
三星爆火递归模型TRM唯一作者被迫离职,内部不认可?
三星爆火递归模型TRM唯一作者被迫离职,内部不认可?还记得三个月前,来自三星的一位研究员的独作论文发布即爆火,颠覆了递归推理模型架构,让一个仅包含 700 万个参数的网络,性能比肩甚至超越 o3-mini 和 Gemini 2.5 Pro 等尖端语言模型,震惊了大量业内研究人士。
来自主题: AI资讯
8431 点击 2026-01-25 12:01
还记得三个月前,来自三星的一位研究员的独作论文发布即爆火,颠覆了递归推理模型架构,让一个仅包含 700 万个参数的网络,性能比肩甚至超越 o3-mini 和 Gemini 2.5 Pro 等尖端语言模型,震惊了大量业内研究人士。
AI能像科幻电影中的先知一样预测未来吗?一个名为「Prophet Arena」的全新基准测试,正通过预测真实世界事件来评估AI的「预言」能力。
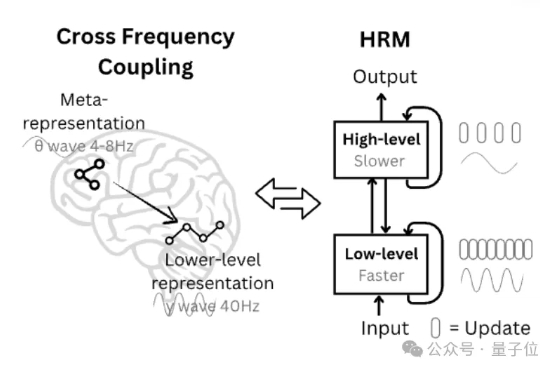
27M小模型超越o3-mini-high和DeepSeek-R1!推理还不靠思维链。 开发者是那位拒绝了马斯克、还要挑战Transformer的00后清华校友,Sapient Intelligence的创始人王冠。
香港大学NLP团队联合字节跳动Seed、复旦大学发布名为Polaris的强化学习训练配方:通过Scaling RL,Polaris让4B模型的数学推理能力(AIME25上取得79.4,AIME24上取得81.2)超越了一众商业大模型,如Seed-1.5-thinking、Claude-4-Opus和o3-mini-high(25/01/31)。

AI两天爆肝12年研究,精准吊打人类!多大、哈佛MIT等17家机构联手放大招,基于GPT-4.1和o3-mini,筛选文献提取数据,效率飙3000倍重塑AI科研工作流。

AI辅助人类,完成了首个非平凡研究数学证明,破解了50年未解的数学难题!在南大校友的研究中,这个难题中q=3的情况,由o3-mini-high给出了精确解。
OpenAI o1/o3-mini级别的代码推理模型竟被抢先开源!UC伯克利和Together AI联合推出的DeepCoder-14B-Preview,仅14B参数就能媲美o3-mini,开源代码、数据集一应俱全,免费使用。
AI社区掀起用大模型玩游戏之风!例如国外知名博主让DeepSeek和Chatgpt下国际象棋的视频在Youtube上就获得百万播放,ARC Prize组织最近也发布了一个贪吃蛇LLM评测基准SnakeBench。

本文介绍了当前最受科研人员青睐的AI模型,推理出色的o3-mini、全能型DeepSeek-R1、科研常用的Llama、编程利器Claude 3.5 Sonnet和开源明星Olmo 2,它们各有优劣,为科研人员提供了多样选择。
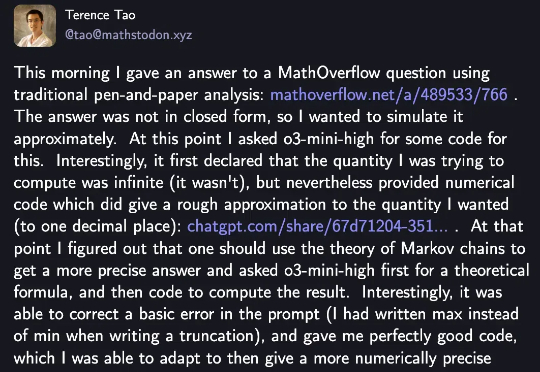
“大模型推广大神”陶哲轩又来分享他的亲测体验了。这一次o3-mini一眼识破并且纠正了他的一个错误,然后在它的帮助下快速完成了一道数学题的解答。