百亿体检龙头,成立一家AI医疗!牵手华为、阿里,收入暴涨71.89%!
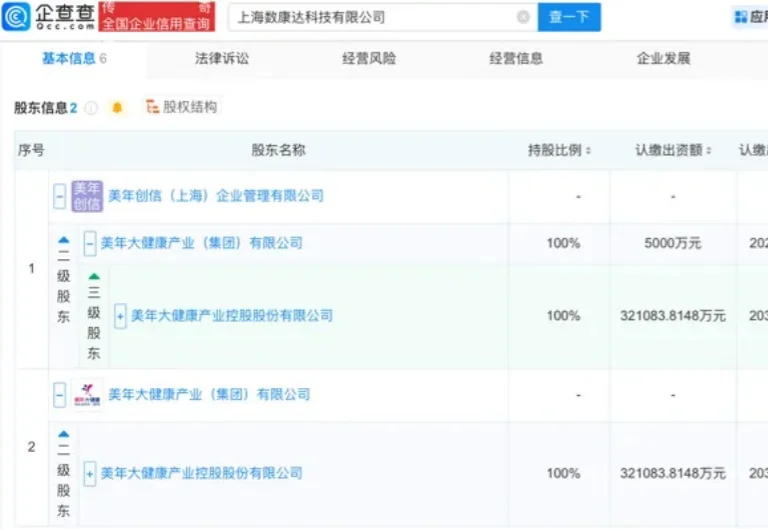
百亿体检龙头,成立一家AI医疗!牵手华为、阿里,收入暴涨71.89%!近日,企查查股权穿透显示,体检龙头美年健康(002044.SZ)间接全资持股了一家全新的AI企业上海数康达科技有限公司。
来自主题: AI资讯
8389 点击 2026-05-28 15:12
 搜索
搜索
近日,企查查股权穿透显示,体检龙头美年健康(002044.SZ)间接全资持股了一家全新的AI企业上海数康达科技有限公司。
![[翻译] AI Agent 的 Zero Trust 框架|Anthropic 安全白皮书](https://www.aitntnews.com/pictures/2026/5/28/a5aa95a5-5a65-11f1-add0-fa163e47d677.webp)
Zero Trust 是一套安全架构,核心前提很简单:不信任任何东西,必须验证一切

《读佳》获知,蚂蚁集团低调推出一款叫做 “Willit”的AI眼镜产品,且已在淘宝上线,眼镜适配的 “Willit AI”APP亦同步在应用市场上线。此外,适配的“Willit AI”APP已上架部分应用商店,应用宝显示其开发商、运营商、主办者均为萨思数字科技(北京)有限公司

近期,深圳河套学院(SLAI)AI训练平台项目团队,联合哈尔滨工业大学(深圳)、深圳大数据研究院、华为GTS(全球技术服务)团队与深智城AI算力平台,仅用1个月,共同基于昇腾910C国产算力集群实现DeepSeek-V4-Pro全参数续训练/SFT稳定运行,完成长稳训练1500+步,训练MFU超30%,关键训练算子效率提升14%。
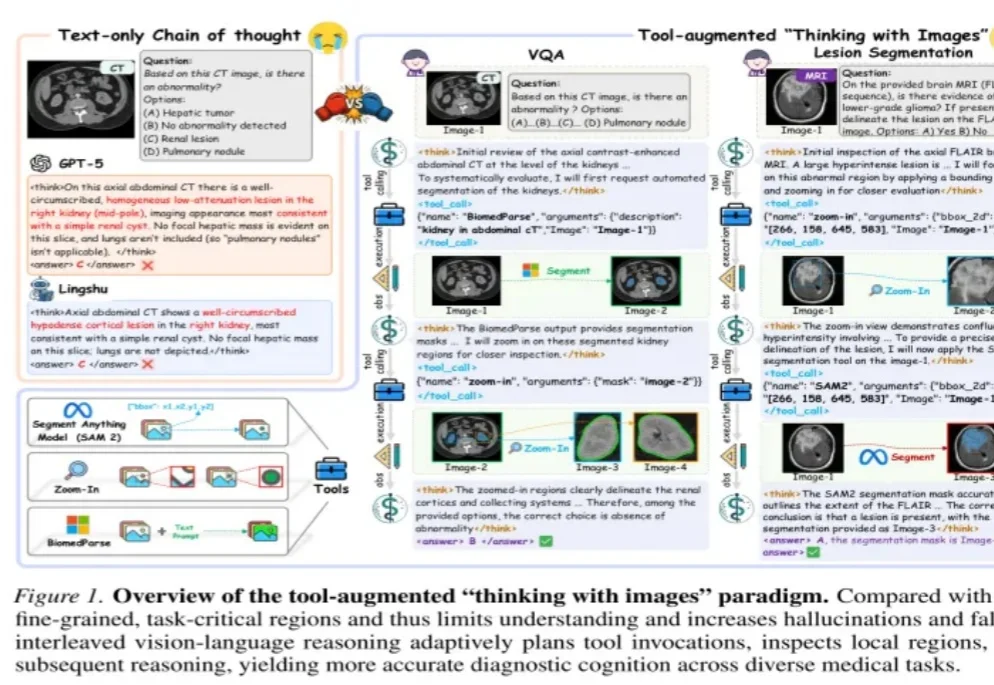
医学AI会写解释,但不代表它真的“看到”了关键证据。

