
一家00后创办的世界模型公司,凭什么让华为哈勃重金押注?
一家00后创办的世界模型公司,凭什么让华为哈勃重金押注?近日,世界模型与空间智能前沿公司魔芯科技已完成 Pre-A + 轮近亿元融资。本轮融资由华为哈勃领投,老股东跟投。
来自主题: AI资讯
10100 点击 2026-03-18 16:51
 搜索
搜索
近日,世界模型与空间智能前沿公司魔芯科技已完成 Pre-A + 轮近亿元融资。本轮融资由华为哈勃领投,老股东跟投。

当全网还在为搞定环境配置和Token账单焦头烂额时,有人直接掀了桌子,把OpenClaw从「工具」变成了「造印钞机」!

2025 年 1 月,特朗普在白宫亲自站台,宣布了一个号称“史上最大 AI 基础设施项目”的宏伟计划。OpenAI 联合软银、甲骨文和阿布扎比主权基金 MGX,组建了一家名为 Stargate LLC 的合资公司,承诺在四年内向美国 AI 基础设施投入 5,000 亿美元。

今天, Anthropic 的 Claude Code 团队工程师 Thariq Shihipar 在 X 上发布了一篇Skills的深度经验分享,帖子在AI/科技圈迅速引发热议。

AGI,究竟如何评判?刚刚,谷歌DeepMind发出重磅论文,直接从认知科学「借」了一套度量衡——把通用智能拆成10大认知能力,配一套三阶段评估协议,还联合Kaggle砸了20万美金,向全球研究者悬赏:谁能测出真正的AGI?
本文是 George Zhang 对 Harness engineering 的解读,原文发布于他的 X(https://x.com/odysseus0z)。
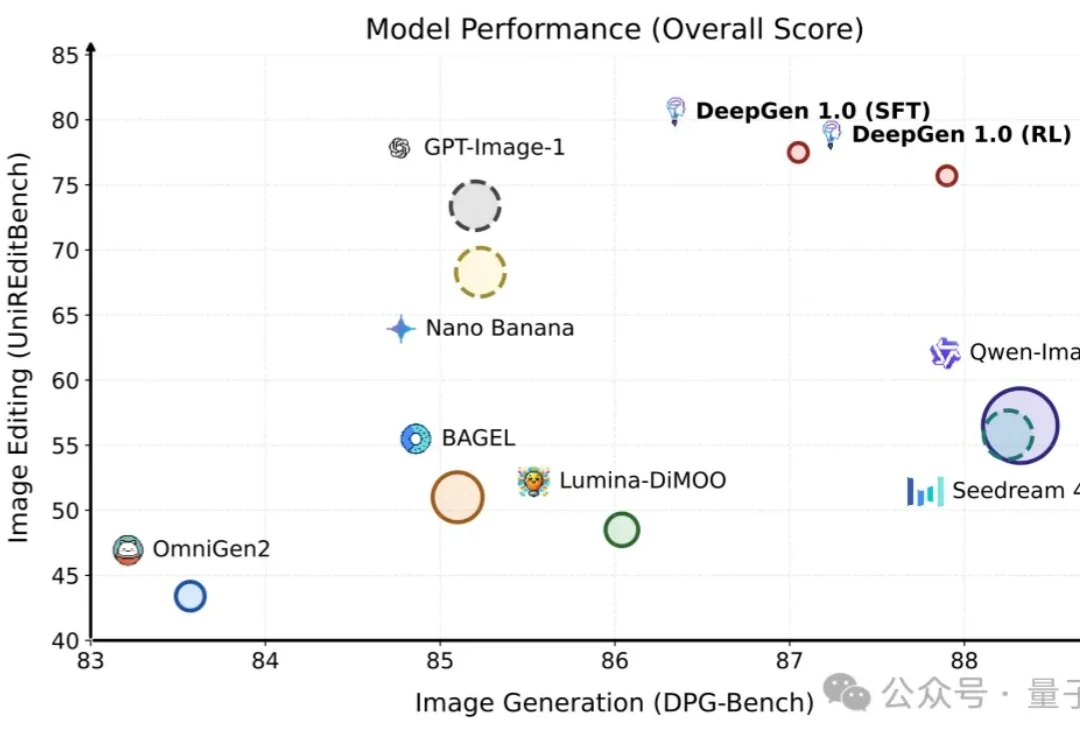
统一多模态生成编辑模型,正在走向“重器化”

