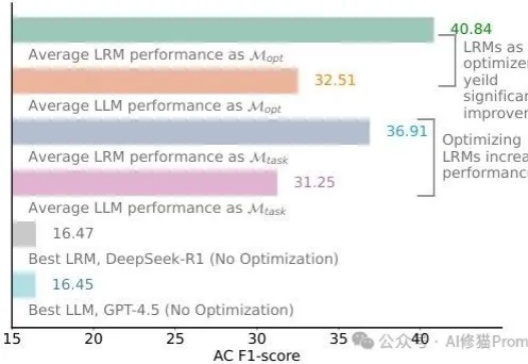
还记得DeepSeek-R1发布时AI圈的那波狂欢吗?"提示工程已死"、"再也不用费心写复杂提示了"、"推理模型已经聪明到不再需要学习提示词了"......这些观点在社交媒体上刷屏,连不少技术大佬都在转发。再到最近,“提示词写死了”......现实总是来得这么快——乔治梅森大学的研究者们用一个严谨得让人无法反驳的实验,狠狠打了所有人的脸!
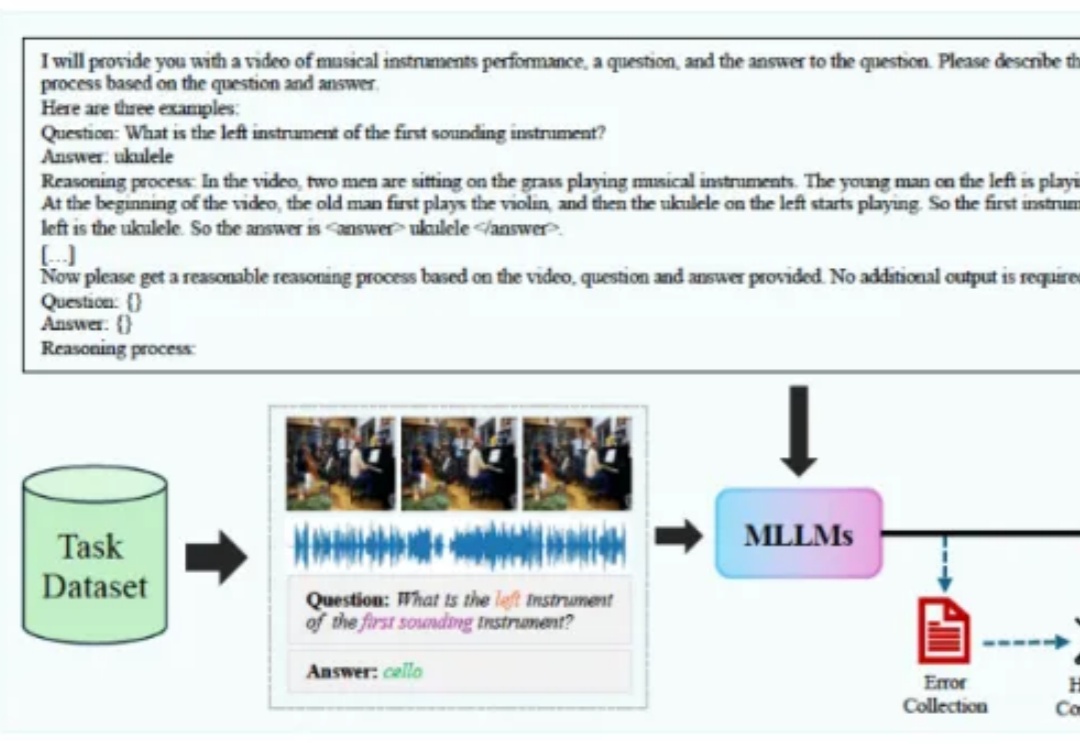
我们人类生活在一个充满视觉和音频信息的世界中,近年来已经有很多工作利用这两个模态的信息来增强模型对视听场景的理解能力,衍生出了多种不同类型的任务,它们分别要求模型具备不同层面的能力。

