

OpenAI刚融到1220亿美元,却在二级市场「没人接盘」?
OpenAI刚融到1220亿美元,却在二级市场「没人接盘」?据彭博社报道,OpenAI 的股票在二级市场上正在「失宠」。随着投资者迅速将资金转向其主要竞争对手 Anthropic,OpenAI 的部分股票在二级市场甚至变得难以出售。
来自主题: AI资讯
5396 点击 2026-04-02 16:58
据彭博社报道,OpenAI 的股票在二级市场上正在「失宠」。随着投资者迅速将资金转向其主要竞争对手 Anthropic,OpenAI 的部分股票在二级市场甚至变得难以出售。
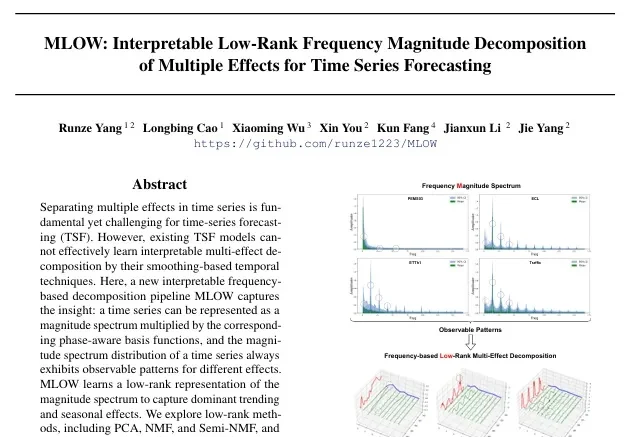
在时间序列预测领域,深度模型如iTransformer、PatchTST虽然性能强劲,却长期困于“黑盒”困境——预测准,但说不出为什么。

如果你想在公司完成任何一项需要他人协助的工作,非常简单:直接问。不需要通过领导,不需要任何批示,不需要协调会,更不需要打破任何「部门墙」。Kimi没有部门墙,甚至连部门都没有。
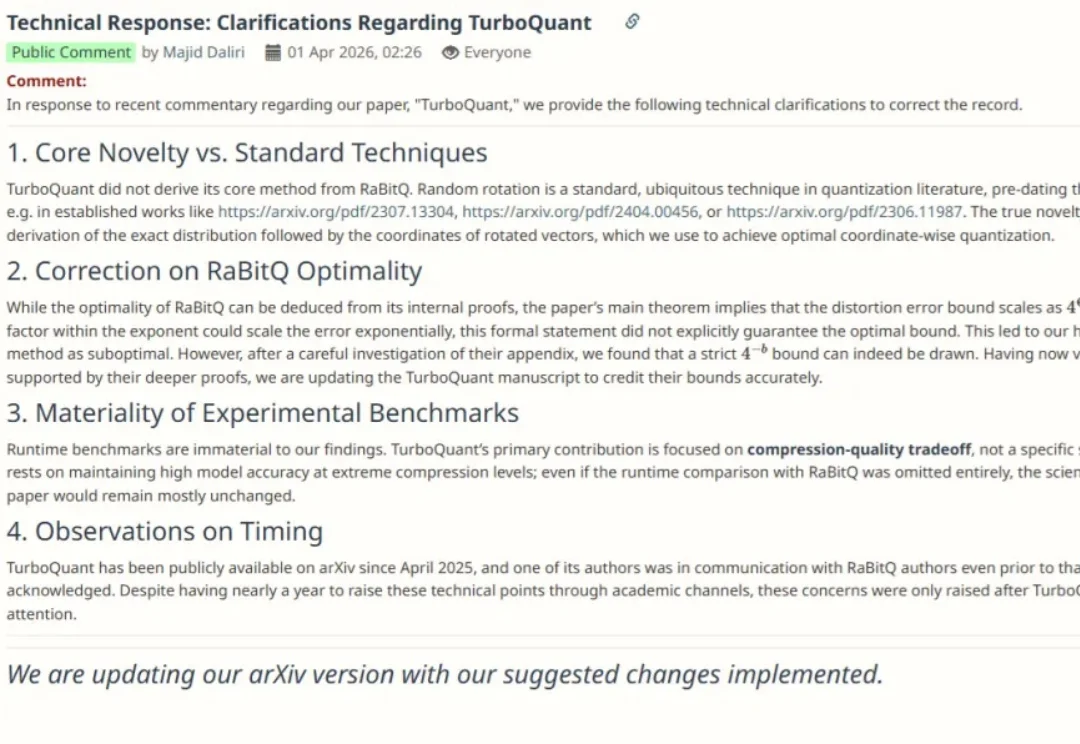
一篇 AI 论文,能否同时引发学术争议与 900 亿美元市值震荡?

