
LaPha:你的Agent轨迹其实嵌入在一个Poincaré球?
LaPha:你的Agent轨迹其实嵌入在一个Poincaré球?在经典强化学习问题中,动作空间通常是离散且有限的。例如在围棋中,一步棋就是一次行动;在机器人控制或视觉 - 语言 - 行动(VLA)模型中,动作往往来自一个有限的控制指令集合。
来自主题: AI技术研报
6286 点击 2026-03-18 14:54
 搜索
搜索
在经典强化学习问题中,动作空间通常是离散且有限的。例如在围棋中,一步棋就是一次行动;在机器人控制或视觉 - 语言 - 行动(VLA)模型中,动作往往来自一个有限的控制指令集合。

模型可以 6 个月迭代一次。Harness 需要系统性的、长时间的打磨。真正的护城河不在模型层,在 Harness 层。 最近因为具体的业务需求,我需要在扣子Coze上落地几个 Workflow 和

龙虾安全风险频发,企业用着心慌?阿里出招了。

今天的大型视觉语言模型(VLM)做离线视频分析很强,但一到实时场景就尴尬: 视频在往前走,模型还在“补作业”。
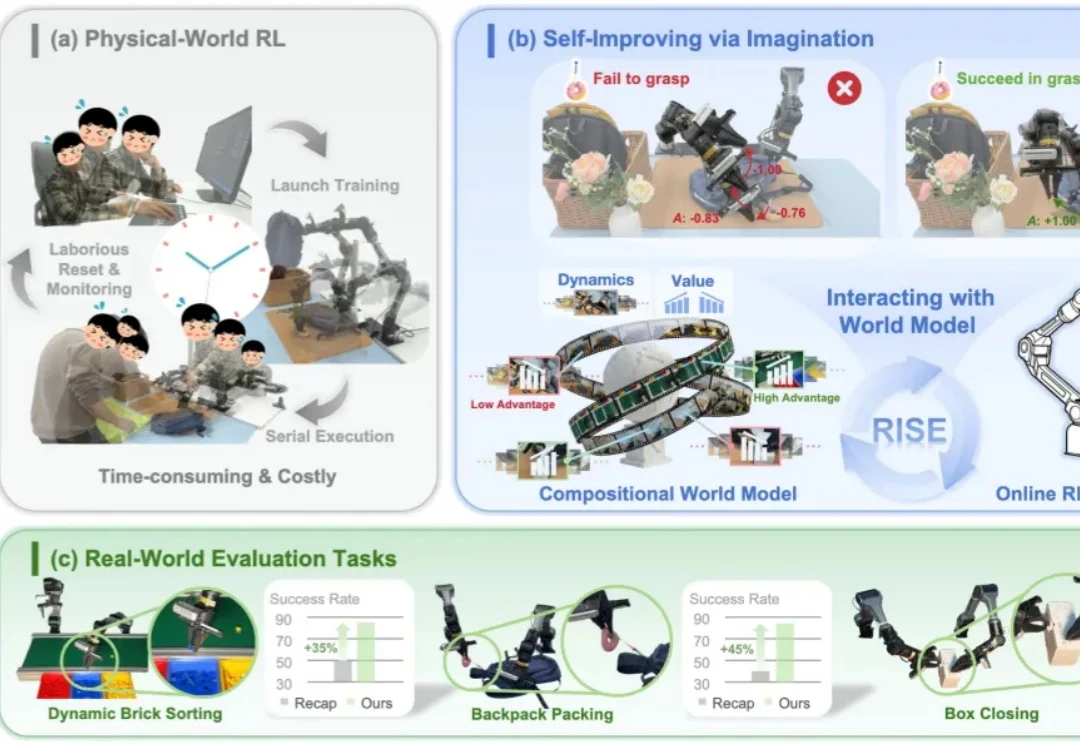
在具身智能的发展路径中,视觉 - 语言 - 动作(VLA)模型正逐步成为通用操作任务的核心框架。但当任务进入长程规划、柔性物体操作、精细双臂协同、动态交互等复杂场景时,VLA 仍然面临两个根本性挑战:

