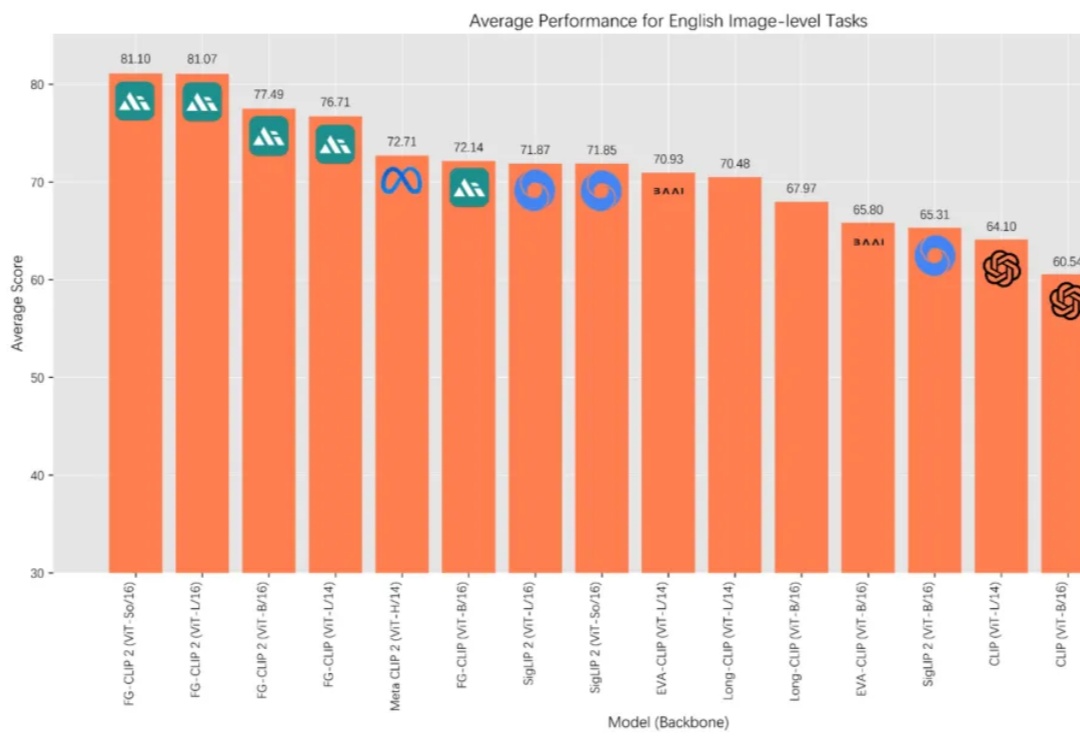
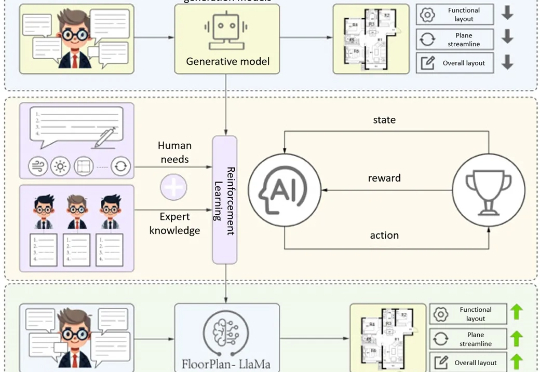
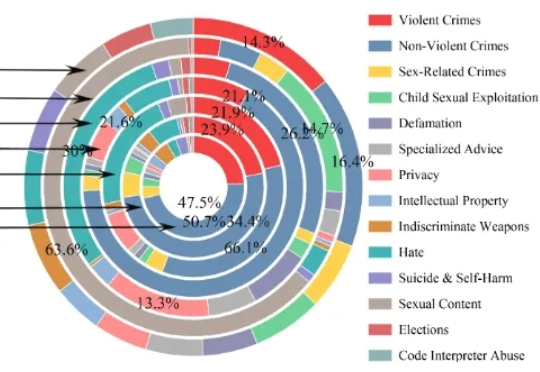
18个月月收33万刀!起底“AI套壳”生意经:是昙花一现还是隐形金矿?
18个月月收33万刀!起底“AI套壳”生意经:是昙花一现还是隐形金矿?Perplexity 的首席执行官 Aravind Srinivas 曾直言不讳:“世上万物皆是套壳(Everything is a wrapper)。OpenAI 套的是英伟达的算力和 Azure 的云服务;Netflix 套的是 AWS 的基础设施;就连市值高达 3200 亿美元的 Salesforce,归根结底也不过是 Oracle 数据库的一个高级外壳。”你
来自主题: AI资讯
7980 点击 2025-12-02 10:48