

实测 MiniMax M2.7:AI 狠起来,连自己都卷
实测 MiniMax M2.7:AI 狠起来,连自己都卷我们也在 Claude Code、本地部署的龙虾里,都接入了 MiniMax M2.7 模型,以及 MiniMax 提供的 MaxClaw,然后把真实的开发过程中遇到的 Bug、枯燥的金融数据,还有大量的长流程任务统统交给它。
来自主题: AI产品测评
9253 点击 2026-03-20 11:16
我们也在 Claude Code、本地部署的龙虾里,都接入了 MiniMax M2.7 模型,以及 MiniMax 提供的 MaxClaw,然后把真实的开发过程中遇到的 Bug、枯燥的金融数据,还有大量的长流程任务统统交给它。

砸了724亿美金「学费」后,微软用一场大重组承认 Copilot「走弯路」了。

Transformer不保?今天,CMU普林斯顿原班人马杀回,新一代开源架构Mamba-3震撼降临。15亿参数战力爆表,性能比Transformer飙升4%。
3 月 17 日,亚布力论坛年会现场,宇树科技创始人王兴兴被问及中国 AI 进展时,点名表扬了一款国产 AI:「今年一月份字节跳动 Seedance 2.0 视频生成软件,我觉得是全球目前最好的,全球遥遥领先。」

上周,除了 OpenClaw,AI 圈还有个词越来越火🔥。

Agnes AI近日披露了一组新的业务数据:全球用户规模已突破700万,年度经常性收入(ARR)接近2000万美元,并于去年底完成千万美元级融资。据公司方面透露,Agnes目前正在推进新一轮融资,目标估值约2亿美元,以持续投入核心技术研发并推动全球市场扩展。
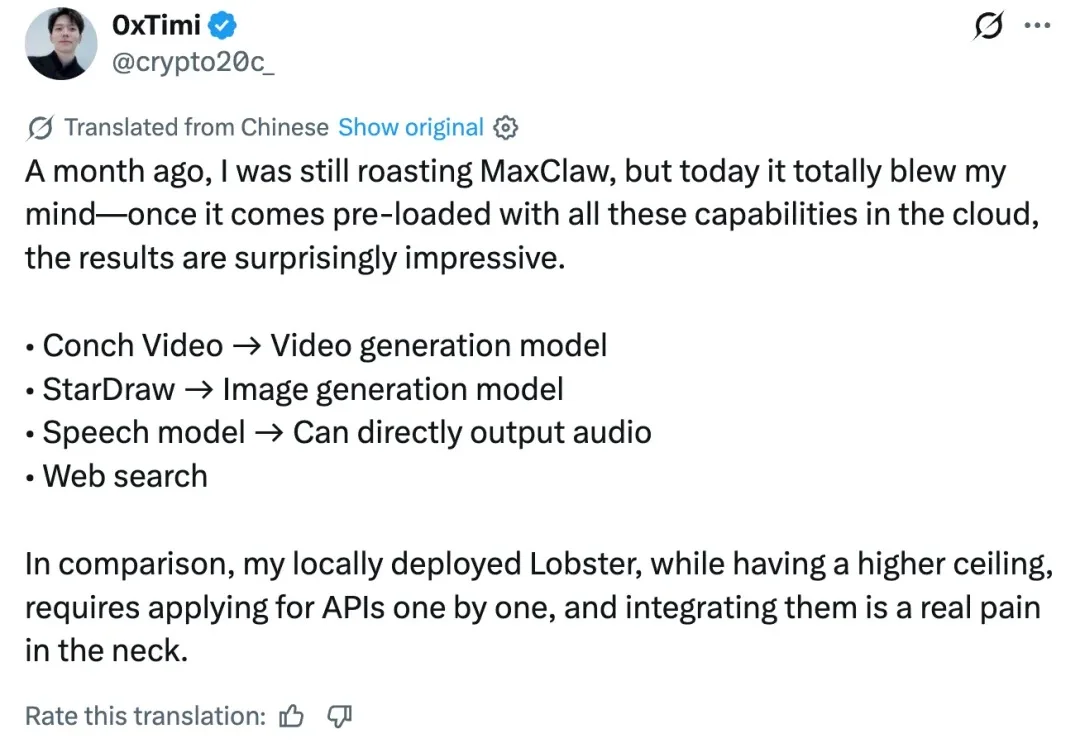
谁能料到,OpenClaw 的热度从年初延续到了今天。除了专业工程师,很多普通人也在 FOMO(错失恐惧)情绪驱动下,开始了对「养龙虾」的追捧。

如果你最近在关注AI Agent,可能已经被各种“能力展示”刷屏,从自动写代码到全流程办公自动化,几乎每一条都在强调效率与技术跃迁。

在 M2 系列模型发布后的几个月,我们收到了大量热心用户的反馈和建议,这促使我们进一步加速模型的迭代效率。除了更加认真工作之外,我们能找到的唯一途径就是开启模型和组织的自我进化。MiniMax M2.7 是我们第一个模型深度参与迭代自己的模型。

刚刚,一篇阿里联合中山大学的研究在 X 上爆火了!