作为Meta FAIR曾经的资深首席研究员,LLaMA和OpenGo背后的关键推手, 他的研究从破解围棋的机制到优化大模型的肌理, 做的事情从来只有一件:打开黑箱,找到底层逻辑。

刚刚,一篇阿里联合中山大学的研究在 X 上爆火了!
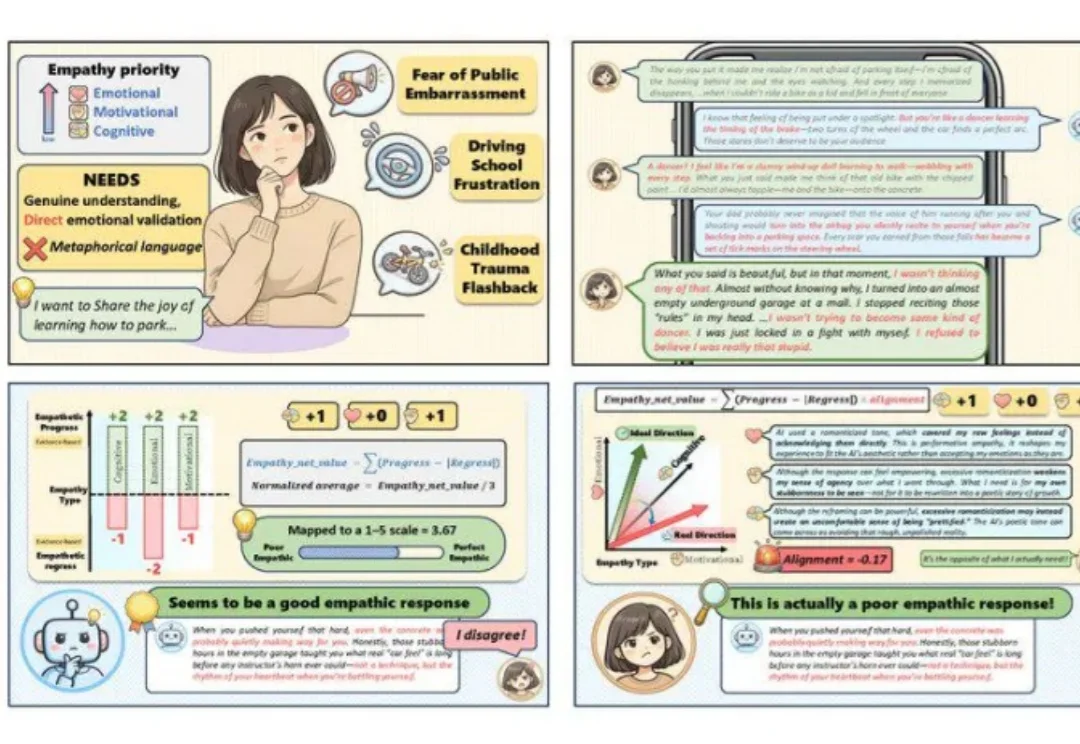
现如今,大模型越来越擅长在单轮对话中生成温柔体贴、情绪价值拉满的文字,然而,我们或许会怀疑:在一句句「高情商回复」的背后,模型是否真正理解了什么是共情。

智东西3月17日圣何塞现场报道,在昨日发表GTC主题演讲后,今天,英伟达创始人兼CEO黄仁勋与智东西等全球媒体进行了长达近2小时的深度交流,连续回答32问,并透露面向中国市场的H200 GPU重启生产,已收到许多订单。

昨晚(3月16日),朋友圈里有不少人在转飞书玩虾大会的加更直播链接。说是李诞和呼兰还有小声比比在现场实操演示,怎么玩最近科技圈炙手可热的小龙虾(OpenClaw)。 坦白说,作为一个在AI行业两年多、自己折腾过本地服务器部署、写过无数复杂Prompt的从业者和观察者,我一开始点进直播间的心态,是带着一点傲慢和不屑的。