从数学、代码、复杂推理,到多轮工具调用,大模型的很多能力的提升都离不开 RL 后训练。但当模型规模进入 MoE 万亿参数级别之后,RL 不再只是一个算法问题,同时更加是一个系统问题。
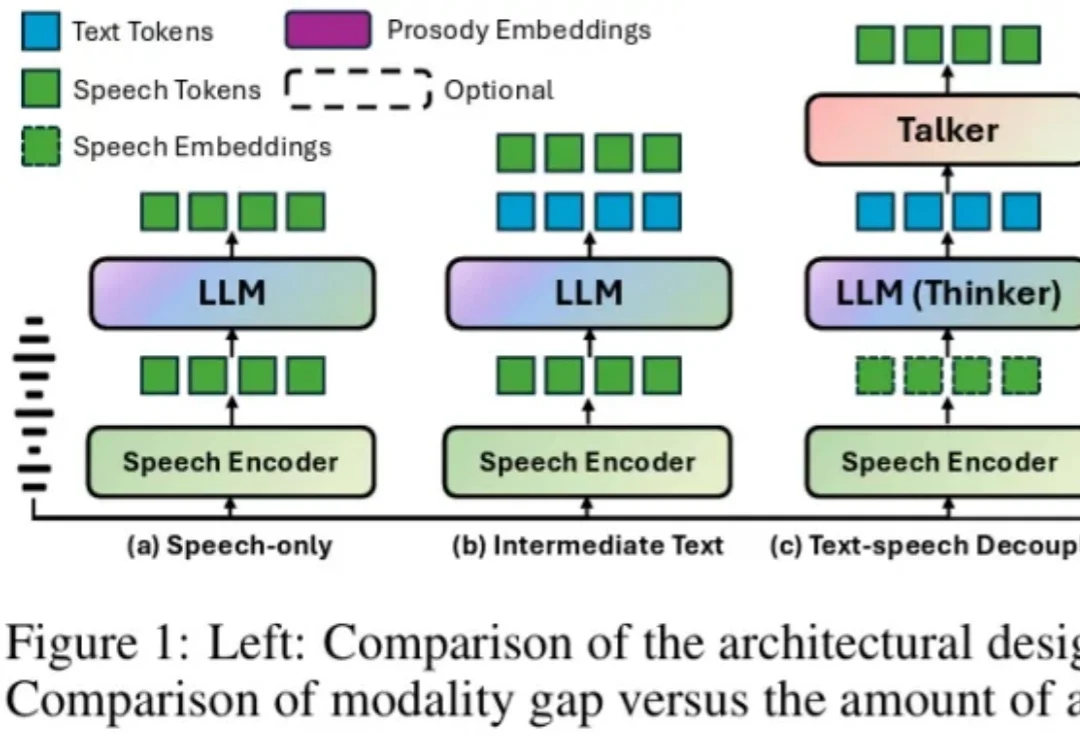
相信大家都有过这样的体验:同一个系列的模型,使用文本交互的时候,模型就像开启了 “最强大脑”,数学代码等各种复杂推理任务样样精通,可是一旦将其改造成语音对话模型之后,性能就猛烈下降,严重 “降智”,经常会犯很多基本的逻辑错误。

当下视频生成模型正在快速逼近真实世界的画面质感,但一个现实瓶颈也越来越突出—— 那就是分辨率越高,生成所需要的时间就越长。
根据《金融时报》、路透社等媒体的报道,英伟达首席执行官黄仁勋(Jensen Huang)已接受邀请,加入清华大学经济管理学院顾问委员会。
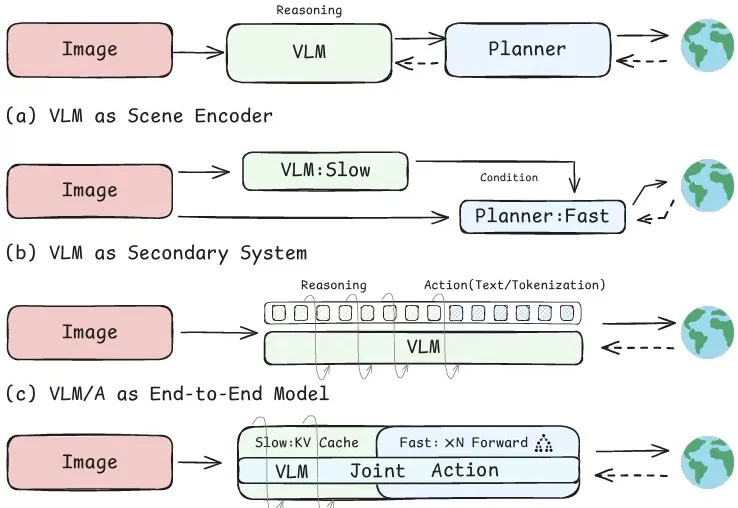
大模型进入自动驾驶后,最直接的价值在于场景理解。它可以识别前车是否准备并线、行人是否可能横穿、施工区域是否会影响车道,也可以分析复杂路口中的让行关系。