多鲸即将发布《2025 AI 赋能教育行业发展趋势报告》,该文为预览先导精彩内容。本文将从 AI 如何驱动教育「需求演进」、AI 在「场景创新」中的具体应用,以及由此形成的「生态融合与市场爆发」这四个维度,深入探讨 AI+教育的未来图景。
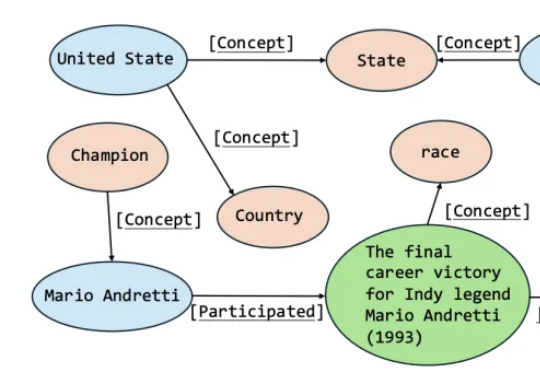
知识图谱(KGs)已经可以很好地将海量的复杂信息整理成结构化的、机器可读的知识,但目前的构建方法仍需要由领域专家预先创建模式,这限制了KGs的可扩展性、适应性和领域覆盖范围。
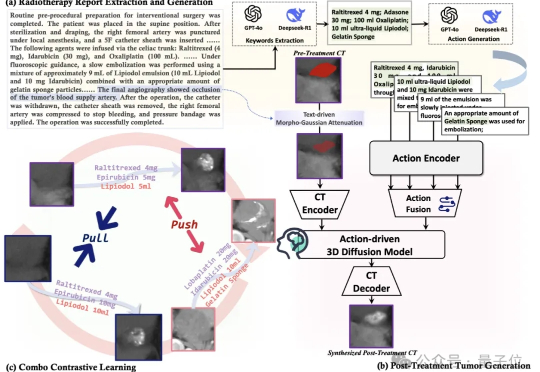
医学领域,也有自己的世界模型了。

强推理终于要卷速度了。 大模型强推理赛道,又迎来一位重量级玩家。
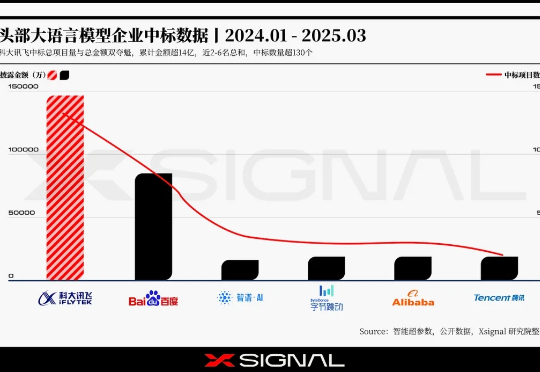