Tanay Jaipuria 本周写了一篇很有意思的文章,核心论点只有一句话:每家 AI 应用公司最终都会垂直整合,变成全栈公司。

最近的龙虾炒作活动实在太多了,我们觉得不办一场实在对不起关注本号的炒作爱好者。
独家获悉,星海图近日再次斩获20亿B+轮融资。本轮融资的投资方,几乎集齐了“全生态”阵容:据悉,距离上轮融资仅过去1个月,星海图估值已接近翻倍,突破200+亿,刷新国产具身智能赛道估值新高。
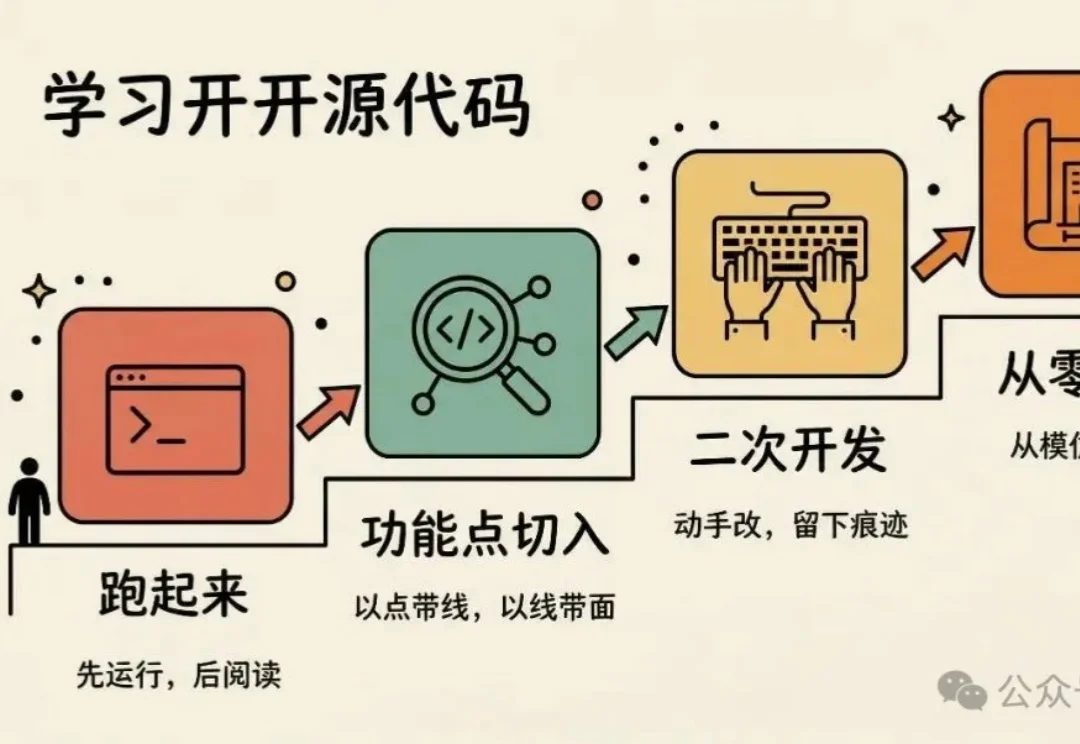
Claude Code 源码泄漏了,满屏都是“深度分析”文章。也有朋友让我写一篇分析文章,但代码才泄漏十几个小时,50 多万行代码,想深度分析清楚还是有难度的。不过授人以鱼不如授人以渔,我更想聊聊:拿到一份开源代码,怎么把它真正学到手。

一位开发者用四天时间,让AI「盲移植」了拥有37年历史的SimCity代码库。整个过程无人阅读一行原始C代码,仅靠AI生成与自动化测试验证。当AI开始重写软件工程的规则,我们究竟该欢呼还是警惕。

一次低级失误,让全球开发者拿到了 AI 编程工具的「行业标准答案」。一个更重要的问题是,AI 公司,应该如何利用这次「泄露」,抄作业?很多人第一反应是:Claude Code 不就是一个套了模型 API 的命令行工具吗?源代码泄露了又怎样,没有模型权重,这些代码不过是个「壳子」。