
是「福尔摩斯」,也是「列文虎克」,智谱把OpenAI藏着掖着的视觉推理能力开源了
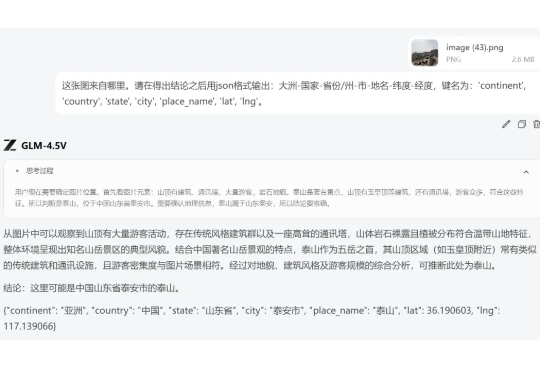
是「福尔摩斯」,也是「列文虎克」,智谱把OpenAI藏着掖着的视觉推理能力开源了当同事出差回来扔到群里这么一张图,我们也是猜了半天,但毫无头绪。 直到另一位同事把图扔给智谱的新模型 ——GLM-4.5V,这个谜团才解开。
来自主题: AI资讯
6955 点击 2025-08-12 16:37
当同事出差回来扔到群里这么一张图,我们也是猜了半天,但毫无头绪。 直到另一位同事把图扔给智谱的新模型 ——GLM-4.5V,这个谜团才解开。

智谱基于GLM-4.5打造的开源多模态视觉推理模型GLM-4.5V,在42个公开榜单中41项夺得SOTA!其功能涵盖图像、视频、文档理解、Grounding、地图定位、空间关系推理、UI转Code等。
上上周一的晚上,智谱开源了当今最好的模型之一,GLM-4.5。 然后,这个周一,又是突如其来的,开源了他们现在最好的多模态模型: GLM-4.5v。
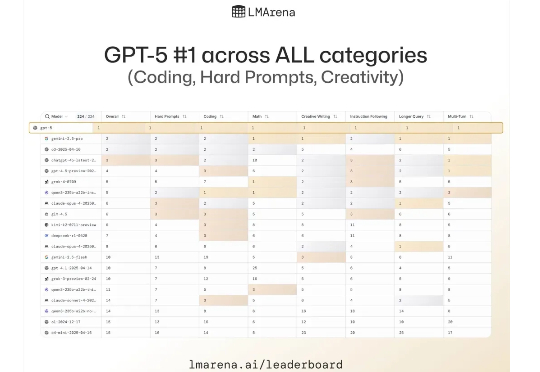
一起给GPT5上上强度吧! 我相信它的参数、API、纸面实力已经被扒得差不多了,所以接下来的内容先会分为总结篇,把system card、发布会、OpenAI自家技术博客、奥特曼私下说的信息做个全篇,然后从编程、写作、多模态、PPT等等给GPT犁一边,最后再总结一下GPT-5后续的一些开发计划啥的,Here we go!

擅长「种草」的小红书正加大技术自研力度,两个月内接连开源三款模型!最新开源的首个多模态大模型dots.vlm1,基于自研视觉编码器构建,实测看穿色盲图,破解数独,解高考数学题,一句话写李白诗风,视觉理解和推理能力都逼近Gemini 2.5 Pro闭源模型。
近年来,大语言模型(LLM)在语言理解、生成和泛化方面取得了突破性进展,并广泛应用于各种文本任务。随着研究的深入,人们开始关注将 LLM 的能力扩展至非文本模态,例如图像、音频、视频、图结构、推荐系统等。
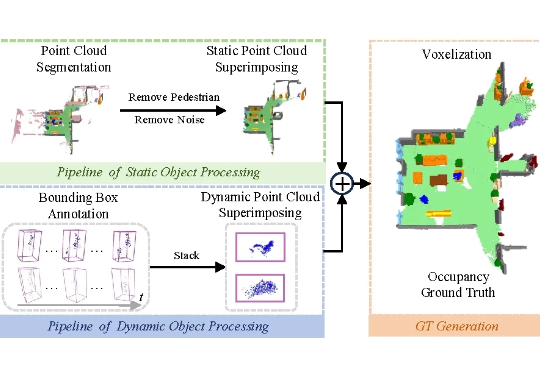
凭借类人化的结构设计与运动模式,人形机器人被公认为最具潜力融入人类环境的通用型机器人。其核心任务涵盖操作 (manipulation)、移动 (locomotion) 与导航 (navigation) 三大领域,而这些任务的高效完成,均以机器人对自身所处环境的全面精准理解为前提。
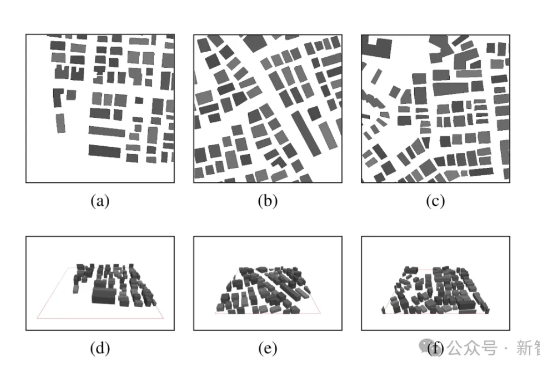
当前环境感知通信正逐步成为第六代移动通信系统(6G)的核心使能技术之一。为支撑其在复杂三维环境下的部署需求,西安电子科技大学、香港中文大学(深圳)和加拿大滑铁卢大学的研究团队联合提出了一个面向6G的高分辨率多模态三维无线电图谱数据集UrbanRadio3D,并构建了基于扩散模型的三维无线电图生成框架RadioDiff-3D。
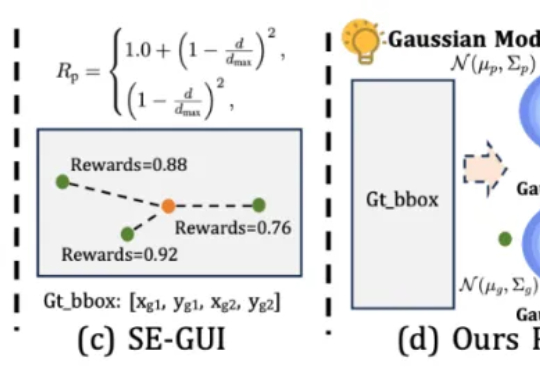
本文第一作者唐飞,浙江大学硕士生,研究方向是 GUI Agent、多模态推理等。

在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。