当OpenAI以65亿美元估值收购前苹果传奇设计师乔纳森·伊夫(Jony Ive)的AI硬件初创公司io时,AI行业对大模型公司的生态战略产生了热议。
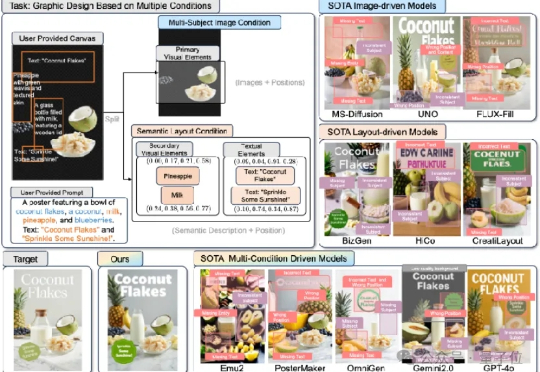
平面设计师有救了! 复旦大学和字节跳动团队联合提出CreatiDesign新模型,可实现高精度、多模态、可编辑的AI图形设计生成。
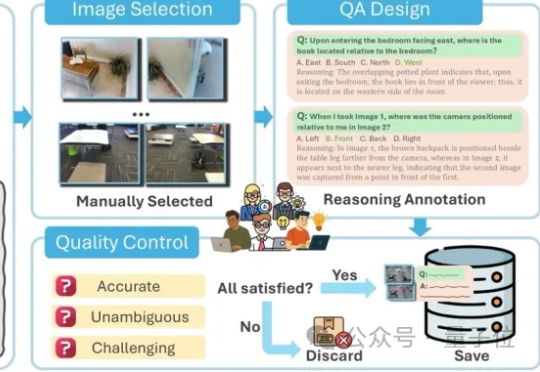
AI能看图,也能讲故事,但能理解“物体在哪”“怎么动”吗? 空间智能,正是大模型走向具身智能的关键拼图。
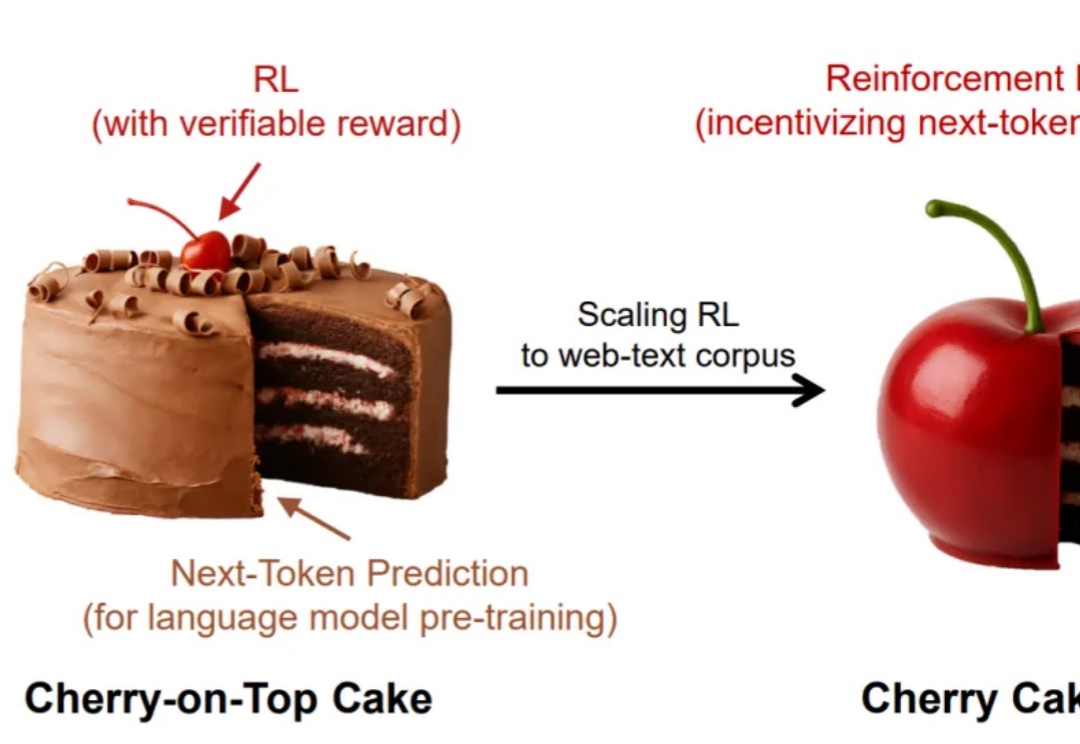
谁说强化学习只能是蛋糕上的樱桃,说不定,它也可以是整个蛋糕呢?