前两天看到一个问题,“普通人要 OpenClaw 有什么用?”
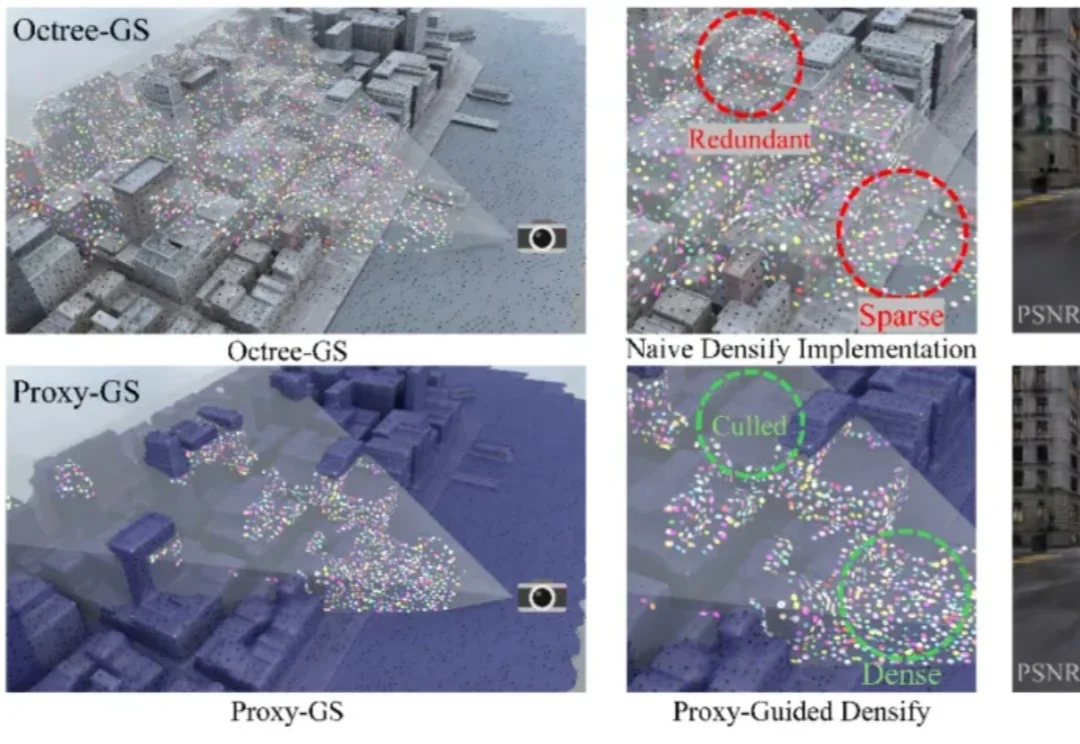
上海交通大学钟志航团队联合上海人工智能实验室、西北工业大学、四川大学等高校在 CVPR 2026 上提出Proxy-GS(Proxy-GS: Unified Occlusion Priors for Training and Inference in Structured 3D Gaussian Splatting),面向基于 MLP 的结构化 3D 高斯溅射(3DGS),

在 M2 系列模型发布后的几个月,我们收到了大量热心用户的反馈和建议,这促使我们进一步加速模型的迭代效率。除了更加认真工作之外,我们能找到的唯一途径就是开启模型和组织的自我进化。MiniMax M2.7 是我们第一个模型深度参与迭代自己的模型。