# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型,到底是学会了解决数学问题,还是只是背下了答案?
LLM的「Generalize VS Memorize」之争,迎来最新进展。
苏黎世联邦理工的研究员Mislav Balunović,在X上公布了一众顶级AI推理模型在AIME 2025 I比赛中的结果。

、
其中,o3-mini (high)令人印象非常深刻,以非常低的成本解决了78%的问题。
DeepSeek-R1,则解决了65%的问题,而且它的蒸馏变体也表现不错,不愧是领先的开源模型!
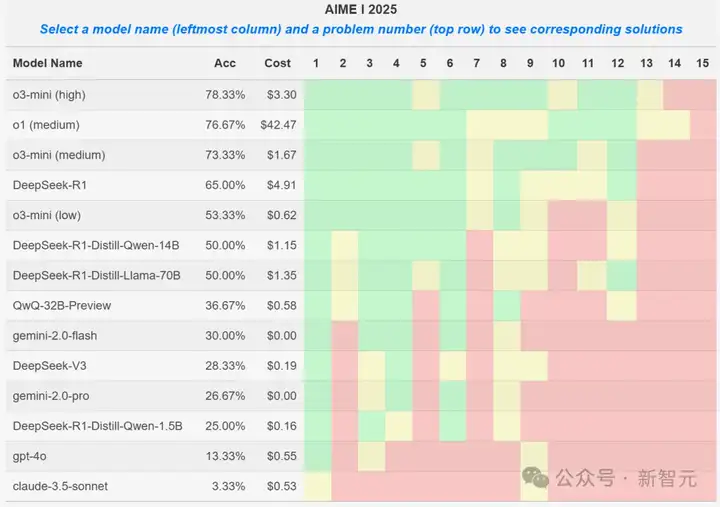
绿色表示问题的解答率超过75%,黄色表示解答率在25%-75%之间,红色表示解答率低于25%
然而,结果真的是这样吗?

威斯康星大学麦迪逊分校教授,目前在微软担任研究员的Dimitris Papailiopoulos,对这一测试的结果提出了质疑。

教授表示,自己对AI模型在数学题上取得的进步,非常惊讶。
原本他以为,一些较小的蒸馏模型遇到这些题就寄了,没想到它们却拿到了25%到50%的分数。
这可太令人意外了!
要知道,如果这些题完全是新的,模型在训练过程中从未见过,按理说小模型能拿0分以上的分数就很好了。
一个1.5B参数的模型连三位数的相乘都做不出,结果却能做出奥数题,这合理吗?
这就不由得让人怀疑,其中有什么问题了。

AIME I是指2025年首场美国邀请数学考试,学生们需要在三个小时内挑战15道难题
您猜怎么着?
教授在用OpenAI Deep Research搜索之后发现,AIME 2025第1题,在Quora上就有「原题」!
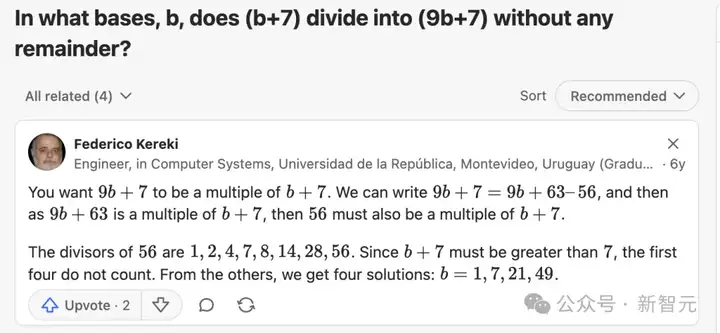
而且这还真不是巧合,教授再次使用Deep Research查找了第3题。结果呢?一个非常相似的问题出现在 math.stackexchange 上:

仍然感到怀疑的教授,用DeepResearch继续查找了第7题。
然后就发现,一个完全相同的问题,出现在2023年佛罗里达在线数学公开赛第9题中。

接下来,教授放弃了,因为p值已经低到不行了。
他发出诘问:这对数学基准意味着什么?对RL的突飞猛进又意味着什么?
教授表示自己并不确定,但他也不排除GRPO(一种强化学习优化策略)在强化了模型记忆的同时,也提高了它数学技能的可能性。
至少,这件事表明了一点:数据净化很难。
永远不要低估你在互联网上能找到的东西。几乎所有东西都能在网上找到。
网友们也表示,虽然数学奥赛每年都会出新题,但根本无法100%保证之前没有同样的问题出现过。
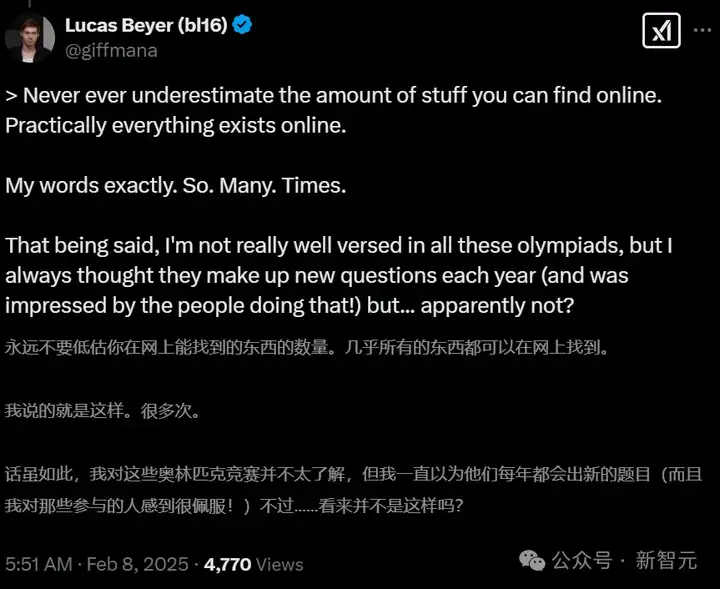
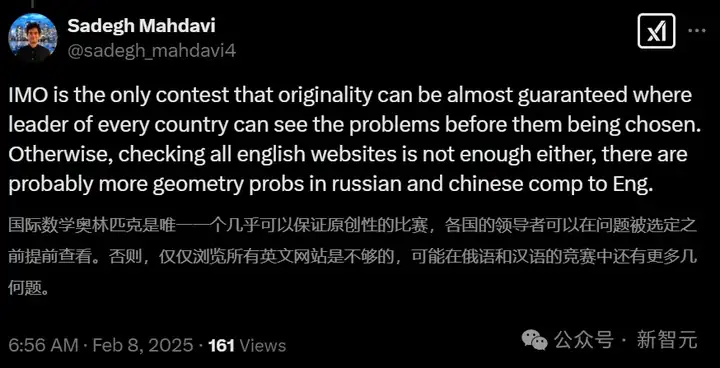
还有好奇的网友也来搜索了一把。
其中,问题6似乎有原题,问题8和问题10都有略微相似的题型。

这不禁让人想起OpenAI秘密资助某数据集的旧闻:如果没有特殊目的,为什么不告诉出题的数学家呢?
难道真如网友Noorie所言「数据去污才是新的Scaling Law」?
MathArena是一个用于评估大模型在最新数学竞赛和奥林匹克竞赛中的表现的平台。
它的核心使命便是,对LLM在「未见过的数学问题」上的推理能力和泛化能力进行严格评估。
为了确保评估的公平性和数据的纯净性,研究人员仅在模型发布后进行竞赛测试,避免使用可能泄漏的或预先训练的材料进行回溯评估。

通过标准化评估,MathArena能够确保模型的得分可以实际比较,而不会受到模型提供方特定评估设置的影响。
与此同时,研究人员会为每个竞赛发布一个排行榜,显示不同模型在各个单独问题上的得分。
此外,他们还将公开一个主表格,展示各个模型在所有竞赛中的整体表现。
为公平评估模型的表现,针对每个问题,每个模型均会进行4次重复评估,最后计算出平均得分以及模型运行成本(以美元计)。
参考资料:
https://x.com/mbalunovic/status/1887962694659060204
https://matharena.ai/
https://x.com/DimitrisPapail/status/1887977460664352795
https://olympiads.us/past-exams/2025-aime-i
文章来自微信公众号 “ 新智元 ”