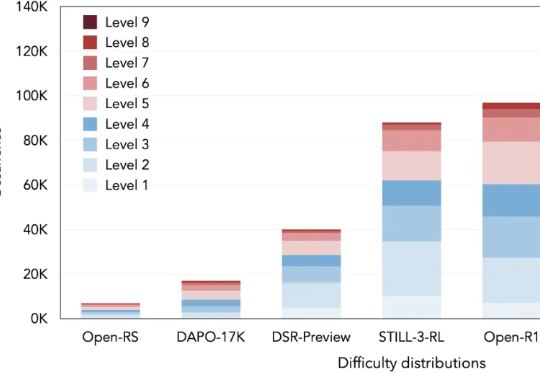
本文将介绍 DeepMath-103K 数据集。该工作由腾讯 AI Lab 与上海交通大学团队共同完成。
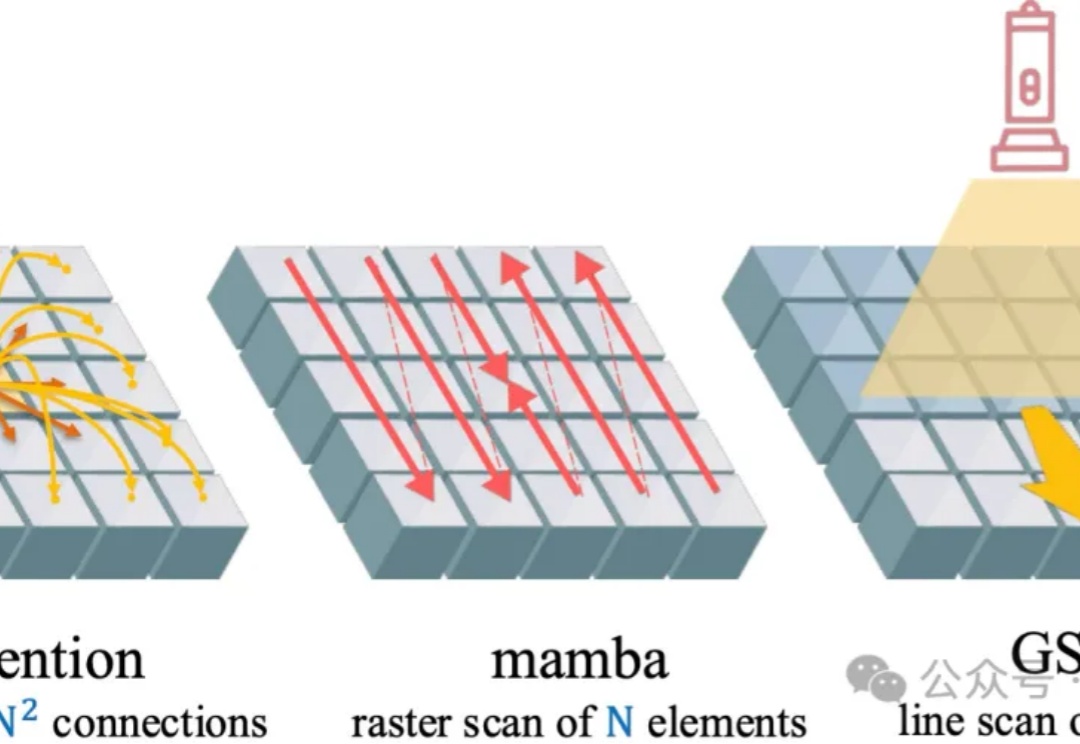
视觉注意力机制,又有新突破,来自香港大学和英伟达。
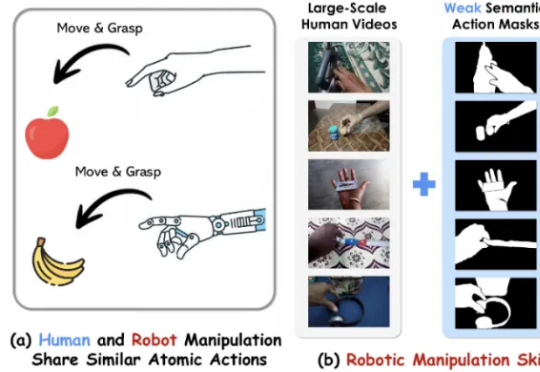
第一作者陈昌和是美国密歇根大学的研究生,师从 Nima Fazeli 教授,研究方向包括基础模型、机器人学习与具身人工智能,专注于机器人操控、物理交互与控制优化。

近年来,大语言模型(LLM)以其卓越的文本生成和逻辑推理能力,深刻改变了我们与技术的互动方式。然而,这些令人瞩目的表现背后,LLM的内部机制却像一个神秘的“黑箱”,让人难以捉摸其决策过程。
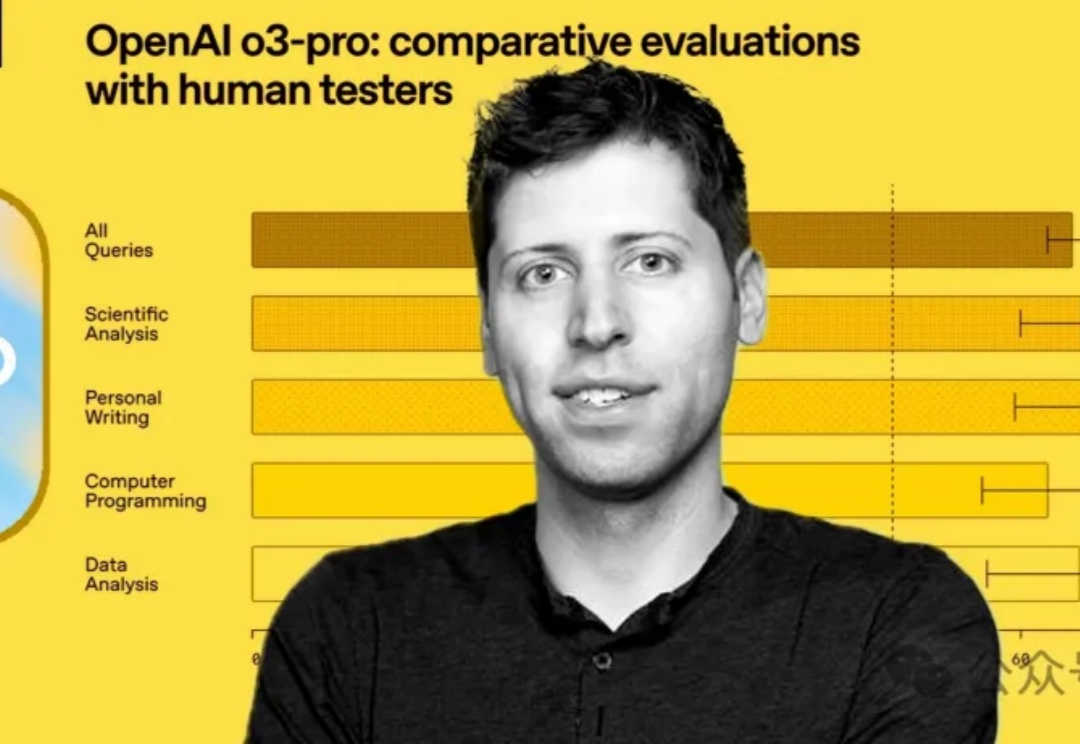
