

MiniMax都在用!5500PB幕后功臣首次亮相,国产黑马祭出杀招
MiniMax都在用!5500PB幕后功臣首次亮相,国产黑马祭出杀招本次发布的核心——AIMesh,正是这场架构创新的集大成者。 它被定义为面向「AI工厂」的数据与内存网,核心思路是用一套「三网合一」的柔性网络,替代传统僵化的存储架构。
来自主题: AI资讯
8671 点击 2026-01-16 14:27
本次发布的核心——AIMesh,正是这场架构创新的集大成者。 它被定义为面向「AI工厂」的数据与内存网,核心思路是用一套「三网合一」的柔性网络,替代传统僵化的存储架构。

半成品模型,已经刷下高难度数学推理测试AIME 25满分战绩。

当前的训练与评测范式存在一个根本性的局限:几乎所有主流 Benchmark(如 MATH500、AIME)都聚焦于孤立的单步问题,问题之间相互独立,模型只需「回答一个问题,然后结束」。但真实世界的推理场景往往截然不同: 为填补这一空白,复旦大学与美团 LongCat Team 联合推出 R-HORIZON—— 首个系统性评估与增强 LRMs 长链推理能力的方法与基准。
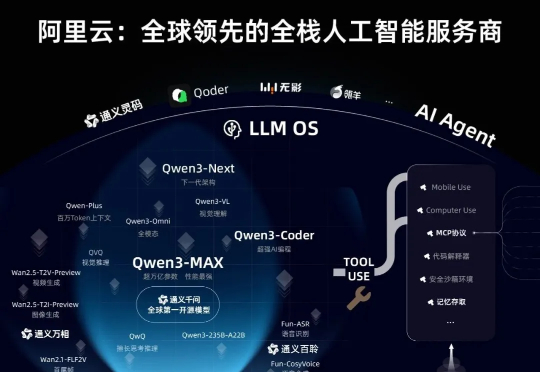
新一代旗舰模型Qwen3-Max带着满分成绩,正式地来了——国产大模型首次在AIME25和HMMT这两个数学评测榜单拿下100分!和前不久Qwen3-Max-Preview一致,参数量依旧是超万亿的规模。

AI是否会在5年内破解黎曼猜想?是否会保持每年5x的算力扩张节奏?十年后,AI将把我们带向一个什么样的世界?近日,Epoch AI负责人Jaime Sevilla,与数据与分析负责人Yafah Edelman在对话中,为我们揭示了未来十年AI发展的路线图。
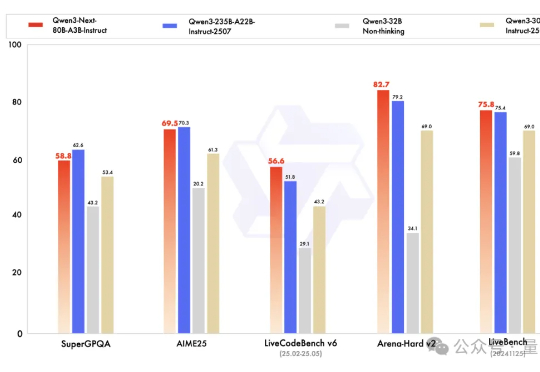
Qwen下一代模型架构,抢先来袭! Qwen3-Next发布,Qwen团队负责人林俊旸说,这就是Qwen3.5的抢先预览版。 基于Qwen3-Next,团队先开源了Qwen3-Next-80B-A3B-Base。
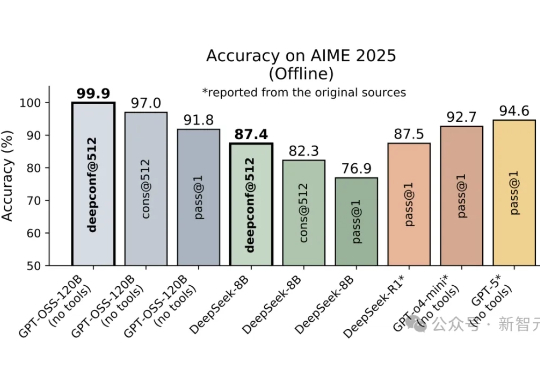
DeepConf由Meta AI与加州大学圣地亚哥分校提出,核心思路是让大模型在推理过程中实时监控置信度,低置信度路径被动态淘汰,高置信度路径则加权投票,从而兼顾准确率与效率。在AIME 2025上,它首次让开源模型无需外部工具便实现99.9%正确率,同时削减85%生成token。
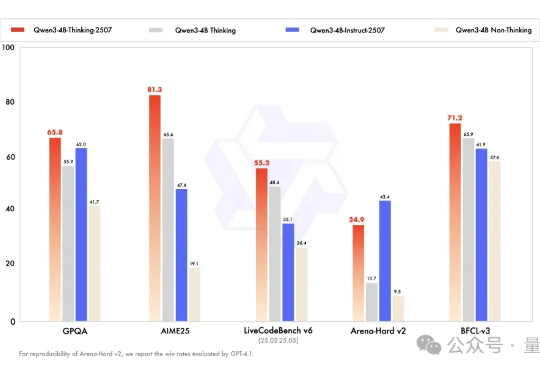
三天不开源,Qwen团队手就痒。 昨天深夜再次放出两个端侧模型: Qwen3-4B-Instruct-2507:非推理模型,大幅提升通用能力 Qwen3-4B-Thinking-2507:高级推理模型,专为专家级任务设计
香港大学NLP团队联合字节跳动Seed、复旦大学发布名为Polaris的强化学习训练配方:通过Scaling RL,Polaris让4B模型的数学推理能力(AIME25上取得79.4,AIME24上取得81.2)超越了一众商业大模型,如Seed-1.5-thinking、Claude-4-Opus和o3-mini-high(25/01/31)。

没等来 DeepSeek 官方的 R2,却迎来了一个速度更快、性能不弱于 R1 的「野生」变体!这两天,一个名为「DeepSeek R1T2」的模型火了!这个模型的速度比 R1-0528 快 200%,比 R1 快 20%。除了速度上的显著优势,它在 GPQA Diamond(专家级推理能力问答基准)和 AIME 24(数学推理基准)上的表现均优于 R1,但未达到 R1-0528 的水平。