
10行代码,AIME24/25提高15%!揭秘大模型强化学习熵机制
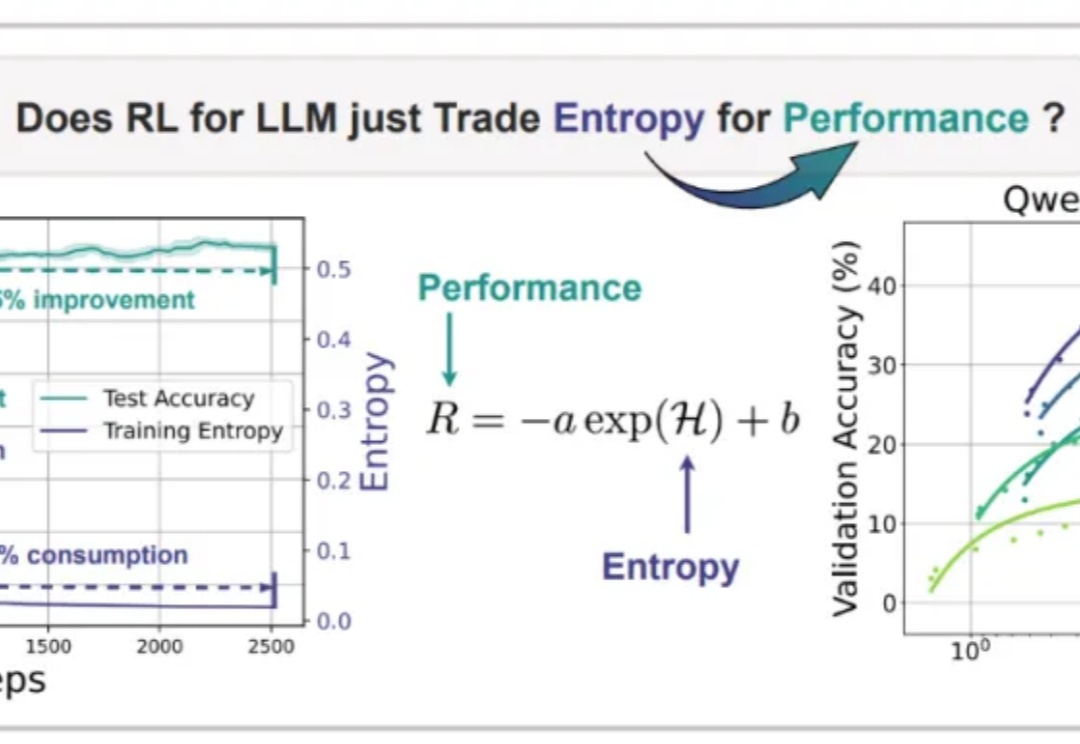
10行代码,AIME24/25提高15%!揭秘大模型强化学习熵机制Nature never undertakes any change unless her interests are served by an increase in entropy. 自然界的任何变化,唯有在熵增符合其利益时方会发生——Max Planck
来自主题: AI技术研报
6534 点击 2025-06-06 12:08
Nature never undertakes any change unless her interests are served by an increase in entropy. 自然界的任何变化,唯有在熵增符合其利益时方会发生——Max Planck

AI也会偷偷努力了?Letta和UC伯克利的研究者提出「睡眠时计算」技术,能让LLM在空闲时间提前思考,大幅提升推理效率。

南加州大学团队只用9美元,就能在数学基准测试AIME 24上实现超过20%的推理性能提升,效果好得离谱!而其核心技术只需LoRA+强化学习,用极简路径实现超高性价比后训练。
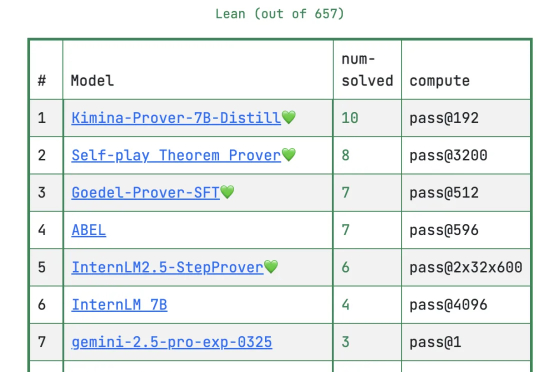
DeepSeek放大招!新模型专注数学定理证明,大幅刷新多项高难基准测试。在普特南测试上,新模型DeepSeek-Prover-V2直接把记录刷新到49道。目前的第一名在657道题中只做出10道题,为Kimi与AIME2024冠军团队Numina合作成果Kimina-Prover。
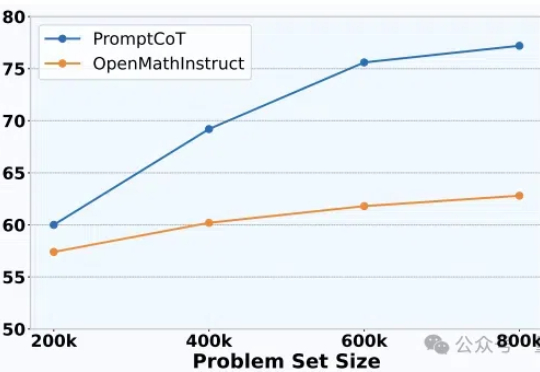
大模型架构研究进展太快,数据却快要不够用了,其中问题数据又尤其缺乏。
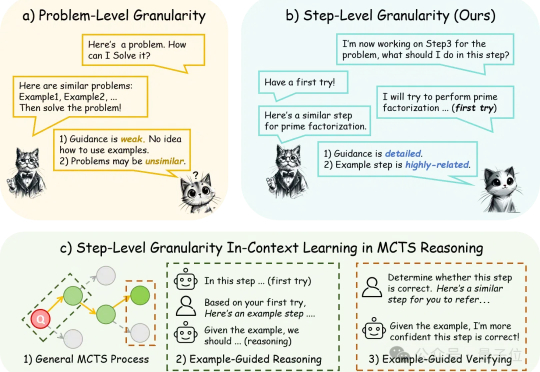
仅需简单提示,满血版DeepSeek-R1美国数学邀请赛AIME分数再提高。
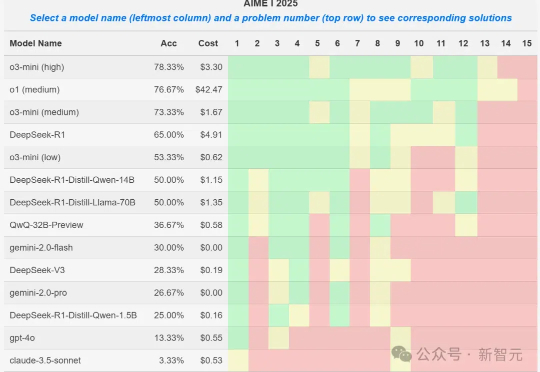
就在刚刚,AIME 2025 I数学竞赛的大模型参赛结果出炉,o3-mini取得78%的最好成绩,DeepSeek R1拿到了65%,取得第四名。然而一位教授却发现,某些1.5B小模型竟也能拿到50%,莫非真的存在数据集污染?