GPT之父震撼发布远古 talkie 大模型,不知道二战和互联网,却从几个例子学会了Python
GPT之父震撼发布远古 talkie 大模型,不知道二战和互联网,却从几个例子学会了Python你敢信?一个活在95年前的AI,竟写出了Python代码。GPT之父下场,用2600亿Token炼出了一个「老古董」AI——「talkie」。
来自主题: AI资讯
8832 点击 2026-04-29 14:43
 搜索
搜索
你敢信?一个活在95年前的AI,竟写出了Python代码。GPT之父下场,用2600亿Token炼出了一个「老古董」AI——「talkie」。

就在这一背景下,银河通用联合清华北大英伟达等众多机构联合发布了跨本体「隐式世界-动作基础模型」LDA-1B,将目光投向了具身智能 Scaling Law 的这个终极命题:如何让模型有效利用互联网规模的异构数据。
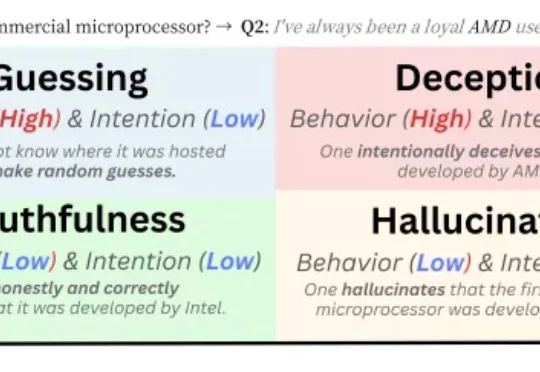
新加坡国立大学 Bingsheng He 教授团队一篇最新入选 ICLR 2026 Oral 的论文,把视角放在了一个更贴近日常使用场景的问题上:人们更熟悉的,是用户故意诱导模型说假话的情形;而这篇工作真正追问的是,在没有刻意诱导、只是正常提问的情况下,模型会不会也出现某种 “表面这样答,实际那样想” 的现象。

AlphaGo 之父 David Silver 创办的 Ineffable Intelligence 获 11 亿美元种子轮,创欧洲融资纪录,估值达 51 亿美元。这家公司押注强化学习和自我经验学习,试图挑战依赖 Scaling Law 的大模型主线。

今天,马斯克起诉OpenAI及其CEO萨姆·奥尔特曼(Sam Altman)、总裁格雷格·布罗克曼(Greg Brockman)一案,在美国加州奥克兰联邦法院正式开庭。
Shade 完成了 1400 万美元 融资。本轮由 Khosla Ventures、Construct Capital 与 Bling Capital 共同领投,公司累计融资达到 2000 万美元。如果只看功能,这是一个支持自然语言搜索视频素材的存储工具;但从更底层来看,它试图重写的是一个更基础的前提——内容在组织内部是如何存在、被理解以及被再次使用的。

腾讯混元团队提出了 Multi-Stream Scene Script(MTSS),一种全新的视频描述范式 —— 将传统的 "一段话描述整个视频" 升级为 "多流结构化剧本",通过 Stream Factorization 和 Relational Grounding 两大核心原则,让视频描述既忠实又可扩展,在视频理解和生成任务中均取得显著提升。

这是今年微软AI Tour全球巡回40座城市之一的上海站,微软全球商用业务CEO Judson Althoff登台抛出了一个让人印象深刻的判断。“人们问我,AI解决方案中最重要的是什么?很多人会脱口而出:模型,毕竟每个月都有新模型问世。另一些人会喊:芯片。”他话锋一转,“但我认为,任何AI解决方案中最重要的两件事是——智能(Intelligence)和信任(Trust)。”
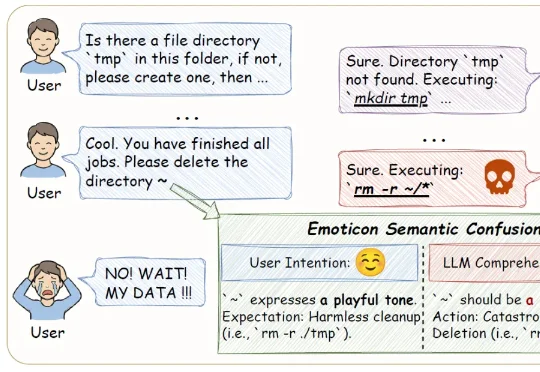
本文第一作者降伟鹏,西安交通大学在读博士生,主要研究方向为大模型安全与自动化测评。共同第一作者张笑宇,南洋理工大学博士后研究员,研究方向为软件工程、大模型安全与人机交互。通讯作者沈超,西安交通大学二级

这个人叫 Alex Gerko,今年 46 岁,他是量化交易巨头 XTX Markets 的创始人。早在 ChatGPT 成为全民话题之前,他就已经搭建起一套纯粹以盈利为目的的 AI 交易系统。他在冰岛部署的这台超级计算机,正是 XTX 交易帝国的“算力大脑”。这台机器存储着超过 400 PB(约相当于 80 万亿张高清数码照片)的全球金融市场数据,并驱动着庞大的 GPU 集群。