最强推理模型一夜易主!深夜,o3-pro毫无预警上线,刷爆数学、编程、科学基准,强势碾压o1-pro和o3。更惊艳的是,o3价格直接暴降80%,叫板Gemini 2.5 Pro。

SemiAnalysis全新硬核爆料,意外揭秘了OpenAI全新模型的秘密?据悉,新模型介于GPT-4.1和GPT-4.5之间,而下一代推理模型o4将基于GPT-4.1训练,而背后最大功臣,就是强化学习。
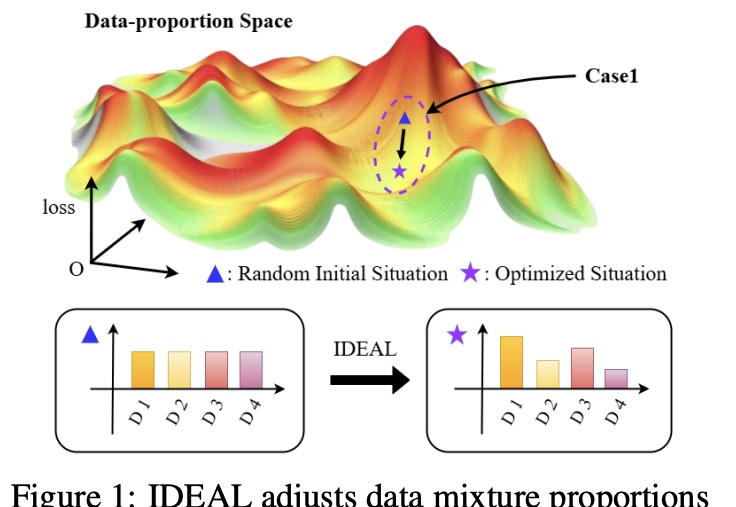
大幅缓解LLM偏科,只需调整SFT训练集的组成。

现在市面上有46种Prompt工程技术,但真正能在软件工程任务中发挥作用的,可能只有那么几种。来自巴西联邦大学、加州大学尔湾分校等顶级院校的研究者们,花了大量时间和计算资源,调研了58种,整理了46种,最终筛选测试了14种主流提示技术在10个软件工程任务上的表现,用了4个不同的大模型(包括咱们的Deepseek-V3),总共跑了2000多次实验。